Create Simple Text Model for Classification
This example shows how to train a simple text classifier on word frequency counts using a bag-of-words model.
You can create a simple classification model which uses word frequency counts as predictors. This example trains a simple classification model to predict the category of factory reports using text descriptions.
Load and Extract Text Data
Load the example data. The filefactoryReports.csvcontains factory reports, including a text description and categorical labels for each report.
filename ="factoryReports.csv"; data = readtable(filename,'TextType','string'); head(data)
ans=8×5 tableDescription Category Urgency Resolution Cost _____________________________________________________________________ ____________________ ________ ____________________ _____ "Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" 45 "Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" 35 "There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" 16200 "Fried capacitors in the assembler." "Electronic Failure" "High" "Replace Components" 352 "Mixer tripped the fuses." "Electronic Failure" "Low" "Add to Watch List" 55 "Burst pipe in the constructing agent is spraying coolant." "Leak" "High" "Replace Components" 371 "A fuse is blown in the mixer." "Electronic Failure" "Low" "Replace Components" 441 "Things continue to tumble off of the belt." "Mechanical Failure" "Low" "Readjust Machine" 38
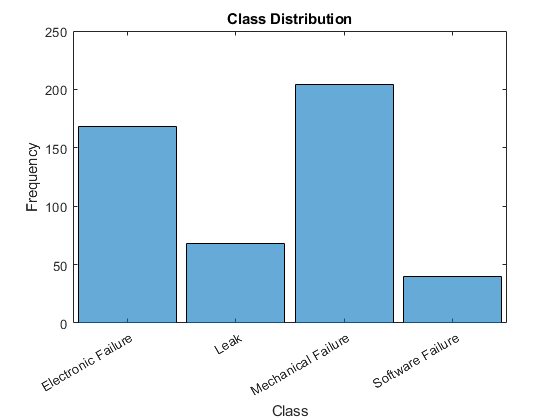
Convert the labels in theCategorycolumn of the table to categorical and view the distribution of the classes in the data using a histogram.
data.Category = categorical(data.Category); figure histogram(data.Category) xlabel("Class") ylabel("Frequency") title("Class Distribution")
Partition the data into a training partition and a held-out test set. Specify the holdout percentage to be 10%.
cvp = cvpartition(data.Category,'Holdout',0.1); dataTrain = data(cvp.training,:); dataTest = data(cvp.test,:);
Extract the text data and labels from the tables.
textDataTrain = dataTrain.Description; textDataTest = dataTest.Description; YTrain = dataTrain.Category; YTest = dataTest.Category;
Prepare Text Data for Analysis
Create a function which tokenizes and preprocesses the text data so it can be used for analysis. The functionpreprocessText, performs the following steps in order:
Tokenize the text using
tokenizedDocument.Remove a list of stop words (such as "and", "of", and "the") using
removeStopWords.Lemmatize the words using
normalizeWords.Erase punctuation using
erasePunctuation.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.
Use the example preprocessing functionpreprocessTextto prepare the text data.
documents = preprocessText(textDataTrain); documents(1:5)
ans = 5×1 tokenizedDocument: 6 tokens: items occasionally get stuck scanner spool 7 tokens: loud rattle bang sound come assembler piston 4 tokens: cut power start plant 3 tokens: fry capacitor assembler 3 tokens: mixer trip fuse
Create a bag-of-words model from the tokenized documents.
bag = bagOfWords(documents)
bag = bagOfWords with properties: Counts: [432×336 double] Vocabulary: [1×336 string] NumWords: 336 NumDocuments: 432
Remove words from the bag-of-words model that do not appear more than two times in total. Remove any documents containing no words from the bag-of-words model, and remove the corresponding entries in labels.
bag = removeInfrequentWords(bag,2); [bag,idx] = removeEmptyDocuments(bag); YTrain(idx) = []; bag
bag = bagOfWords with properties: Counts: [432×155 double] Vocabulary: [1×155 string] NumWords: 155 NumDocuments: 432
Train Supervised Classifier
Train a supervised classification model using the word frequency counts from the bag-of-words model and the labels.
Train a multiclass linear classification model usingfitcecoc. Specify theCountsproperty of the bag-of-words model to be the predictors, and the event type labels to be the response. Specify the learners to be linear. These learners support sparse data input.
XTrain = bag.Counts; mdl = fitcecoc(XTrain,YTrain,'Learners','linear')
mdl = CompactClassificationECOC ResponseName: 'Y' ClassNames: [Electronic Failure Leak Mechanical Failure Software Failure] ScoreTransform: 'none' BinaryLearners: {6×1 cell} CodingMatrix: [4×6 double] Properties, Methods
为了更好的配合,你可以try specifying different parameters of the linear learners. For more information on linear classification learner templates, seetemplateLinear.
Test Classifier
Predict the labels of the test data using the trained model and calculate the classification accuracy. The classification accuracy is the proportion of the labels that the model predicts correctly.
Preprocess the test data using the same preprocessing steps as the training data. Encode the resulting test documents as a matrix of word frequency counts according to the bag-of-words model.
documentsTest = preprocessText(textDataTest); XTest = encode(bag,documentsTest);
Predict the labels of the test data using the trained model and calculate the classification accuracy.
YPred = predict(mdl,XTest); acc = sum(YPred == YTest)/numel(YTest)
acc = 0.8542
Predict Using New Data
Classify the event type of new factory reports. Create a string array containing the new factory reports.
str = ["Coolant is pooling underneath sorter.""Sorter blows fuses at start up.""There are some very loud rattling sounds coming from the assembler."]; documentsNew = preprocessText(str); XNew = encode(bag,documentsNew); labelsNew = predict(mdl,XNew)
labelsNew =3×1 categoricalLeak Electronic Failure Mechanical Failure
Example Preprocessing Function
The functionpreprocessText, performs the following steps in order:
Tokenize the text using
tokenizedDocument.Remove a list of stop words (such as "and", "of", and "the") using
removeStopWords.Lemmatize the words using
normalizeWords.Erase punctuation using
erasePunctuation.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.
functiondocuments = preprocessText(textData)% Tokenize the text.documents = tokenizedDocument(textData);% Remove a list of stop words then lemmatize the words. To improve% lemmatization, first use addPartOfSpeechDetails.documents = addPartOfSpeechDetails(documents); documents = removeStopWords(documents); documents = normalizeWords(documents,'Style','lemma');% Erase punctuation.documents = erasePunctuation(documents);% Remove words with 2 or fewer characters, and words with 15 or more% characters.documents = removeShortWords(documents,2); documents = removeLongWords(documents,15);end
See Also
erasePunctuation|tokenizedDocument|bagOfWords|removeStopWords|removeLongWords|removeShortWords|normalizeWords|wordcloud|addPartOfSpeechDetails|encode
Related Topics
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)