使用PCA分析美国城市的生活质量
这个例子展示了如何执行加权主成分分析和解释结果。
加载示例数据
加载示例数据。9个不同指标的数据包括评级在329年美国城市生活的质量。这些都是气候、住房、健康、犯罪、交通、教育、艺术、娱乐、和经济学。对于每一个类别,更高的评级是更好的。例如,一个更高的评级犯罪意味着犯罪率较低。
显示类别变量。
负载城市类别
类别=9 x14 char数组“气候”“住房”“健康”“犯罪”“运输”“教育”“艺术”“娱乐”“经济学”
在总,城市数据集包含三个变量:
类别,一个字符矩阵包含索引的名称的名字包含329个城市的名字,字符矩阵评级与329年的数据矩阵行9列
图数据
做一个箱线图的分布评级数据。
图()箱线图(评级,“定位”,“水平”,“标签”、类别)

有更多的变化在艺术和住房的评级比评级的犯罪和气候。
检查两两相关
检查变量之间的两两相关。
C = corr(评级,评级);
一些变量之间的相关性高达0.85。主成分分析构造独立的新变量是原始变量的线性组合。
计算主成分
当所有变量在同一个单位,它是适当的为原始数据计算主成分。当变量在不同的单位和不同列的方差的差异是巨大的(在这种情况下),扩展数据或使用的权重往往是更可取的。
执行主成分分析采用方差倒数的评级作为权重。
w = 1. / var(评级);[wcoeff,分数,潜伏,tsquared解释]= pca(评级,…“VariableWeights”,w);
或者说:
[wcoeff,分数,潜伏,tsquared解释]= pca(评级,…“VariableWeights”,“方差”);
下面的部分解释五项输出主成分分析。
分量系数
第一个输出wcoeff包含主分量的系数。
前三个主成分系数向量:
c3 = wcoeff (: 1:3)
c3 =9×3103×0.0249 -0.0263 -0.0834 0.8504 -0.5978 -0.4965 0.4616 0.3004 -0.0073 0.1005 -0.1269 0.0661 0.5096 0.2606 0.2124 0.0883 0.1551 0.0737 2.1496 0.9043 -0.1229 0.2649 -0.3106 -0.0411 0.1469 -0.5111 0.6586
这些系数加权,因此系数矩阵不是正交。
变换系数
变换系数,这样他们是正交的。
coefforth =诊断接头(std(评级))\ wcoeff;
请注意,如果您使用一个权重向量,w,同时进行主成分分析,然后
coefforth =诊断接头(sqrt (w)) * wcoeff;
检查系数
现在的转换系数是正交的。
我= coefforth ' * coefforth;我(1:3,1:3)
ans =3×31.0000 -0.0000 -0.0000 -0.0000 1.0000 -0.0000 -0.0000 -0.0000 1.0000
组件的分数
第二个输出分数包含原始数据的坐标在新的坐标系统定义的主要组件。的分数矩阵是相同的大小作为输入数据矩阵。您还可以获得分数使用正交系数和标准化的组件评级如下。
* coefforth cscores = zscore(评级);
cscores和分数是相同的矩阵。
情节部分分数
创建一个块的前两列分数。
图绘制(分数(:1),得分(:,2),“+”)包含(第一主成分的)ylabel (第二主成分的)
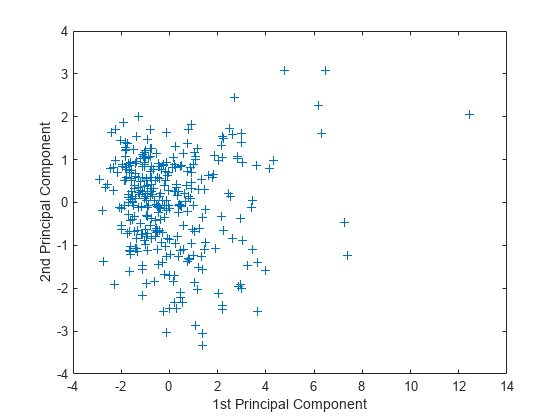
这图显示了集中和扩大评级数据投射到前两个主成分。主成分分析计算分数的意思是零。
探索情节交互
注意偏远点的一半的阴谋。你可以图形化识别这些点如下。
gname
移动光标时,情节并单击一次靠近右边的7分。这个标签的点的行数据如下图所示。
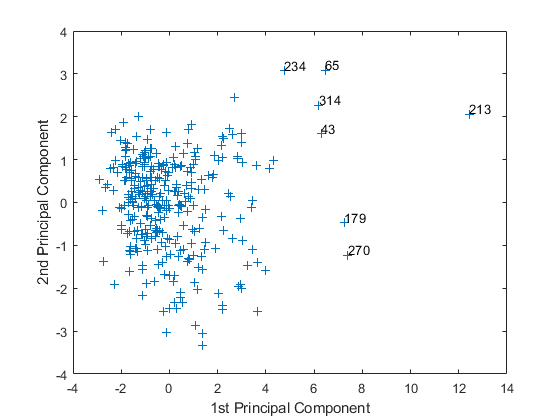
后标记点,出版社返回。
提取观测的名字
创建一个索引变量包含的行数选择的所有城市,让城市的名称。
地铁= [43 65 179 213 234 270 314];名(地铁:)
ans =7 x43 char数组“波士顿”的芝加哥,洛杉矶、长滩、CA的“纽约,纽约”“费城,PA-NJ”“旧金山”“华盛顿,DC-MD-VA”
这些标记的城市在美国一些最大的人口中心,他们显得更加极端的比剩下的数据。
组件差异
第三输出潜在的是一个向量包含相应的主成分的方差解释。每一列的分数有一个样本方差等于相应的行潜在的。
潜在的
潜在的=9×13.4083 1.2140 1.1415 0.9209 0.7533 0.6306 0.4930 0.3180 0.1204
百分比方差解释
第五个输出解释包含百分比是一个矢量方差解释相应的主成分。
解释
解释了=9×137.8699 13.4886 12.6831 10.2324 8.3698 7.0062 5.4783 3.5338 1.3378
创建小石子的阴谋
做一个小石子的情节变化百分比解释为每个主成分。
图帕累托(解释)包含(主成分的)ylabel (的方差解释(%))
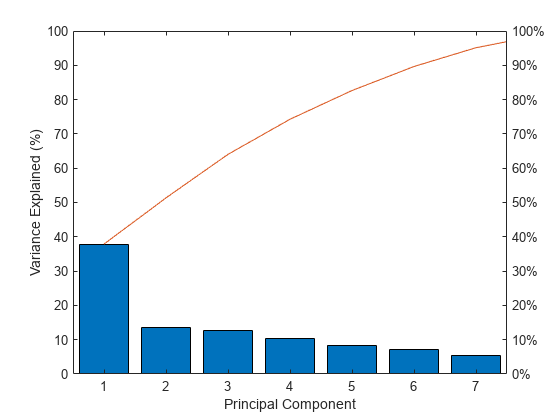
这小石子图只显示第一个七(而不是总9)组件解释总方差的95%。唯一清晰的中断的方差占第一和第二组件之间的每个组件都是。然而,第一个组件本身只有不到40%的方差解释道,所以可能需要多个组件。您可以看到,前三个主成分解释大约三分之二的总变异性标准化的评级,这可能是一个合理的方式来减少维度。
霍特林的丁字尺统计
最后的输出主成分分析是tsquared霍特林的
,多元的统计测量距离的观测数据集的中心。这是一个分析的方法找到最极端点的数据。
[st2,指数]=排序(tsquared,“下”);%按照降序排列极端=指数(1);名称(极端,:)
ans =“纽约,纽约”
纽约的评级是最遥远的美国城市的平均水平。
可视化的结果
可视化两个正交的主成分系数为每个变量和每个观测的主成分得分在一个阴谋。
图biplot (coefforth (:, 1:2),“分数”分数(:1:2),“Varlabels”、类别)轴([-。0.6 - 26日。51 .51]);
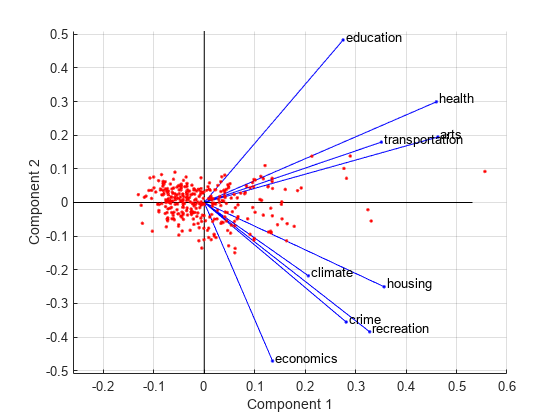
所有九个变量由一个向量,表示在这个biplot和矢量的方向和长度表明每个变量对两个主要组件的阴谋。例如,第一主成分,在横轴上,积极为所有九个变量系数。这就是为什么九向量被定向到正确的一半的阴谋。最大的在第一主成分系数是第三和第七元素,对应变量健康和艺术。
第二主成分,在纵轴上,有积极系数为变量教育,健康,艺术,运输剩下的五个变量,负系数。这表明第二个组件之间的区分城市高为第一组变量值和低的第二,和城市的相反。
变量标签在这个图有点拥挤。你可以排除VarLabels名称-值参数时情节,或选择并拖动标签的一些更好的职位使用编辑绘图工具从图窗口工具栏。
这个二维biplot还包括一个为每个329年观察,与坐标指示每个观察两个主成分的得分的阴谋。例如,点左边缘附近的这个情节有第一主成分得分最低。点是扩展的最大得分值和最大长度系数,所以只有他们的相对位置可以确定的阴谋。
你可以在情节通过选择识别项工具>数据提示在图窗口。通过点击一个变量(向量),你可以阅读的变量标签和每个主成分系数。通过点击一个观察(点),你可以阅读观察名称和每个主成分的得分。您可以指定“ObsLabels”,名字显示的名称而不是观察数字观测数据光标显示。
创建三维Biplot。
你也可以做一个在三维空间中biplot。
图biplot (coefforth (: 1:3),“分数”分数(:1:3),“ObsLabels”、名称)轴([-。0.8 - 26日。51 .51 -。61 .81点)视图([30 40])
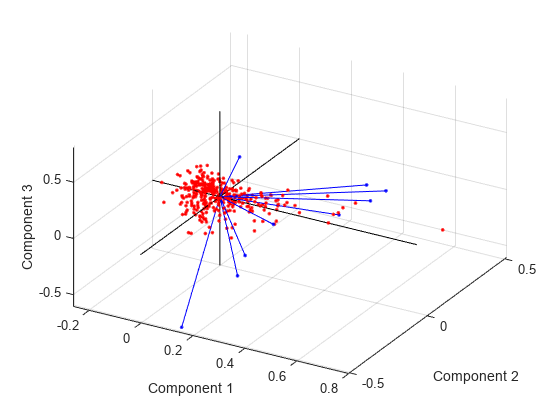
这张图是有用的,如果前两个主坐标不解释方差的足够数据。你也可以旋转图从不同角度看到它通过选择工具>三维旋转。
另请参阅
主成分分析|pcacov|pcares|车牌提取|箱线图|biplot