通过装袋决策树进行信用评级
这个例子展示了如何构建一个自动化的信用评级工具。
信用风险管理的基本任务之一是确定借款人的信用等级。评级是根据客户的信用等级来对其进行排名的:评级越高意味着客户风险越低;相似的等级意味着相似的风险水平。等级分为两类:信用评级和信用评分。信用评级是一小部分离散的类别,通常用字母标记,如“AAA”,“BB -”等等。信用评分是数字等级,如“640”或“720”。信用等级是监管框架的关键要素之一,例如巴塞尔协议II(见巴塞尔银行监管委员会[3.])。
确定信用等级需要分析借款人的信息。如果借款人是个人,相关信息可能是个人收入、未偿还债务(抵押贷款、信用卡)、家庭规模、居住状况等。对于公司借款人,可以考虑某些财务比率(例如销售额除以总资产)、行业等等。这些关于借款者的信息被称为“碎片”特性或预测.不同的机构使用不同的预测因子,他们也可能有不同的评级类别或评分范围来对客户进行排名。对于向大量潜在借款人提供的相对小额贷款(例如,信用卡),通常使用信用评分,并且对借款人进行评级的过程通常是自动化的。对于中小企业和大型企业的大额贷款,通常使用信用评级,评级过程可能涉及自动算法和专家分析的结合。
有评级机构跟踪公司的信用状况。然而,大多数银行都制定了一种内部方法,为客户分配信用等级。如果客户没有被评级机构评级,内部评级可能是必要的,但即使存在第三方评级,内部评级也可以提供对客户风险状况的补充评估。
这个例子展示了MATLAB®如何帮助信用评级过程的自动化阶段。特别地,这个示例利用了统计和机器学习工具箱™中现成的统计学习工具之一,称为分类算法的分类算法袋装决策树.
本例假设历史信息以数据集的形式提供,其中每个记录包含借款人的特征和分配给它的信用评级。这些评级可能是内部评级,由一个遵循现有政策和程序的委员会分配。或者,评级可能来自评级机构,其评级被用于“启动”一个新的内部信用评级系统。
现有的历史数据是起点,它是用来火车将自动化信用评级的袋装决策树。在统计学学习的词汇中,这种训练过程属于监督式学习.然后使用分类器为新客户分配评级。在实践中,这些自动化或预测在专家组成的信用委员会对评级进行审查之前,评级很可能被视为是试探性的。本例中使用的分类器类型还可以促进这些评级的修订,因为它为预测的评级提供了确定性度量分类分.
在实践中,首先需要训练分类器,然后使用它为新客户分配信用评级,最后还需要配置文件或评估质量或者说是分类器的准确性,这个过程也被称为验证或历史.本例还讨论了一些可用的回测工具。
加载现有信用评级数据
从逗号分隔的文本文件加载历史数据CreditRating_Historical.dat.此示例适用于文本文件,但如果您可以访问Database Toolbox™,则可以直接从数据库加载此信息。
该数据集包含企业客户列表的财务比率、行业部门和信用评级。这是模拟数据,不是真实数据。第一列是客户ID。然后是财务比率的五列。这些比率与Altman的z分数相同(参见Altman [1];也参见Loeffler和Posch [4]参阅相关分析)。
营运资金/总资产(
WC_TA)留存收益/总资产(
RE_TA)息税前收益/总资产(
EBIT_TA)股本市值/总负债帐面价值(
MVE_BVTD)销售额/总资产(
S_TA)
接下来,有一个行业部门标签,一个整数值,范围为1来12.最后一列是分配给客户的信用评级。
将数据加载到表格数组中。
贷方=可读的(“CreditRating_Historical.dat”);
将特征复制到一个矩阵中X,和相应的类,评级,成一个向量Y.这不是必需的步骤,因为您可以直接从数据集或表格数组,但是这个例子是为了简化下面的一些重复函数调用。
存储在矩阵中的特征X分别是五大财务比率,以及行业标签。行业是一个分类变量,名义上的事实上,因为行业部门没有秩序。反应变量,信用评级,也是分类的,尽管这是一个序数变量,因为根据定义,评级意味着a排名的良好信誉。这个例子使用变量as is来训练分类器。该变量被复制到有序数组因为这样输出就会按照评级的自然顺序出现,更容易阅读。的定义中作为第三个参数传递的单元格数组建立了评级的顺序Y.信用评级还可以映射为数值,这对于尝试其他方法来分析数据(例如,回归)是有用的。我们总是建议在实践中尝试不同的方法。
X = [creditDS.]WC_TAcreditDS。RE_TAcreditDS。EBIT_TAcreditDS。MVE_BVTD...creditDS。S_TAcreditDS。行业];Y =序数(信用等级);
使用预测器X以及回应Y为了适合一种特殊类型的分类集合,称为袋装决策树.在这里,“Bagging”表示“引导聚合”。该方法包括生成一些子样本,或引导副本,从数据集中。这些子样本是随机生成的,从数据集中的客户列表中进行替换抽样。对于每个副本,都会生成一棵决策树。每个决策树都是一个经过训练的分类器,可以单独用于对新客户进行分类。不过,对于从两个不同的引导副本中生长出来的两棵树的预测可能会有所不同。的合奏聚合所有决策树的预测为所有的自举副本生长。如果大多数树预测一个新客户的特定类别,则可以合理地认为该预测比任何单独的树的预测更健壮。此外,如果一个不同的类别是由更小的一组树预测的,这些信息也是有用的。事实上,预测不同类别的树的比例是预测的基础分类的分数集合在分类新数据时报告的。
建造装袋树
构建分类集合的第一步是为每棵树找到一个合适的叶子大小;这里的示例尝试的大小1,5,10.(有关更多信息,请参阅统计和机器学习工具箱文档TreeBagger)。从少量的树木开始,25只是,因为你主要是想比较不同叶大小的分类误差的初始趋势。为了可再现性和公平比较,每次构建分类器时重新初始化随机数生成器,它用于从数据中进行替换抽样。
Leaf = [1 5 10];nTrees = 25;rng (9876“旋风”);savedRng = rng;保存当前RNG设置颜色=“bgr”;为Ii = 1:长度(叶)重新初始化随机数生成器,以便%随机样本对于每个叶片大小都是相同的rng (savedRng)为每个叶片大小创建袋装决策树,并绘制袋外图%错误'oobError'b = TreeBagger(nTrees,X,Y,“OOBPrediction”,“上”,...“CategoricalPredictors”6...“MinLeafSize”、叶(ii));情节(oobError (b)、颜色(ii))在结束包含(“已生长树木的数目”) ylabel (“包外分类错误”)({传奇' 1 ',“5”,“十”},“位置”,“东北”)标题(“不同叶片大小的分类错误”)举行从

三种叶片大小选项的误差是相当的。因此,使用的叶大小为10,因为它会导致更精简的树和更有效的计算。
请注意,您不必将数据分割为培训而且测验子集。这是内部完成的,它隐含在该方法的抽样过程中。在每次bootstrap迭代中,bootstrap副本是训练集,任何被遗漏的客户(“out-of-bag”)都被用作测试点,以估计上面报告的out-of-bag分类错误。
接下来,找出是否所有的特征都对分类器的准确性很重要。通过打开功能的重要性测量(OOBPredictorImportance),并将结果绘制成图,以直观地找出最重要的特征。现在尝试更大数量的树并存储分类错误,以便下面进行进一步比较。
nTrees = 50;叶子= 10;rng (savedRng);b = TreeBagger(nTrees,X,Y,“OOBPredictorImportance”,“上”,...“CategoricalPredictors”6...“MinLeafSize”、叶);酒吧(b.OOBPermutedPredictorDeltaError)包含(的数字特征) ylabel (“外袋功能的重要性”)标题(“特征重要性结果”)

oobErrorFullX = oobError(b);
特性2,4而且6从其他人中脱颖而出。功能4、股本市值/总负债帐面价值(MVE_BVTD),是该数据集最重要的预测因子。这一比率与结构模型(如默顿模型)中的信誉度预测因子密切相关[5,在该方法中,将公司的股本价值与未偿债务进行比较,以确定违约概率。
有关行业部门的信息,特色6(行业),对于这个数据集来说,它也相对比其他变量更重要。
虽然不像MVE_BVTD、特性2、留存收益/总资产(RE_TA),从其他作品中脱颖而出。留存收益和公司的年龄之间存在相关性(一般来说,公司存在的时间越长,它可以积累的收益就越多),反过来,公司的年龄与它的信誉相关(历史悠久的公司往往更有可能在艰难时期生存下来)。
只使用预测器拟合一个新的分类集合RE_TA,MVE_BVTD,行业.将其分类错误与使用所有特征的前一个分类器进行比较。
X = [creditDS.]RE_TAcreditDS。MVE_BVTDcreditDS。行业];rng(savedRng) b = TreeBagger(nTrees,X,Y,“OOBPrediction”,“上”,...“CategoricalPredictors”3,...“MinLeafSize”、叶);oobErrorX246 = oobError(b);情节(oobErrorFullX“b”)举行在情节(oobErrorX246“r”)包含(“已生长树木的数目”) ylabel (“包外分类错误”)({传奇的所有功能,“特征2,4,6”},“位置”,“东北”)标题(“不同预测因子集的分类错误”)举行从

当你移除重要性相对较低的特征(1,3.,5),因此您将使用更精简的分类集合进行预测。
这个例子从一个只有六个特征的集合开始,并使用分类器的特征重要性度量和袋外分类错误作为筛选出三个变量的标准。当初始的潜在预测器集包含数十个变量时,特征选择可能是一个耗时的过程。除了这里使用的工具(变量重要性和袋外错误的“可视化”比较),统计和机器学习工具箱中的其他变量选择工具对这些类型的分析也有帮助。然而,最终,一个成功的特征选择过程需要定量工具和分析师判断的结合。
例如,这里使用的可变重要性度量是一种排名机制,通过测量当特征值随机排列时分类器的预测准确性恶化的程度来估计特征的相对影响。其思想是,当所讨论的特征对分类器的预测能力几乎没有增加时,使用改变的(在这种情况下是打乱的)值不应该影响分类结果。另一方面,相关信息不能在不降低预测的情况下随机交换。现在,如果两个高度相关的特征是重要的,它们都将在分析中排名靠前。在这种情况下,保留其中一个特征就足以实现准确的分类,但仅从排名结果无法得知这一点。你必须单独检查相关性,或者使用专家的判断。也就是说,像可变重要性或sequentialfs可以极大地帮助特征选择,但分析师的判断是这个过程中的关键部分。
此时,可以保存分类器(例如,保存分类器。垫b),以便在将来的会话中加载(负荷分类器)对新客户进行分类。为了提高效率,建议在训练过程结束后保持分类器的紧凑版本。
B =紧凑(B);
新数据分类
使用先前构造的分类集合将信用评级分配给新客户。由于也需要定期审查现有客户的评级,特别是当他们的财务信息发生重大变化时,数据集还可能包含正在审查的现有客户列表。首先加载新数据。
newDS = readtable(“CreditRating_NewCompanies.dat”);
要预测此新数据的信用评级,请调用预测方法。该方法返回两个参数,预测的类别和分类分数。您当然希望获得两个输出参数,因为分类分数包含关于预测评级的确定程度的信息。你可以复制变量RE_TA,MVE_BVTD而且行业变成一个矩阵X和以前一样,但因为你只会打一个电话给预测,您可以跳过此步骤并使用newDS直接。
[predClass,classifScore] = predict(b,[newDS.]RE_TA newDS。MVE_BVTDnewDS.行业]);
此时,您可以创建一个报告。这里的示例仅在屏幕上显示前三个客户的一个小报告,用于演示,但是MATLAB部署工具可以极大地改进这里的工作流程。例如,信用分析师可以使用网络浏览器远程运行这种分类,并获得报告,甚至不需要在桌面上安装MATLAB。
为I = 1:3 fprintf(“客户% d: \ n”newDS.ID(我));流(' RE/TA = %5.2f\n'newDS.RE_TA(我));流(' MVE/BVTD = %5.2f\n'newDS.MVE_BVTD(我));流(' Industry = %2d\n'newDS.Industry(我));流('预测评级:%s\n'我,predClass {});流(’分类分数:\n’);为j = 1:length(b.ClassNames)如果(classifScore (i, j) > 0)流(' %s: %5.4f \n', b.ClassNames {j}, classifScore (i, j));结束结束结束
60644年客户:
Re / ta = 0.22
Mve / bvtd = 2.40
工业= 6
预测评级:AA
分类分数:
A: 0.2349 aa: 0.7519 aaa: 0.0011 BBB: 0.0121
33083年客户:
Re / ta = 0.24
Mve / bvtd = 1.51
工业= 4
预测等级:BBB
分类分数:
A: 0.1060 BBB: 0.8940
63830年客户:
Re / ta = 0.18
Mve / bvtd = 1.69
工业= 7
预测等级:A
分类分数:
A: 0.6305 aa: 0.0172 aaa: 0.0010 BBB: 0.3513
保持预测评级和相应分数的记录对于分类器质量的定期评估是有用的。可以将此信息存储在表格数组predDS.
classnames = b.ClassNames;predDS = [table(newDS.ID,predClass),array2table(classifScore)];predDS.Properties.VariableNames = [{“ID”}, {“PredRating”},一会');
例如,可以将此信息保存到以逗号分隔的文本文件中PredictedRatings.dat使用命令
writetable (predDS PredictedRatings.dat);
或使用“数据库工具箱”直接写入数据库。
回溯测试:分析分类过程
验证或历史是分析或评估信用评级质量的过程。有许多与此任务相关的不同措施和测试(例如,见巴塞尔银行监管委员会[2])。在这里,这个例子主要关注以下两个问题:
与实际收视率相比,预测的收视率有多准确?在这里,“预测评级”指的是从自动分类过程中获得的评级,而“实际评级”指的是由信用委员会分配的评级,该委员会将预测评级及其分类分数,以及新闻和经济状况等其他信息结合在一起,以确定最终评级。
根据客户的信用度,实际评级对他们的评级有多高?这是在事后例如,一年后,当知道哪些公司在这一年违约时,进行分析。
该文件CreditRating_ExPost.dat包含前一节中考虑的相同公司的“后续”数据。它包含了委员会分配给这些公司的实际评级,以及一个“违约标志”,表明相应的公司是否在评级过程的一年内违约1)或否(如果0).
exPostDS = readtable(“CreditRating_ExPost.dat”);
比较预测收视率和实际收视率。
训练自动分类器的基本原理是加快信贷委员会的工作。预测的收视率越准确,委员会花在审查预测收视率上的时间就越少。因此,可以想象,委员会希望定期检查预测评级与他们分配的最终评级的匹配程度,并建议重新训练自动分类器(例如,可能包括新特征),如果不匹配似乎令人担忧。
您可以使用的第一个比较预测和实际评分的工具是混淆矩阵,可以在统计和机器学习工具箱中找到:
C = confusionchart(exPostDS.Rating,predDS.PredRating);sortClasses (C, {“AAA”“AA”“一个”“BBB”“BB”“B”“CCC”})

行对应实际评级,列对应预测评级。位置上的量(i, j)在混淆矩阵中表示有多少客户收到了实际的评级我并被预测为评级j.例如,位置(2)告诉我们有多少客户得到了评级“一个”信用委员会,但被预测为“AA”自动分类器。你也可以用百分比来表示这个矩阵。通过具有相同真实评级的观察数将每个值归一化。
C.Normalization =“row-normalized”;

预测值和实际值之间的良好一致性将导致主对角线上的值支配一行中的其他值,理想情况下接近1.在这种情况下,您实际上可以看到一个重要的分歧“B”,因为大约有一半的客户被评为“B”被信贷委员会预测为“BB”由自动分类器。另一方面,很高兴看到评级在大多数情况下最多相差一个档次,唯一的例外是“BBB”.
混淆矩阵也可以用来比较机构分配的内部评级与第三方评级;实践中经常这样做。
对于每个特定的评级,您可以计算预测和实际评级之间的一致性的另一种度量。你可以建立一个受试者工作特征(ROC)曲线检查曲线下面积(AUC)通过使用rocmetrics对象。rocmetrics使用实际评分(与之比较的标准)和“BBB”分级分数由自动化过程确定。
rocObj1 = rocmetrics(exPostDS.Rating,predDS.BBB,“BBB”);
绘制评分的ROC曲线“BBB”通过使用情节的函数rocmetrics.
情节(rocObj1)

这里解释一下中华民国是如何建造的。回想一下,对于每个客户,自动分类器为每个信用评级返回一个分类分数,特别是为“BBB”,这可以解释为该特定客户应该被评级的可能性有多大“BBB”.为了建立ROC曲线,你需要改变分类阈值.也就是说,将客户划分为“BBB”.换句话说,如果阈值是t,你只把客户分类为“BBB”如果他们的“BBB”得分大于或等于t.例如,假设有一家公司XYZ有一个“BBB”得分0.87。如果实际的评级XYZ(资料载于exPostDS。评级)是“BBB”,然后XYZ会被正确地归类为“BBB”对于任何高达0.87的阈值。这是一个真阳性,它会增加所谓的灵敏度分类器的。对于任何大于0.87的阈值,该公司将不会收到“BBB”评级,你会有一个假阴性的情况。为了完成描述,现在假设XYZ的实际评级为“BB”.那么它将被正确地拒绝为a“BBB”对于阈值大于0.87的,变为真正的负,从而增加了所谓的特异性分类器的。然而,对于高达0.87的阈值,它将变成一个假阳性(它将被归类为“BBB”,当它实际上是“BB”).ROC曲线是通过绘制真阳性(敏感性)与假阳性(1-特异性)的比例来构建的,因为阈值从0来1.
AUC,顾名思义,是ROC曲线下的面积。AUC越接近1,分类器越准确(一个完美的分类器的AUC为1).在这个例子中,AUC似乎足够高,但它将由委员会来决定哪个等级的AUC应该触发改进自动分类器的建议。
比较下一年的实际评级和违约情况。
用于评估信用评级中隐含的客户排名的常用工具是累积精度剖面(CAP),以及相关的精度比衡量。其目的是衡量所分配的信用评级与次年观察到的违约数量之间的关系。人们会认为,评级等级越高,违约现象就越少。如果所有评级的违约率都是一样的,那么评级系统就与一个幼稚(而且无用)的分类系统没有什么不同,在这个分类系统中,客户被随机分配一个评级,与他们的信誉无关。
这一点不难看出rocmetrics也可以用来构建CAP。与之比较的标准不是像以前一样的评级,而是从CreditRating_ExPost.dat文件。您使用的分数是一个“虚拟分数”,它表明评级列表中隐含的信用价值排名。虚拟分数只需要满足更好的评级得到更低的虚拟分数(他们“不太可能有一个默认标志1),并且任何两个评分相同的客户都会得到相同的虚拟分数。当然,违约概率可以作为分数,但这里没有违约概率,实际上不需要估计违约概率来构建CAP,因为你没有验证违约概率。这个例子用这个工具评估的是评分的好坏排名客户根据他们的信誉。
通常,所考虑的评级系统的CAP与“完美评级系统”的CAP一起绘制。后者是一个假设的信用评级系统,其中最低评级包括所有违约者,不包括其他客户。这条完美曲线下的面积是评级系统所能达到的最大AUC。根据惯例,调整cap的AUC以减去天真的系统的CAP,即随机分配评级给客户的系统的CAP。朴素系统的CAP只是一条从原点到(1,1),其AUC为0.5.的精度比然后定义为调整后的AUC(考虑系统的AUC减去天真系统的AUC)与最大精度(完美系统的AUC减去天真系统的AUC)的比值。
ratingsList = {“AAA”“AA”“一个”“BBB”“BB”“B”“CCC”};Nratings =长度(ratingsList);= 1/(Nratings+1);dummyRank = linspace(dummyDelta,1-dummyDelta,Nratings)';D = exPostDS.Def_tplus1;fracTotDef = sum(D)/length(D);maxAcc = 0.5 - 0.5 * fracTotDef;R = double(ordinal(exPostDS.Rating,[],ratingsList));S = dummyRank(R);rocObj2 = rocmetrics(D,S,1); xVal = rocObj2.Metrics.FalsePositiveRate; yVal = rocObj2.Metrics.TruePositiveRate; auc = rocObj2.AUC; accRatio = (auc-0.5)/maxAcc; fprintf('实际评级的正确率:%5.3f\n', accRatio);
实际评级的准确率:0.850
xPerfect(1) = 0;xPerfect(2) = fracTotDef;xPerfect(3) = 1;yPerfect(1) = 0;yPerfect(2) = 1;yPerfect(3) = 1;xNaive(1) = 0;xNaive(2) = 1;yNaive(1) = 0;yNaive(2) = 1; plot(xPerfect,yPerfect,“——k”xVal yVal,“b”xNaive yNaive,“同意”)包含(“所有公司的一小部分”) ylabel (“违约公司的比例”)标题(“累积准确度档案”)({传奇“完美的”,“实际”,“天真的”},“位置”,“东南”)文本(xVal (2) + 0.01, yVal -0.01 (2),“CCC”)文本(xVal (3) + 0.01, yVal -0.02 (3),“B”)文本(xVal (4) + 0.01, yVal -0.03 (4),“BB”)

阅读CAP信息的关键是在图中标记的“扭结”中进行评级“CCC”,“B”,“BB”.例如,第二个扭结与第二低的评级有关,“B”,并位于(0.097,0.714).这意味着9.7%的客户被排名“B”或更低,占所观察到违约的71.4%。
一般来说,准确度比应被视为一个相对的,而不是一个绝对的测量。例如,您可以在同一图中添加预测评级的CAP,并计算其准确率,以将其与实际评级的准确率进行比较。
Rpred = double(ordinal(predDS.PredRating,[],ratingsList));Spred = dummyRank(Rpred);rocObj3 = rocmetrics(D,Spred,1);xValPred = rocObj3.Metrics.FalsePositiveRate;yValPred = rocObj3.Metrics.TruePositiveRate;aucPred = rocObj3.AUC;accRatioPred = (aucPred-0.5)/maxAcc;流('预测评级的准确率:%5.3f\n', accRatioPred);
预测评级的准确率:0.811
情节(xPerfect yPerfect,“——k”xVal yVal,“b”xNaive yNaive,“同意”,...xValPred yValPred,“:r”)包含(“所有公司的一小部分”) ylabel (“违约公司的比例”)标题(“累积准确度档案”)({传奇“完美的”,“实际”,“天真的”,“预测”},“位置”,“东南”)
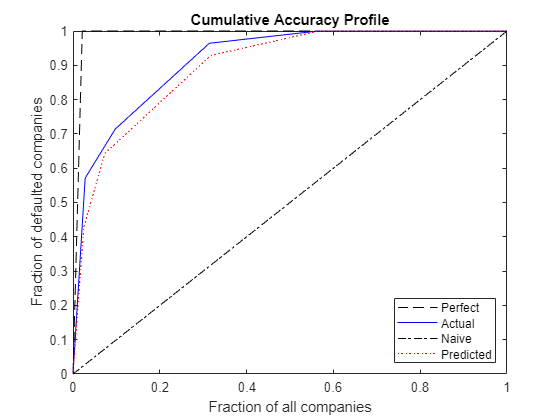
预测评级的正确率较小,其CAP大多低于实际评级的CAP。这是合理的,因为实际的评级是由信用委员会分配的,并考虑到预测的评级而且额外的信息对调整评级很重要。
最后的评论
除了袋装决策树,MATLAB还提供了广泛的机器学习工具,可用于信用评级。在统计和机器学习工具箱中,您可以找到分类工具,如判别分析和朴素贝叶斯分类器。MATLAB还提供了深度学习工具箱™。此外,数据库工具箱和MATLAB部署工具可以为您提供更大的灵活性,使您可以根据自己的喜好和需求调整这里提供的工作流。
这里没有计算违约概率。对于信用评级,违约概率通常是根据信用评级迁移历史计算的。看到transprob(金融工具箱)金融工具箱™中的参考页以获取更多信息。
参考书目
[1]阿尔特曼,E。财务比率、判别分析与企业破产预测金融杂志.第23卷第4期(1968年9月),第589-609页。
[2]巴塞尔银行监管委员会。《内部评级系统有效性研究》国际清算银行(BIS),工作文件第14号,修订本,2005年5月。可以在:https://www.bis.org/publ/bcbs_wp14.htm.
[3]巴塞尔银行监管委员会。《资本计量和资本标准的国际趋同:修订框架》国际清算银行(BIS),综合版,2006年6月。可以在:https://www.bis.org/publ/bcbsca.htm.
[4] G.吕弗勒和P. N.波施。利用Excel和VBA建立信用风险模型.英格兰西苏塞克斯:威利金融,2007年。
默顿,R。《论公司债务定价:利率的风险结构》金融杂志.第29卷第2期(1974年5月),第449-70页。
您也可以从以下列表中选择一个网站: