加固学习工具箱
Progettare e Addestrare Politiche Utilizzando IL强化学习
加固学习工具箱™Fornisce Funzioni e Blocchi每le Politiche di Addestrantameo Utilizzando allitmi di加固学习Tra Cui DQN,A2C E DDPG。èConsibileultizzareQuesti Algoritmi Per Mideverare Controllori E alloritmi di决策每SiStemi Complossi来了机器人E Sistemi Automi。è可以实现Queste Politiche Utilizzando Reti Neurali Profonde,Polinomi o查找表。
Il Toolbox Ti Permette di Addestrare Politiche Grazie All'interAzione Con Ambienti Rappresentati da Modelli Matlab®o 万博1manbetxsimulink.®。èChoribileValutareAlgoritmi,SperimentareLeChostazioni Degli Iperparametri e监视器IL Progresso Dell'Advestamento。Per Migliorare Le Prestazioni di Addestameo,èSeasibileSeSeGuireSimulazioni在CarardateO Nel Cloud中,在Cluster Di Computer E GPU中(CONPLANTER COMPLENG TOOLBOX™E MATLABPLILLEXT Server™)。
attraverso il formato del modello onnx™,è可能导致Politiche Esistenti da Framework di Dee Dee Deave Learning来到Tensorflow™Keras E Pytorch(Con Deep Searing Toolbox™)。è可能赋予CODICE C,C ++ E分布Politiche obastrate Su MicroControllore E GPU的C ++ e Cuda Ottimizzati。
IL Toolbox包括每个L'USO Del强化学习的ESEMPI DI Riferimento Per Progettare Controllioni opmazioni di robotica e di guida automa。
Inizia Ora:


电子书Gratuito
加固学习Con Matlab e Simulink万博1manbetx
Algoritmi DI强化学习
Impilea Agenti Urilitizzando Deep Q-Network(DQN),优势演员评论家(A2C),深度确定性政策梯度(DDPG)E Altri Algoritmi Integrati。每个实现的Urilitizza模板Personalizzat每le Politiche di Addestramento。

GLI Agenti ComperendOON una Politica E联合国alloritmo。
Rappresentazione Della Funzione del Valore E Della Politica Utilizzando Reti Neurali Profonde
Urilizza Le Politiche di Una Rete Neureal Profonda Persistemi Complassi Con Ampi Spazi Azione-Stato。Definessisci Le Politiche Utilizzando Reti Echitture DAL深层学习工具箱。importa modelli onnx每个l'Interoperabilitàconaltri框架di深深学习。

Blocchi 万博1manbetxSimulink Per Agenti
在Simulink中实现EActiStra Agenti DI强化学习。万博1manbetx

每种Simulink的Blocco Agente DI强化学习。万博1manbetx
Ambienti 万博1manbetxSimulink E Simscape
utilizza modelli 万博1manbetxsimulink e simscape™按Rappresentare un Ambiente。特定I Segnali di Osservazione,Azione e Respazione All'Terno del Modello。

Modello di Ambiente 万博1manbetxSimulink Per Un Pendolo Inverso。
Ambienti Matlab.
utilizza funzioni e classi matlab按Rappresentare un Ambiente。特定的Variabili di Osservazione,Azione e Respazione All'Terno del文件Matlab。

Ambiente matlab每il Sistema车杆。
Calcolo DistripoItione Eccelerazione Multicore
Accelera L'Addestramento eseguendo simulazioni平行苏电脑多芯,云云o cluster di Computerizzando并行计算工具箱eMATLAB并行服务器。

Accelera L'Addestramento Utilizzando IL Calcolo Carlacko。
Accelerazione GPU.
Accelera L'Addestrantamo Delle Reti Neulti Proponde E L'Inferenza Con GPU Nvidia®广告Alte Prestazioni。Urilizza matlab con.并行计算工具箱e la maggior parte delle gpu nvidia per cuda令人讨厌®Che Hanno Una.Covelitàdielaborazionepari o superiore a 3.0。

Accelerazione dell'adtestamento Utilizzando GPU。
Generazione di Codice.
utilizza.GPU编码器™每个遗嘱CODICE CUDA OTTIMIZZZATO DAL CODICE MATLAB CHE RAPPRESENTA LE POLITICHE BADSTRATET。utilizza.Matlab Coder™每个遗传性Codice C / C ++每分配Politiche。

Generazione di Codice Cuda Utilizzando GPU编码器。
万博1manbetx每个matlab编译器的支持
utilizza.Matlab Compiler™E.MATLAB编译器SDK™每个分布Politiche addestrate guestive guestive courtive c / c ++,装配微软®.NET,Classi Java®e pacchetti python.®。

Pacchetto e Condivisione di Politiche来了Programmi独立。
每个Iniziasre.
Illinga Controllori Basati Sul强化学习每次问题IL Bilanciamento Di联合国Pendolo Inverso,La Navigazione在联合国问题迪重温Globale E IL Bilanciamento di联合国塞斯迈卡车杆。


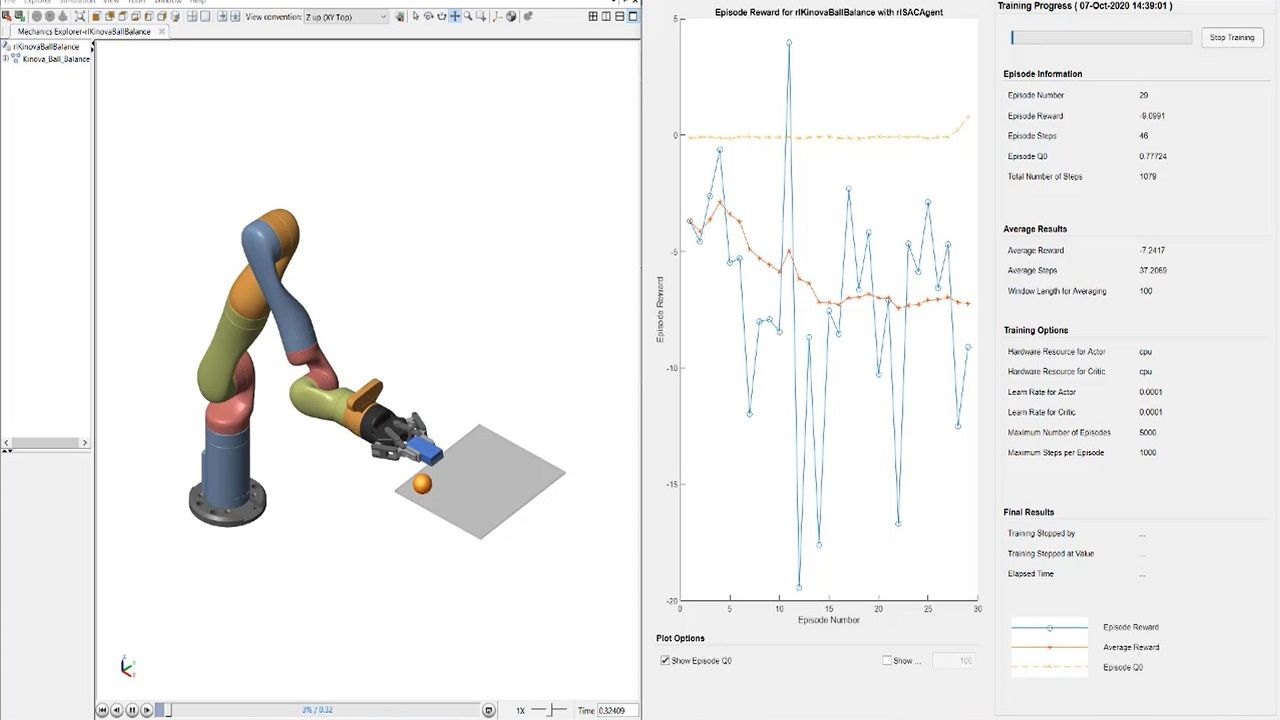
RISOLUZIONE DI联合国问题迪重温球体。
alplopazioni per la guida automa
Progetta Controllori每SiStemi AntisBandamento邮轮控制adativo。


织机
Progetta Controllori每个机器人Utilizzando IL Reinfrocents学习。

Addestrare联机器机器人A Camminare Utilizzando IL强化学习。

水分布资源分配问题。

加强学习视频系列
观看本系列中的视频,了解有关强化学习的更多信息。
