群集使用高斯混合模型
本主题介绍使用统计学和机器学习工具箱™函数使用高斯混合模型(GMM)进行聚类集群以及显示在拟合GMM模型时指定可选参数的效果的示例fitgmdist.
高斯混合模型如何聚类数据
高斯混合模型(GMMs)常用于数据聚类。您可以使用gmm来执行这两种操作难的聚类或者软对查询数据进行聚类。
执行难的聚类时,GMM将查询数据点分配给多元正态分量,使分量的后验概率最大化,给定数据。也就是说,给定一个合适的GMM,集群将查询数据分配给产生最高后概率的组件。硬群集团将数据点分配到一个群集。有关如何将GMM拟合到数据的示例,群集使用拟合模型,并估算组件后续概率,请参阅用硬聚类方法聚类高斯混合数据.
此外,您可以使用GMM对数据执行更灵活的集群,称为软(或模糊)集群。软聚类方法为每个聚类的一个数据点分配一个分数。得分的值表示数据点与集群的关联强度。相对于硬聚类方法,软聚类方法是灵活的,因为它们可以将一个数据点分配给多个聚类。当你执行GMM聚类时,得分是后验概率。有关使用GMM的软集群的示例,请参见使用软群集群集高斯混合数据.
GMM集群可以容纳具有不同大小和内部相关结构的集群。因此,在某些应用中,GMM聚类可能比k- eans集群。与许多聚类方法一样,GMM群集要求您在拟合模型之前指定群集的数量。群集数指定GMM中的组件数。
对于gmm,请遵循以下最佳实践:
考虑组件协方差结构。你可以指定对角或全协方差矩阵,以及是否所有的分量都有相同的协方差矩阵。
指定初始条件。期望最大化(EM)算法与GMM算法相吻合。就像在k- emeans聚类算法,EM对初始条件敏感,可能会收敛到本地最佳状态。您可以为参数指定自己的起始值,为数据点指定初始群集分配,也可以随机选择它们,或指定使用k——+ +算法.
实现正规化。例如,如果您有比数据点更多的预测器,那么您可以规范化估计稳定性。
用不同协方差选项和初始条件拟合GMM
此示例探讨了在执行GMM群集时为协方差结构和初始条件指定不同选项的效果。
载入费雪的虹膜数据集。考虑对萼片测量值进行聚类,并使用萼片测量值在二维中可视化数据。
加载fisheriris;X = MEAS(:,1:2);[n,p] = size(x);绘图(x(:,1),x(:,2),“。”,“MarkerSize”15);标题(Fisher' s Iris数据集);包含(“花萼长度(厘米)”);ylabel (萼片宽(cm)的);
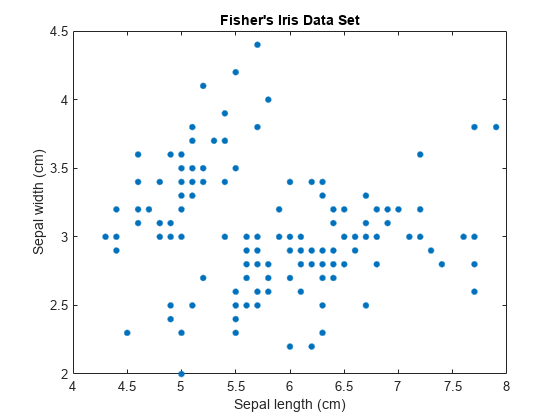
组件数量k在一个GMM中决定了亚种群或集群的数量。在这个图中,很难确定两个、三个或者更多的高斯分量是合适的。GMM的复杂性随着k增加。
指定不同的协方差结构选项
每个高斯分量都有一个协方差矩阵。几何上,协方差结构决定了在聚类上绘制的置信椭球的形状。您可以指定所有分量的协方差矩阵是对角的还是满的,以及所有分量是否具有相同的协方差矩阵。每一种规格组合决定了椭球的形状和方向。
为EM算法指定三个GMM组件和1000个最大迭代。为了再现性,设置随机种子。
提高(3);k = 3;%GMM组件的数量选择= statset ('maxiter',1000);
指定协方差结构选项。
sigma = {'对角线',“全部”};协方差矩阵类型的选项nsigma = numel(sigma);sharedcovariance = {true,false};相同或非相同协方差矩阵的指标SCtext = {“真正的”,'错误的'};nSC =元素个数(SharedCovariance);
创建一个2-D网格,覆盖由极端测量的平面。稍后将使用这个网格,以吸引群集的信心椭圆体。
d = 500;%网格长度x1 = linspace(min(X(:,1))-2, max(X(:,1))+2, d);x2 = linspace(min(X(:,2))-2, max(X(:,2))+2, d);[x1grid, x2grid] = meshgrid (x1, x2);X0 = [x1grid(:) x2grid(:)];
指定以下:
对于协方差结构选项的所有组合,适合具有三个组成部分的GMM。
使用安装的GMM来聚类2-D网格。
获取指定每个置信区的99%概率阈值的分数。本说明书确定椭圆体的主要和次轴的长度。
每个椭球使用相似的颜色作为它的簇。
阈值=√chi2inv (0.99, 2));数= 1;为了我= 1:nSigma为了j = 1:nsc gmfit = fitgmdist(x,k,“CovarianceType”σ{我},...“SharedCovariance”, SharedCovariance {j},'选项'、选择);%安装GMMclusterX =集群(gmfit X);%集群指数mahaldist =玛哈尔(Gmfit,x0);%从每个网格点到每个GMM分量的距离%在每个GMM组件上画椭球,并显示聚类结果。次要情节(2,2,数);h1 = gscatter (X (: 1), X (:, 2), clusterX);持有在为了m = 1:k idx = mahalDist(:,m)<=threshold;颜色= h1(m).颜色*0.75 - 0.5*(h1(m))。颜色- 1);h2 =情节(X0 (idx, 1), X0 (idx, 2),“。”,“颜色”、颜色、“MarkerSize”1);uistack (h2,“底”);结尾情节(gmfit.mu (: 1) gmfit.mu (:, 2),'kx','行宽'2,“MarkerSize”10)标题(sprintf ('Sigma是%s\nSharedCovariance = %s'SCtextσ{我},{j}),'字体大小',8)传奇(H1,{' 1 ','2','3'}) 抓住从Count = Count + 1;结尾结尾
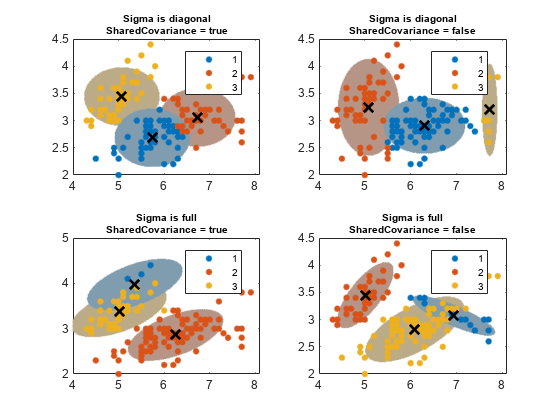
置信区域的概率阈值决定了长轴和短轴的长度,协方差类型决定了轴的方向。注意以下关于协方差矩阵的选项:
对角协方差矩阵表明预测器是不相关的。椭圆的主要和少量轴平行或垂直于x和y轴。该规范将参数总数增加 ,但比完整的协方差规范更简洁。
完整的协方差矩阵允许与椭圆相对于椭圆的方向没有限制的相关预测器x和y轴。每个组件将参数总数增加 ,但捕获预测器之间的相关结构。该规范可能导致过度装备。
共享的协方差矩阵表明所有组件都具有相同的协方差矩阵。所有椭圆均具有相同的尺寸,具有相同的方向。该规范比未共享的规范更加解散,因为参数总数增加了一个组件的协方差参数的数量增加。
非共同的协方差矩阵表示每个分量都有自己的协方差矩阵。所有椭圆的大小和方向可能不同。该规范将参数的数量增加为k倍增组件的协方差参数的数量,但可以捕获组件之间的协方差差异。
该图还显示了这一点集群并不总是保持集群秩序。如果您群集几个适合gmdistribution模型,集群可以为类似的组件分配不同的集群标签。
指定不同的初始条件
对数据拟合GMM的算法对初始条件很敏感。为了说明这一敏感性,拟合如下四种不同的gmm:
对于第一个GMM,将大部分数据点分配给第一个集群。
对于第二个GMM,随机分配数据点到集群。
对于第三个GMM,对数据点进行另一次随机分配到集群。
对于第四种GMM,使用k-means++获取初始集群中心。
initialcond1 = [into(n-8,1);[2;2;2;2];[3;3;3;3];%第一次GMMinitialcond2 = randsample(1:k,n,true);%第二次GMMinitialcond3 = randsample(1:k,n,true);%第三届GMMinitialCond4 ='加';%第四届GMMcluster0 = {initialCond1;initialCond2;initialCond3;initialCond4};
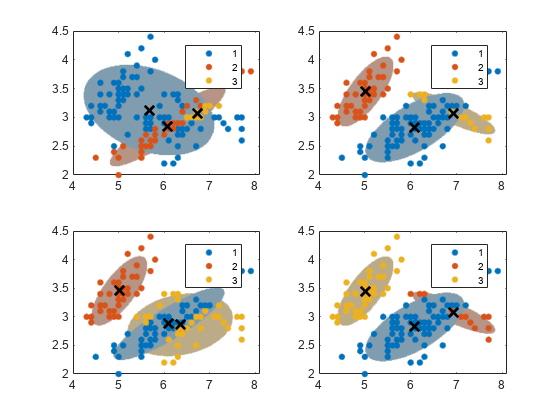
对于所有实例,使用k= 3个分量,未共享和完整的协方差矩阵,相同的初始混合比例,相同的初始协方差矩阵。为了稳定,当你尝试不同的初值集时,增加EM算法的迭代次数。同时,在星团上画出自信椭球。
融合=南(4,1);为了j = 1:4 Gmfit = fitgmdist(x,k,“CovarianceType”,“全部”,...“SharedCovariance”假的,“开始”,cluster0 {j},...'选项'、选择);clusterX =集群(gmfit X);%集群指数mahaldist =玛哈尔(Gmfit,x0);%从每个网格点到每个GMM分量的距离%在每个GMM组件上画椭球,并显示聚类结果。次要情节(2,2,j);h1 = gscatter (X (: 1), X (:, 2), clusterX);%从每个网格点到每个GMM分量的距离持有在;nK =元素个数(独特(clusterX));为了m = 1:nK idx = mahalDist(:,m)<=threshold;= h1(m).Color*0.75 + -0.5*(h1(m))。颜色- 1);h2 =情节(X0 (idx, 1), X0 (idx, 2),“。”,“颜色”、颜色、“MarkerSize”1);uistack (h2,“底”);结尾情节(gmfit.mu (: 1) gmfit.mu (:, 2),'kx','行宽'2,“MarkerSize”10)传说(h1, {' 1 ','2','3'});持有从融合(j)= gmfit.converged;收敛指标结尾
总和(聚合)
ans = 4
所有算法都融合。数据点的每个起始群集分配都会导致不同的拟合集群分配。您可以为名称值对参数指定正整数复制,以指定的次数运行算法。随后,fitgmdist选择产生最大可能性的契合。
什么时候调整
有时,在EM算法的迭代过程中,拟合的协方差矩阵可能会变得病态,这意味着可能性正逃向无穷。如果存在以下一个或多个条件,就会发生此问题:
预测因素比数据点多。
你指定的配件太多了。
变量是高度相关的。
要克服这个问题,可以使用“RegularizationValue”名称-值对的论点。fitgmdist将这个数字加到所有协方差矩阵的对角元素上,以确保所有矩阵都是正定的。正则化可以降低极大似然值。
模型拟合统计数据
在大多数应用程序中,组件的数量k并且适当的协方差结构σ是未知的。一种方法可以通过比较信息标准来调整GMM。两个流行的信息标准是Akaike信息标准(AIC)和贝叶斯信息标准(BIC)。
AIC和BIC都采用最优化的负对数似然,然后用模型中的参数数量(模型复杂性)惩罚它。然而,BIC对复杂性的惩罚比AIC更严厉。因此,AIC倾向于选择可能过拟合的更复杂的模型,而BIC倾向于选择可能过拟合的更简单的模型。一个好的实践是在评估模型时同时考虑这两个标准。AIC或BIC值越低,拟合模型越好。同时,确保你的选择k并且协方差矩阵结构适合您的应用程序。fitgmdist存储适合的AIC和BICgmdistribution在属性中建模对象AIC.和BIC..您可以使用点符号来访问这些属性。有关如何选择适当参数的示例,请参见调谐高斯混合模型.
也可以看看
相关的话题
你也可以从以下列表中选择一个网站:
