主要内容
tsne
t-Distributed随机邻居嵌入
描述
例子
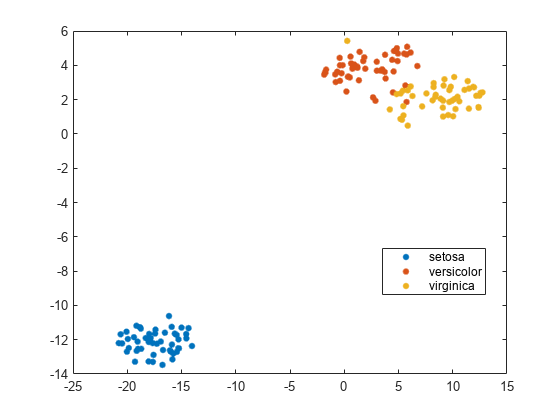
可视化费舍尔虹膜数据
费舍尔虹膜数据集有四维测量的虹膜,和相应的分类到物种。使用可视化数据通过减少维度tsne。
负载fisheririsrng默认的%的再现性Y = tsne(量);gscatter (Y (: 1), Y(:, 2),物种)
比较距离度量
使用各种距离指标,试图获得一个更好的物种之间在费舍尔虹膜数据分离。
负载fisheririsrng (“默认”)%的再现性Y = tsne(量,“算法”,“准确”,“距离”,“mahalanobis”);次要情节(2,2,1)gscatter (Y (: 1), Y(:, 2),物种)标题(“Mahalanobis”)提高(“默认”)%对公平的比较Y = tsne(量,“算法”,“准确”,“距离”,的余弦);次要情节(2 2 2)gscatter (Y (: 1), Y(:, 2),物种)标题(的余弦)提高(“默认”)%对公平的比较Y = tsne(量,“算法”,“准确”,“距离”,“chebychev”);次要情节(2,2,3)gscatter (Y (: 1), Y(:, 2),物种)标题(“Chebychev”)提高(“默认”)%对公平的比较Y = tsne(量,“算法”,“准确”,“距离”,“欧几里得”);次要情节(2,2,4)gscatter (Y (: 1), Y(:, 2),物种)标题(“欧几里得”)
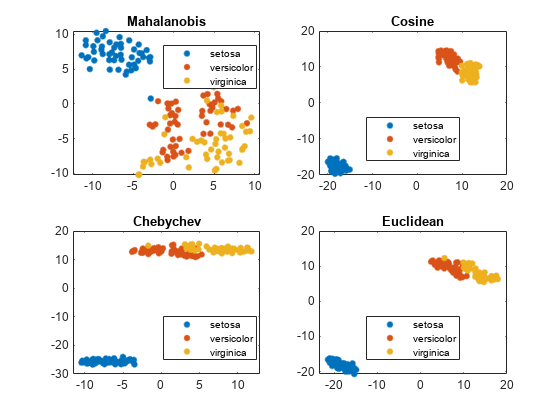
在这种情况下,余弦、Chebychev和欧氏距离度量提供相当不错的集群分离。但距离度量并没有给出很好的分离。
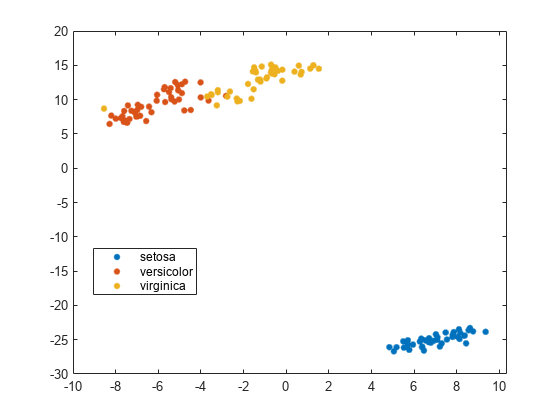
阴谋的结果南输入数据
tsne删除输入包含任何数据行南条目。因此,您必须删除任何行策划之前从你的分类数据。
例如,改变一些随机费舍尔虹膜数据条目南。
负载fisheririsrng默认的%的再现性量(兰德(大小(量))< 0.05)=南;
将四维数据嵌入到二维tsne。
Y = tsne(量,“算法”,“准确”);
警告:行南缺失值X或“则”的值将被去除。
确定从嵌入中消灭了多少行。
长度(物种)长度(Y)
ans = 22
准备策划结果的行定位量没有南值。
goodrows =没有(任何(isnan(量),2));
绘制结果只使用的行物种对应于行量没有南值。
gscatter (Y (: 1), Y(:, 2),物种(goodrows))
比较t-SNE损失
发现费舍尔的2 d和3 d嵌入的虹膜数据,并比较每个嵌入的损失。很可能失去3 d嵌入较低,因为这个嵌入有更多的自由来匹配原始数据。
负载fisheririsrng默认的%的再现性(Y,亏损)= tsne(量,“算法”,“准确”);rng默认的%对公平的比较(Y2, loss2) = tsne(量,“算法”,“准确”,“NumDimensions”3);流(“二维嵌入损失% g, 3 d嵌入% g。\ n损失”、损失、loss2)
二维嵌入损失0.124191,0.0990884和3 d嵌入有损失。
正如所料,3 d嵌入有较低的损失。
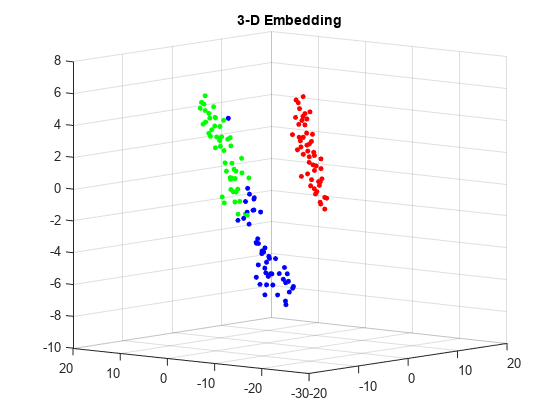
查看嵌入。使用RGB颜色(1 0 0),(0 1 0),(0 0 1)。
的3 d图,将物种数值使用分类命令,然后将数值转换为RGB颜色使用稀疏的函数如下。如果v是一个向量的正整数1、2或3,对应于该物种数据,然后命令
稀疏(1:元素个数(v), v, 1(大小(v)))
是一个稀疏矩阵的行RGB颜色的物种。
gscatter (Y (: 1), Y(:, 2),物种,眼(3))标题(“二维嵌入”)
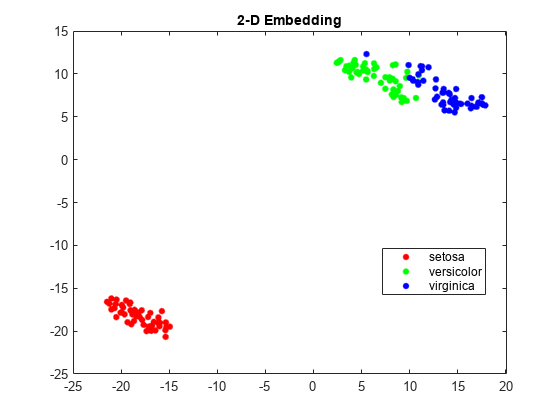
图v =双(分类(物种));c =全(稀疏(1:元素个数(v), v,(大小(v))的元素个数(v), 3));scatter3 (Y2 (:, 1), Y2 (:, 2), Y2(:, 3), 15日,c,“填充”)标题(“3 d嵌入”)视图(-50 8)
输入参数
输出参数
更多关于
算法
tsne构造一组嵌入点在低维空间的相对相似模拟的原始高维点。嵌入点显示原始数据的聚类。
约,算法模型原始分,来自一个高斯分布,以及嵌入点来自学生的t分布。算法试图最小化Kullback-Leibler散度这两个发行版之间通过移动嵌入式点。
有关详细信息,请参见t-SNE。
介绍了R2017a
