点云分类使用PointNet深度学习
这个例子展示了如何训练PointNet网络点云分类。
点云数据是通过各种传感器,如激光雷达、雷达、和深度相机。这些传感器获取关于对象的3 d位置信息在一个场景,这是有用的对于许多应用程序在自动驾驶和增强现实。例如,识别车辆行人是规划一个自治的道路车辆的关键。然而,强劲的分类器训练与点云数据是很困难的,因为每个对象数据的稀疏,物体遮挡,和传感器噪声。深度学习技术已被证明应对这些挑战通过学习健壮的特性表征直接从点云数据。的一个开创性的深度学习的技术点云分类PointNet [1]。
这个例子列车PointNet分类器在悉尼城市对象数据集由悉尼大学(2]。这个数据集提供了一个收集点云数据从一个城市环境使用激光雷达传感器获得的。数据集有100标记对象来自14个不同的类别,如汽车、行人和汽车。
加载数据集
下载并提取悉尼城市对象数据集到一个临时目录中。
downloadDirectory = tempdir;datapath公司= downloadSydneyUrbanObjects (downloadDirectory);
加载下载的培训和验证数据集使用loadSydneyUrbanObjectsDatahelper函数列的这个例子。使用前三个数据折叠为验证培训和第四。
foldsTrain = 1:3;foldsVal = 4;dsTrain = loadSydneyUrbanObjectsData (datapath公司,foldsTrain);dsVal = loadSydneyUrbanObjectsData (datapath公司,foldsVal);
读的一个训练样本,使用可视化pcshow。
data =阅读(dsTrain);ptCloud数据= {1};标签={1,2}数据;图pcshow (ptCloud。位置,(0 1 0),“MarkerSize”现年40岁的“VerticalAxisDir”,“向下”)包含(“X”)ylabel (“Y”)zlabel (“Z”标题(标签)

阅读标签和计算点的数量分配给每个标签,以便更好地理解标签数据集内的分布。
dsLabelCounts =变换(dsTrain @(数据){1}{2}{数据数据.Count});labelCounts = readall (dsLabelCounts);标签= vertcat (labelCounts {: 1});数量= vertcat (labelCounts {: 2});
接下来,使用直方图来可视化类分布。
图直方图(标签)

直方图显示的标签数据集是不平衡,偏向汽车和行人,它可以防止一个健壮的分类器的训练。你可以通过采样过密address类不平衡不类。悉尼城市对象数据集,复制文件对应于罕见的类是一个简单的方法来解决类不平衡。
集团文件标签,数一数的观察每个类,并使用randReplicateFileshelper函数,列出在这个例子中,随机oversample观察每个类的文件所需的数量。
rng (0) (G) = findgroups(标签);numObservations = splitapply (@numel,标签,G);desiredNumObservationsPerClass = max (numObservations);文件= splitapply (@ (x) {randReplicateFiles (x, desiredNumObservationsPerClass)}, dsTrain.Files, G);{:}= vertcat文件(文件);dsTrain。文件=文件;
数据增加
复制文件处理类失衡的可能性增加过度拟合训练数据的网络,因为相同的。来抵消这种影响,应用数据增加训练数据使用变换和augmentPointCloud随机旋转点云的helper函数,随机删除点,与高斯噪声和随机紧张点。
dsTrain =变换(dsTrain @augmentPointCloud);
预览增强训练样本之一。
data =预览(dsTrain);ptCloud数据= {1};标签={1,2}数据;图pcshow (ptCloud。位置,(0 1 0),“MarkerSize”现年40岁的“VerticalAxisDir”,“向下”)包含(“X”)ylabel (“Y”)zlabel (“Z”标题(标签)
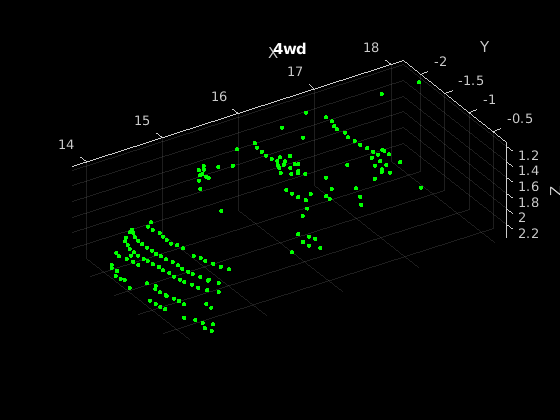
注意,由于测量的数据训练网络的性能必须代表原始数据集,数据增加不应用于验证或测试数据。
数据预处理
两个预处理步骤需要准备点云数据进行训练和预测。
首先,在培训期间启用批处理,选择一个固定数量的点从每个点云。点的最优数量取决于数据集和点的数量必须准确地捕捉物体的形状。帮助选择适当数量的点,计算最小、最大和平均数量的分类。
minPointCount = splitapply (@min,计数,G);maxPointCount = splitapply (@max,计数,G);meanPointCount = splitapply (@ (x)轮(意味着(x)), G);统计=表(类、numObservations minPointCount、maxPointCount meanPointCount)
统计=14×5表类numObservations minPointCount maxPointCount 4 wd 15售予_________________ _________________ meanPointCount * * * * * * 140 1955 751 126 11767 193 8455 2708总线11 2190车64 52 2377 528步行15 80 751 357 107 297 110柱杆13 253 90红绿灯36 38 352 161交通标志40 18 736 126树24 53 2953 470卡车9 445 3013 1376箱42 32 766 241 ute 12 90 1380 580范28 91 5809 1125
因为大量的内部类和类的可变性的数量分阶级,选择一个值符合所有的类都是困难的。一个启发式是选择足够的点充分捕捉物体的形状而不增加计算成本通过处理太多的点。值1024提供了一个很好的权衡这两个方面。您也可以选择基于实证分析的最优数量的点。然而,这超出了这个例子的范围。使用变换函数来选择训练集和验证集的1024点。
numPoints = 1024;dsTrain =变换(dsTrain @(数据)selectPoints(数据、numPoints));dsVal =变换(dsVal @(数据)selectPoints(数据、numPoints));
最后一个预处理步骤是正常点云数据在0和1之间占数据值的范围之间存在较大的差异。例如,对象接近激光雷达传感器相比,有较小的值对象。这些差异会阻碍网络在训练的收敛。使用变换规范化训练集和验证集的点云数据。
dsTrain =变换(dsTrain @preprocessPointCloud);dsVal =变换(dsVal @preprocessPointCloud);
预览和预处理增强训练数据。
data =预览(dsTrain);图pcshow(数据{1 1}[0 1 0],“MarkerSize”现年40岁的“VerticalAxisDir”,“向下”);包含(“X”)ylabel (“Y”)zlabel (“Z”{1,2})标题(数据)

定义PointNet模型
PointNet分类模型由两部分组成。第一个组件是一个点云编码器学会稀疏编码成一个密集的点云数据特征向量。第二个组件是一个分类器,每个编码点云的预测分类类。
PointNet编码器模型进一步组成的四个模型最大操作紧随其后。
输入变换模型
共享网络模型
特征变换模型
共享网络模型
共享网络模型是使用一系列的卷积,实现批量正常化,和ReLU操作。卷积操作配置共享这样的权重在输入点云。变换模型是由一个共同的延时和可学的变换矩阵,应用于每个点云。共享的延时和马克斯操作使PointNet编码器不变的顺序点处理,而变换模型提供了不变性取向变化。
定义PointNet编码器模型参数
共享延时和变换模型参数化输入通道的数量和隐藏的通道大小。选择在本例中选择的值调优这些hyperparameters悉尼城市对象数据集。注意,如果你想PointNet适用于不同的数据集,您必须执行额外的hyperparameter调优。
设置输入变换模型的输入通道大小三个和隐藏通道尺寸到64年,128年和256年,使用initializeTransformhelper函数,列出在这个例子中,初始化模型参数。
inputChannelSize = 3;hiddenChannelSize1 = [64128];hiddenChannelSize2 = 256;(参数。InputTransform,状态。InputTransform] = initializeTransform (inputChannelSize, hiddenChannelSize1 hiddenChannelSize2);
第一个共享网络模型输入通道大小设置为三个和隐藏的通道大小64和使用initializeSharedMLPhelper函数,列出在这个例子中,初始化模型参数。
inputChannelSize = 3;hiddenChannelSize = (64 - 64);[parameters.SharedMLP1状态。SharedMLP1] = initializeSharedMLP (inputChannelSize hiddenChannelSize);
功能转换模型输入通道大小设置为64和隐藏通道尺寸到64年,128年和256年,并使用initializeTransformhelper函数,列出在这个例子中,初始化模型参数。
inputChannelSize = 64;hiddenChannelSize1 = [64128];hiddenChannelSize2 = 256;(参数。FeatureTransform,状态。FeatureTransform] = initializeTransform (inputChannelSize, hiddenChannelSize hiddenChannelSize2);
第二个共享网络模型输入通道大小设置为64年和64年隐藏通道大小和使用initializeSharedMLP函数,列出在这个例子中,初始化模型参数。
inputChannelSize = 64;hiddenChannelSize = 64;[parameters.SharedMLP2状态。SharedMLP2] = initializeSharedMLP (inputChannelSize hiddenChannelSize);
定义PointNet分类器模型参数
中长期规划PointNet分类器模型由一个共享,完全连接操作,softmax激活。将分类器模型输入大小设置为64,隐藏的通道大小512年和256年和使用initalizeClassifierhelper函数,列出在这个例子中,初始化模型参数。
inputChannelSize = 64;hiddenChannelSize = [512256];numClasses =元素个数(类);(参数。ClassificationMLP,状态。ClassificationMLP] = initializeClassificationMLP (inputChannelSize, hiddenChannelSize numClasses);
定义PointNet函数
创建函数pointnetClassifier,模型函数部分列出的例子,计算PointNet模型的输出。函数模型作为输入的点云数据,可学的模型参数,模型状态,标记,用于指定是否返回输出培训或预测模型。网络收益预测分类输入点云。
定义模型梯度函数
创建函数modelGradients,模型梯度函数部分列出的例子中,这需要作为输入参数的模型,该模型状态,和mini-batch输入数据,并返回梯度的损失对模型中的可学的参数和相应的损失。
指定培训选项
火车10时代128年批和加载数据。设置初始学习速率0.002和L2正则化因子为0.01。
numEpochs = 10;learnRate = 0.002;miniBatchSize = 128;l2Regularization = 0.01;learnRateDropPeriod = 15;learnRateDropFactor = 0.5;
初始化选项为亚当的优化。
gradientDecayFactor = 0.9;squaredGradientDecayFactor = 0.999;
火车PointNet
火车模型使用自定义训练循环。
洗牌的数据开始训练。
每一次迭代:
读取一批数据。
评估模型的梯度。
应用L2体重正规化。
使用
adamupdate更新模型参数。更新培训进展阴谋。
在每个时代,评价模型对验证数据集和收集混乱指标来衡量分类精度随着培训的发展。
在完成learnRateDropPeriod时代,减少学习速率的因素learnRateDropFactor。
初始化参数的移动平均梯度和梯度的element-wise广场由亚当优化器使用。
avgGradients = [];avgSquaredGradients = [];
火车模型如果doTraining是真的。否则,加载一个pretrained网络。
注意培训验证了一个NVIDIA泰坦X 12 GB的GPU内存。如果你的GPU内存更少,培训期间你可能会耗尽内存。如果发生这种情况,降低miniBatchSize。这个网络培训大约需要5分钟。根据您的GPU硬件,它可以花费更长的时间。
doTraining = false;如果doTraining%创建一个minibatchqueue从培训和批处理数据验证%数据存储。使用batchData函数,最后列出%的例子中,批处理点云数据,在一个炎热的编码标签%的数据。numOutputsFromDSRead = 2;mbqTrain = minibatchqueue (dsTrain numOutputsFromDSRead,…“MiniBatchSize”miniBatchSize,…“MiniBatchFcn”@batchData,…“MiniBatchFormat”,(“SCSB”“公元前”]);mbqVal = minibatchqueue (dsVal numOutputsFromDSRead,…“MiniBatchSize”miniBatchSize,…“MiniBatchFcn”@batchData,…“MiniBatchFormat”,(“SCSB”“公元前”]);%使用configureTrainingProgressPlot函数,最后列出%的例子中,初始化培训进展图显示培训%,训练精度,验证精度。[lossPlotter, trainAccPlotter valAccPlotter] = initializeTrainingProgressPlot;numClasses =元素个数(类);迭代= 0;开始=抽搐;为时代= 1:numEpochs%洗牌数据每一时代。洗牌(mbqTrain);%遍历数据集。而hasdata (mbqTrain)迭代=迭代+ 1;%读取下一批的培训数据。[XTrain, YTrain] =下一个(mbqTrain);%计算模型使用dlfeval和梯度和损失% modelGradients函数。(渐变、损失、状态、acc) = dlfeval (@modelGradients、XTrain YTrain,参数,状态);% L2正规化。梯度= dlupdate (@ (g、p) g + l2Regularization * p,渐变参数);%更新使用亚当优化网络参数。(参数、avgGradients avgSquaredGradients) = adamupdate(参数、渐变…avgGradients avgSquaredGradients,迭代,…learnRate、gradientDecayFactor squaredGradientDecayFactor);%更新培训的进展。D =持续时间(0,0,toc(开始),“格式”,“hh: mm: ss”);标题(lossPlotter.Parent,”时代:“+时代+”,过去:“+字符串(D)) addpoints (lossPlotter、迭代、双(收集(extractdata(损失))))addpoints (trainAccPlotter、迭代、acc);drawnow结束%计算模型的验证数据。cmat =稀疏(numClasses numClasses);而hasdata (mbqVal)%读取下一批的验证数据。[XVal, YVal] =下一个(mbqVal);%计算标签预测。isTraining = false;YPred = pointnetClassifier (XVal、参数状态,isTraining);%选择得分最高的预测类标签% XTest。[~,YValLabel] = max (YVal [], 1);[~,YPredLabel] = max (YPred [], 1);%收集指标混乱。cmat = aggreateConfusionMetric (cmat YValLabel YPredLabel);结束%更新培训进展情节平均分类精度。acc =总和(诊断接头(cmat)。/笔(cmat,“所有”);addpoints (valAccPlotter迭代,acc);% Upate学习速率。如果国防部(时代,learnRateDropPeriod) = = 0 learnRate = learnRate * learnRateDropFactor;结束%重置训练和验证数据队列。重置(mbqTrain);重置(mbqVal);结束其他的%下载pretrained模型参数、模型状态和验证%的结果。pretrainedURL =“https://ssd.mathworks.com/万博1manbetxsupportfiles/vision/data/pointnetSydneyUrbanObjects.zip”;pretrainedResults = downloadPretrainedPointNet (pretrainedURL);参数= pretrainedResults.parameters;状态= pretrainedResults.state;cmat = pretrainedResults.cmat;%模型参数移动到GPU dlarray如果可能的话和转换。参数= prepareForPrediction(参数,@ (x) dlarray (toDevice (x, canUseGPU)));%模型状态移动到GPU如果可能的话。状态= prepareForPrediction(状态,@ (x) toDevice (x, canUseGPU));结束
显示验证混淆矩阵。
图图= confusionchart (cmat、类);
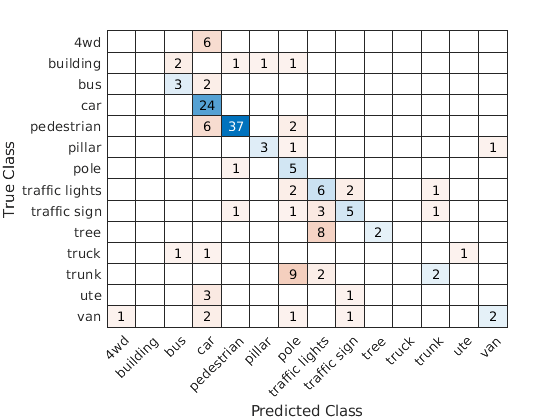
计算平均训练和验证精度。
acc =总和(诊断接头(cmat)。/笔(cmat,“所有”)
acc = 0.5742
由于数量有限的训练样本在悉尼城市对象数据集,提高了验证准确性超过60%是具有挑战性的。训练数据的模型容易overfits缺乏定义的增加augmentPointCloudDatahelper函数。改善PointNet分类器的鲁棒性,需要额外的培训。
使用PointNet点云数据进行分类
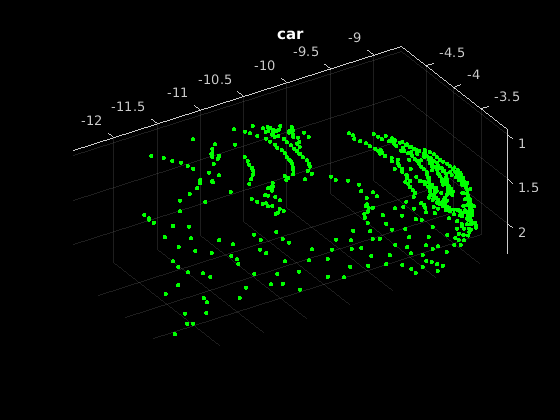
加载点云数据pcread点云预处理,使用相同的函数中使用培训,并将结果转换成dlarray。
ptCloud = pcread (“car.pcd”);X = preprocessPointCloud (ptCloud);dlX = dlarray (X {1},“SCSB”);
预测点云的标签pointnetClassifier模型的功能。
YPred = pointnetClassifier (dlX、参数、状态、错误);[~,classIdx] = max (YPred [], 1);
显示点云与得分最高的预测标签。
图pcshow (ptCloud。位置,(0 1 0),“MarkerSize”现年40岁的“VerticalAxisDir”,“向下”标题(类(classIdx))
模型梯度函数
的mini-batch modelGradients函数作为输入数据dlX,相应的目标海底可学的参数,并返回梯度的损失对可学的参数和相应的损失。损失包括一个正则化项旨在确保PointNet编码器的功能变换矩阵预测大约是正交的。计算梯度,评估modelGradients函数使用dlfeval功能训练循环。
函数(渐变、损失、状态、acc) = modelGradients (X, Y,参数、状态)%执行模型的功能。isTraining = true;[YPred、州dlT] = pointnetClassifier (X,参数,状态,isTraining);%添加正则化项,以确保功能变换矩阵%大致正交的。K =大小(dlT, 1);B =大小(dlT, 4);我= repelem(眼(K), 1, 1, 1, B);dlI = dlarray(我“SSCB”);treg = mse (dlI, pagemtimes (dlT,排列(dlT (1 2 3 4))));系数= 0.001;%计算损失。损失= crossentropy * treg (YPred, Y) +因素;%计算参数梯度对损失。梯度= dlgradient(损失、参数);%计算训练精度指标。[~,欧美]= max (Y, [], 1);[~,YPred] = max (YPred [], 1);acc =收集(extractdata (sum(欧美= = YPred)。/元素个数(欧美)));结束
PointNet分类器函数
的pointnetClassifierdlX函数作为输入的点云数据,可学的模型参数,模型状态,国旗isTraining,指定是否返回输出培训或预测模型。然后,函数调用PointNet编码器和一个多层感知器来提取分类特征。在培训期间,辍学后每个感知器操作应用。在过去的感知器,fullyconnect操作将分类特征映射到类的数量和softmax激活用于规范化输出标签的一个概率分布。概率分布,更新模型状态和特征变换矩阵的预测PointNet编码器作为输出返回。
函数(海底、州dlT) = pointnetClassifier (dlX、参数、状态、isTraining)%调用PointNet编码器。(海底、州dlT) = pointnetEncoder (dlX、参数状态,isTraining);%调用分类器。p = parameters.ClassificationMLP.Perceptron;s = state.ClassificationMLP.Perceptron;为k = 1:元素个数(p)[海底,s (k)] =感知器(海底,p (k), s (k), isTraining);%如果训练,应用反向辍学概率为0.3。如果isTraining概率= 0.3;dropoutScaleFactor = 1 -概率;dropoutMask =(兰特(大小(海底),“喜欢”、海底)>概率)/ dropoutScaleFactor;海底=海底。* dropoutMask;结束结束state.ClassificationMLP。感知器= s;%应用最终完全连接和softmax操作。重量= parameters.ClassificationMLP.FC.Weights;偏见= parameters.ClassificationMLP.FC.Bias;海底= fullyconnect(海底,重量、偏见);海底= softmax(海底);结束
PointNet编码器的功能
的pointnetEncoder函数处理输入dlX使用一个输入变换,一个共享的中长期规划,功能变换,另一个共享的中长期规划,和马克斯操作,并返回结果的最大操作。
函数(海底,状态,T) = pointnetEncoder (dlX、参数、状态、isTraining)%输入变换。(海底,状态。InputTransform] = dataTransform (dlX、parameters.InputTransform state.InputTransform, isTraining);%共享延时。(海底,state.SharedMLP1。感知器]= sharedMLP(海底,parameters.SharedMLP1.Perceptron, state.SharedMLP1.Perceptron isTraining);%功能变换。(海底,状态。FeatureTransform T] = dataTransform(海底,parameters.FeatureTransform, state.FeatureTransform isTraining);%共享延时。(海底,state.SharedMLP2。感知器]= sharedMLP(海底,parameters.SharedMLP2.Perceptron, state.SharedMLP2.Perceptron isTraining);%最大操作。海底= max(海底,[],1);结束
共享多层感知器功能
共享的多层感知器函数处理输入dlX使用一系列的感知器操作并返回最后一个感知器的结果。
函数(海底、州)= sharedMLP (dlX、参数、状态、isTraining)海底= dlX;为k = 1:元素个数(参数)[海底、州(k)] =感知器(海底参数(k),状态(k), isTraining);结束结束
感知器函数
感知器使用卷积函数处理输入dlX,一批标准化,relu操作并返回relu操作的输出。
函数(海底、州)=感知器(dlX、参数、状态、isTraining)%卷积。W = parameters.Conv.Weights;B = parameters.Conv.Bias;海底= dlconv (dlX, W, B);%批正常化。训练时更新批正常化状态。抵消= parameters.BatchNorm.Offset;规模= parameters.BatchNorm.Scale;trainedMean = state.BatchNorm.TrainedMean;trainedVariance = state.BatchNorm.TrainedVariance;如果isTraining[海底,trainedMean trainedVariance] = batchnorm(海底、抵消、规模、trainedMean trainedVariance);%更新状态。state.BatchNorm。TrainedMean = TrainedMean;state.BatchNorm。TrainedVariance = TrainedVariance;其他的海底= batchnorm(海底、抵消、规模、trainedMean trainedVariance);结束% ReLU。海底= relu(海底);结束
数据转换功能
的dataTransform函数处理输入dlX使用共享的延时,马克斯操作,另一个共享延时预测变换矩阵t变换矩阵应用于输入dlX使用批处理矩阵乘运算。函数返回的结果成批的矩阵乘法和变换矩阵。
函数(海底,状态,T) = dataTransform (dlX、参数、状态、isTraining)%共享延时。(海底,state.Block1。感知器]= sharedMLP (dlX、parameters.Block1.Perceptron state.Block1.Perceptron, isTraining);%最大操作。海底= max(海底,[],1);%共享延时。(海底,state.Block2。感知器]= sharedMLP(海底,parameters.Block2.Perceptron, state.Block2.Perceptron isTraining);%转换网(网)。应用W * X,最后完全连接操作%预测T变换矩阵。海底=挤压(海底);% N-by-BT =参数。变换* stripdims(海底);% K ^ 2-by-B% T改造成一个方阵。K =√大小(T, 1));T =重塑(T, K, K, 1, []);% (K K 1 B)T = T +眼(K);%适用于输入dlX使用批处理矩阵相乘。[C, B] =大小(dlX [3 - 4]);% (M 1 K B)dlX =重塑(dlX, [], C, 1 B);% (M K 1 B)Y = pagemtimes (dlX T);海底= dlarray (Y,“SCSB”);结束
模型参数初始化函数
initializeTransform函数
的initializeTransform函数作为输入通道的大小和数量的隐藏两个渠道共享全局,并返回一个结构体的初始化参数。使用他重初始化参数初始化3]。
函数(参数、状态)= initializeTransform (inputChannelSize、block1 block2) [params.Block1、状态。Block1] = initializeSharedMLP (inputChannelSize Block1);[params.Block2状态。Block2] = initializeSharedMLP (block1(结束),Block2);%的参数变换矩阵。参数个数。变换= dlarray (0 (inputChannelSize ^ 2, block2(结束)));结束
initializeSharedMLP函数
initializeSharedMLP函数作为输入通道尺寸和隐藏的通道大小,并返回一个结构体的初始化参数。使用他的体重初始化参数初始化。
函数(参数、状态)= initializeSharedMLP (inputChannelSize hiddenChannelSize)权重= initializeWeightsHe ([1 1 inputChannelSize hiddenChannelSize (1)]);偏见= 0 (hiddenChannelSize (1), 1,“单身”);p.Conv。重量= dlarray(重量);p.Conv。偏见= dlarray(偏差);p.BatchNorm。抵消= dlarray (0 (hiddenChannelSize (1), 1,“单身”));p.BatchNorm。规模= dlarray(的(hiddenChannelSize (1), 1,“单身”));s.BatchNorm。TrainedMean = 0 (hiddenChannelSize (1), 1,“单身”);s.BatchNorm。TrainedVariance = 1 (hiddenChannelSize (1), 1,“单身”);params.Perceptron (1) = p;state.Perceptron (1) = s;为k = 2:元素个数(hiddenChannelSize)权重= initializeWeightsHe ([1 1 hiddenChannelSize (k - 1) hiddenChannelSize (k)));偏见= 0 (hiddenChannelSize (k), 1,“单身”);p.Conv。重量= dlarray(重量);p.Conv。偏见= dlarray(偏差);p.BatchNorm。抵消= dlarray (0 (hiddenChannelSize (k), 1,“单身”));p.BatchNorm。规模= dlarray(的(hiddenChannelSize (k), 1,“单身”));s.BatchNorm。TrainedMean = 0 (hiddenChannelSize (k), 1,“单身”);s.BatchNorm。TrainedVariance = 1 (hiddenChannelSize (k), 1,“单身”);params.Perceptron (k) = p;state.Perceptron (k) = s;结束结束
initializeClassificationMLP函数
的initializeClassificationMLP函数作为输入通道大小,隐藏的通道大小和类的数量,并返回一个结构体的初始化参数。初始化共享MLP使用他初始化和最终的重量完全连接操作是使用随机高斯值初始化的。
函数(参数、状态)= initializeClassificationMLP (inputChannelSize、hiddenChannelSize numClasses)[参数、状态]= initializeSharedMLP (inputChannelSize hiddenChannelSize);重量= initializeWeightsGaussian ([numClasses hiddenChannelSize(结束)]);偏见= 0 (numClasses 1“单身”);params.FC。重量= dlarray(重量);params.FC。偏见= dlarray(偏差);结束
initializeWeightsHe函数
的initializeWeightsHe使用他的初始化函数初始化参数。
函数x = initializeWeightsHe(深圳)扇入= prod(深圳(1:3));stddev =√2 /扇入);x = stddev。* randn(深圳);结束
initializeWeightsGaussian函数
的initializeWeightsGaussian使用高斯函数初始化参数初始化标准偏差为0.01。
函数x = initializeWeightsGaussian(深圳)x = randn(深圳,“单身”)* 0.01;结束
数据预处理功能
preprocessPointCloudData函数
的preprocessPointCloudData函数提取X, Y, Z点数据从输入数据和规范数据在0和1之间。函数返回规范化X, Y, Z的数据。
函数data = preprocessPointCloud(数据)如果~ iscell数据(数据)={数据};结束numObservations =大小(数据,1);为我= 1:numObservations%规模点在0和1之间。xlim ={我1}.XLimits数据;ylim ={我1}.YLimits数据;zlim ={我1}.ZLimits数据;xyzMin = [xlim (1) ylim (1) zlim (1)];xyzDiff = [diff (xlim) diff (ylim) diff (zlim)];{我1}=(数据{1}我。位置- xyzMin)。/ xyzDiff;结束结束
selectPoints函数
的selectPoints函数所需的样本数量的点。当点云包含所需的数量多点,函数使用pcdownsample随机选择的点。否则,该函数将数据复制到生产所需的点数。
函数numPoints data = selectPoints(数据)%选择所需的点数将采样或复制%点云数据。numObservations =大小(数据,1);为i = 1: numObservations ptCloud ={1}我的数据;如果ptCloud。数> = numPoints / ptCloud.Count numPoints百分比;数据{1}= pcdownsample (ptCloud,“随机”、比例);其他的replicationFactor =装天花板(numPoints / ptCloud.Count);印第安纳州= repmat (1: ptCloud.Count 1 replicationFactor);数据{1}=选择(ptCloud,印第安纳州(1:numPoints));结束结束结束
数据增强功能
的augmentPointCloudData随机函数对z轴旋转一个点云,随机下降30%的点,并与高斯噪声随机紧张点位置。
函数data = augmentPointCloud(数据)numObservations =大小(数据,1);为i = 1: numObservations ptCloud ={1}我的数据;%旋转的点云“轴”,这是Z的数据集。tform = randomAffine3d (…“XReflection”,真的,…“YReflection”,真的,…“旋转”,@randomRotationAboutZ);ptCloud = pctransform (ptCloud tform);%随机放弃30%的点。如果兰德> 0.5 ptCloud = pcdownsample (ptCloud“随机”,0.3);结束如果兰德> 0.5%抖动点位置与高斯噪声平均值为0%的标准偏差为0.02通过创建一个随机位移场。D = 0.02 * randn(大小(ptCloud.Location));ptCloud = pctransform (ptCloud D);结束数据{1}= ptCloud;结束结束函数(rotationAxisθ)= randomRotationAboutZ () rotationAxis = (0 0 1);θ= 360 *兰特;结束
万博1manbetx支持功能
aggregateConfusionMetric函数
的aggregateConfusionMetric功能逐步填补了混淆矩阵的基础上,预测结果YPred和预期结果欧美。
函数欧美,cmat = aggreateConfusionMetric (cmat YPred)欧美=收集(extractdata(欧美));YPred =收集(extractdata (YPred));[m, n] =大小(cmat);cmat = cmat +满(稀疏(欧美YPred 1, m, n));结束
initializeTrainingProgressPlot函数
的initializeTrainingProgressPlot功能配置两个情节显示训练,训练精度,验证精度。
函数[绘图仪,trainAccPlotter valAccPlotter] = initializeTrainingProgressPlot ()%画出损失,训练精度,验证精度。图%损失情节次要情节(2,1,1)绘图机= animatedline;包含(“迭代”)ylabel (“损失”)%精度图次要情节(2,1,2)trainAccPlotter = animatedline (“颜色”,“b”);valAccPlotter = animatedline (“颜色”,‘g’);传奇(“训练的准确性”,“验证准确性”,“位置”,“西北”);包含(“迭代”)ylabel (“准确性”)结束
replicateFiles函数
的replicateFiles函数随机oversamples一组文件并返回一组文件numDesired元素。
函数文件= randReplicateFiles(文件、numDesired) n =元素个数(文件);印第安纳州=兰迪(n, numDesired, 1);文件=文件(印第安纳州);结束
downloadSydneyUrbanObjects函数
的downloadSydneyUrbanObjects功能下载数据集保存到一个临时目录中。
函数datapath公司= downloadSydneyUrbanObjects (dataLoc)如果输入参数个数= = 0 dataLoc = pwd;结束dataLoc =字符串(dataLoc);url =“http://www.acfr.usyd.edu.au/papers/data/”;name =“sydney-urban-objects-dataset.tar.gz”;datapath公司= fullfile (dataLoc,“sydney-urban-objects-dataset”);如果~存在(datapath公司,“dir”)disp (“下载悉尼城市对象数据集…”);解压(url +名字,dataLoc);结束结束
loadSydneyUrbanObjectsData函数
的loadSydneyUrbanObjectsData函数创建一个数据存储加载点云从悉尼城市和标签数据对象数据集。
函数ds = loadSydneyUrbanObjectsData (datapath公司、折叠)如果输入参数个数= = 0返回;结束如果输入参数个数< 2折叠= 1:4;结束datapath公司=字符串(datapath公司);路径= fullfile (datapath公司,“对象”,filesep);%折叠添加到数据存储中。foldNames {1} = importdata (fullfile (datapath公司,“折叠”,“fold0.txt”));foldNames {2} = importdata (fullfile (datapath公司,“折叠”,“fold1.txt”));foldNames {3} = importdata (fullfile (datapath公司,“折叠”,“fold2.txt”));foldNames {4} = importdata (fullfile (datapath公司,“折叠”,“fold3.txt”));名称= foldNames(折叠);名称= vertcat(名字{:});fullFilenames = append(路径、名称);ds = fileDatastore (fullFilenames,“ReadFcn”@extractTrainingData,“FileExtensions”,“。斌”);结束
batchData函数
的batchData函数数据整理到批次和移动数据到GPU进行处理。
函数(X, Y) = batchData (ptCloud、标签)X =猫(4,ptCloud {:});标签=猫(1、标签{:});Y = onehotencode(标签,2);结束
extractTrainingData函数
extractTrainingData函数提取点云从悉尼城市和标签数据对象数据集。
函数dataOut = extractTrainingData(帧)(pointData、强度)= readbin(帧);[~、名称]= fileparts(帧);name =字符串(名称);名称= extractBefore(名称、“。”);name =取代(名称、“_”,' ');labelNames = [“四轮驱动”,“建筑”,“公共汽车”,“汽车”,“行人”,“支柱”,…“极”,“红绿灯”,“交通标志”,“树”,“卡车”,“树干”,“哑巴”,“范”];标签=分类(名称、labelNames);dataOut = {pointCloud (pointData“强度”、强度),标签};结束
readbin函数
的readbin函数读取点云数据从悉尼城市对象二进制文件。
函数(pointData、强度)= readbin(帧)% readbin读取点和强度数据从悉尼城市二进制对象%的文件。%的名字= [“t”、“强度”、“id”,…% ' x ', ' y ', ' z ',……%“方位”、“范围”、“pid”)%%格式= [‘int64’,‘uint8’,‘uint8’,……%’float32’,‘float32’,‘float32’,……% ' float32 ', ' float32 ', ' int32 ']fid = fopen(帧,“r”);c = onCleanup(@()文件关闭(fid));fseek(支撑材10 1);%将第一个X点位置10个字节从开始X =从文件中读(fid,正无穷,“单一”,30);fseek (fid, 14日1);Y =从文件中读(fid,正无穷,“单一”,30);fseek(支撑材,18岁,1);Z =从文件中读(fid,正无穷,“单一”,30);fseek(支撑材8 1);强度=从文件中读(fid,正无穷,“uint8”33);pointData = [X, Y, Z];结束
downloadPretrainedPointNet函数
的downloadPretrainedPointNet功能下载pretrained pointnet模型。
函数data = downloadPretrainedPointNet (pretrainedURL)%下载和加载pretrained pointnet模型。如果~ (“pointnetSydneyUrbanObjects.mat”,“文件”)如果~ (“pointnetSydneyUrbanObjects.zip”,“文件”)disp (“下载pretrained检测器(5 MB)…”);websave (“pointnetSydneyUrbanObjects.zip”,pretrainedURL);结束解压缩(“pointnetSydneyUrbanObjects.zip”);结束data =负载(“pointnetSydneyUrbanObjects.mat”);结束
prepareForPrediction函数
的prepareForPrediction函数是用来申请一个用户定义的函数嵌套结构数据。这是一个用于将模型参数和状态数据移动到GPU。
函数p = prepareForPrediction (p, fcn)为i = 1:元素个数(p) p (i) = structfun (@ (x)调用(fcn x)、p (i),“UniformOutput”,0);结束函数data =调用(fcn、数据)如果= prepareForPrediction isstruct(数据)数据(数据、fcn);其他的data = fcn(数据);结束结束结束%的GPU移动数据。函数x = toDevice (x, useGPU)如果useGPU x = gpuArray (x);结束结束
引用
[1]查尔斯,r·齐郝苏,莫Kaichun,列奥尼达斯j . Guibas。“PointNet:深入学习三维点集分类和分割。“在2017年IEEE计算机视觉与模式识别会议(CVPR),77 - 85。火奴鲁鲁,你好:IEEE 2017。https://doi.org/10.1109/CVPR.2017.16。
[2]de Deuge马克,阿拉斯泰尔•quadra卡尔文挂,伯特兰Douillard。“无监督特征学习的分类户外3 d扫描。”In澳大拉西亚的会议在2013年机器人与自动化(肢端13)。悉尼,澳大利亚:肢端,2013年。
[3]他开明、象屿张任Shaoqing,剑太阳。“深深入整流器:超越人类表现ImageNet分类。“在2015年IEEE计算机视觉国际会议(ICCV)1026 - 34。圣地亚哥,智利:IEEE 2015。https://doi.org/10.1109/ICCV.2015.123。
相关的话题
- 开始使用点云使用深度学习
- 自定义训练循环,损失函数和网络(深度学习工具箱)
- 指定培训选项自定义训练循环(深度学习工具箱)
- 列车网络的使用自定义训练循环(深度学习工具箱)
- 深度学习层的列表(深度学习工具箱)
- 深度学习技巧和窍门(深度学习工具箱)
- 自动分化背景(深度学习工具箱)