说话者识别使用沥青和MFCC
这个例子演示了基于机器学习的方法来识别人的特性提取记录演讲。用于训练分类器的特点是演讲的表达部分的音高和梅尔频率倒谱系数(MFCC)。这是一个闭集扬声器标识:扬声器的音频测试比较反对所有可用的说话人模型(一个有限集)并返回最接近的匹配。
介绍
在这个例子用于扬声器的方法识别图所示。
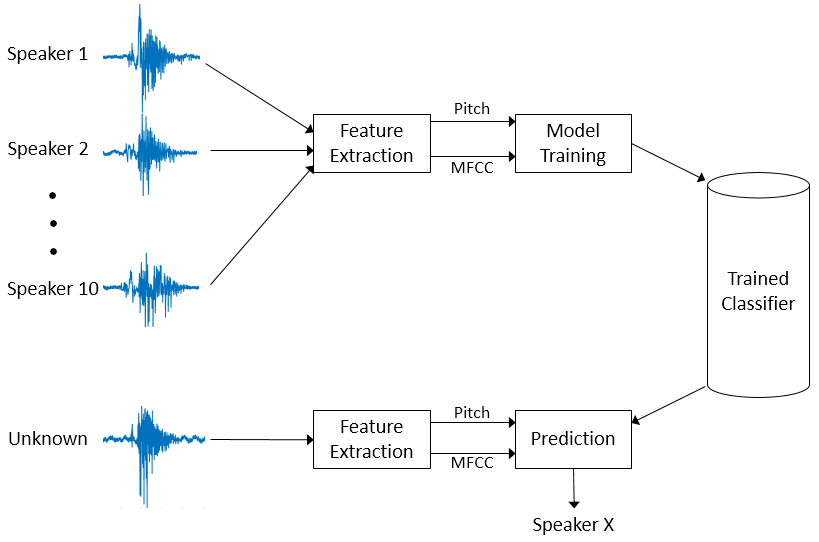
音高和MFCC提取语音信号记录10人。这些特性是用来训练再(资讯)分类器。然后,新的语音信号,需要分类经历相同的特征提取。然而训练分类器预测哪一个10人是最接近的匹配。
特征用于分类
本节讨论,讨论二阶导数过零率、短时能量和MFCC。音高和MFCC的两个特征用于分类扬声器。讨论二阶导数过零率和短时能量是用来确定音高特征时使用。
球场
演讲可以大致归类为表达了和无声的。在言论表达的情况下,空气从肺部是由声带调制和结果准周期性的激励。由此产生的声音是由一个相对低频振荡,称为球场。在无声的演讲中,空气从肺部通过收缩声道和成为动荡,声激励。source-filter模型的演讲,激励被称为源和声道称为滤波器。描述源描述语言系统的一个重要组成部分。
作为语音浊音和清音的的一个例子,考虑一个词的时域表示“两个”(T /华盛顿/)。辅音/ T /(无声的言语)看起来像噪音,而元音/华盛顿/(演讲)的特点是强烈的基本频率。
[audioIn, fs] = audioread (“Counting-16-44p1-mono-15secs.wav”);twoStart = 110年e3;twoStop = 135年e3;audioIn = audioIn (twoStart: twoStop);timeVector = linspace (twoStart / fs, twoStop / fs,元素个数(audioIn));声音(audioIn fs)图绘制(timeVector audioIn)轴(((twoStart / fs) (twoStop / fs) 1 1]) ylabel (“振幅”)包含(“时间(s)”)标题(“话语——两个“)
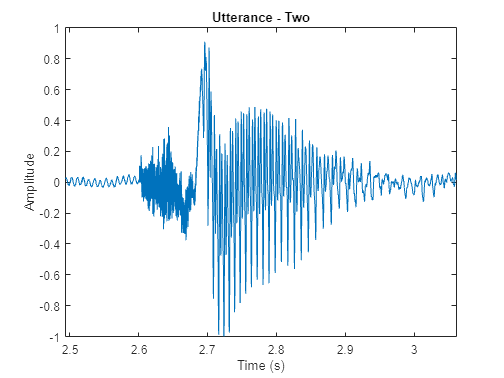
一个语音信号在本质上是动态的,会随着时间而改变。假设语音信号固定在短时间尺度上,都是和他们处理在windows - 40毫秒。这个例子使用一个30 ms窗口,25 ms重叠。使用球场函数,看看球场会随着时间而改变。
windowLength =圆(0.03 * fs);overlapLength =圆(0.025 * fs);f0 =音高(fs, audioIn WindowLength = WindowLength OverlapLength = OverlapLength范围= [50250]);图次要情节(2,1,1)情节(timeVector audioIn)轴(((110年e3 / fs)(135年e3 / fs) 1 1]) ylabel (“振幅”)包含(“时间(s)”)标题(“话语——两个“次要情节(2,1,2)timeVectorPitch = linspace (twoStart / fs, twoStop / fs,元素个数(f0));情节(timeVectorPitch f0,“*”)轴(((110年e3 / fs)(135年e3 / fs)最小(f0)最大(f0)]) ylabel (“球场(Hz)”)包含(“时间(s)”)标题(“轮廓”)
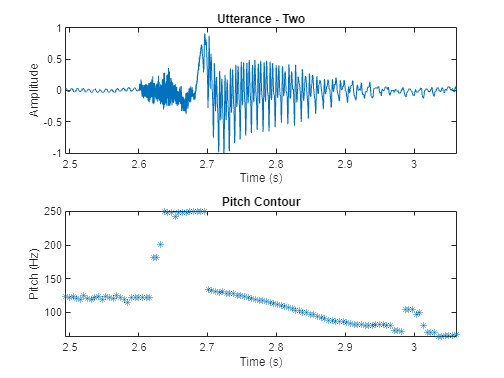
的球场估计每一帧的螺距值函数。然而,推销只是言论表达的地区来源的特征。最简单的方法区分沉默和演讲是分析短时间的能量。如果上面的能量在一个框架是一个给定的阈值,您声明框架作为演讲。
energyThreshold = 20;(段,~)=缓冲区(audioIn、windowLength overlapLength,“nodelay”);ste =总和((部分。*汉明(windowLength,“周期”))^ 2,1);isSpeech = ste (:) > energyThreshold;
最简单的方法区分语音浊音和清音的是分析过零率。大量的零交叉意味着没有主导低频振荡。如果一个框架的过零率低于给定的阈值,您声明表示。
zcrThreshold = 0.02;zcr = zerocrossrate (audioIn WindowLength = WindowLength OverlapLength = OverlapLength);isVoiced = zcr < zcrThreshold;
结合isSpeech和isVoiced确定一个框架包含表示演讲。
voicedSpeech = isSpeech & isVoiced;
删除不对应的区域表示语音音高估计和阴谋。
f0 (~ voicedSpeech) =南;图次要情节(2,1,1)情节(timeVector audioIn)轴(((110年e3 / fs)(135年e3 / fs) 1 1])轴紧ylabel (“振幅”)包含(“时间(s)”)标题(“话语——两个“次要情节(2,1,2)情节(timeVectorPitch f0,“*”)轴(((110年e3 / fs)(135年e3 / fs)最小(f0)最大(f0)]) ylabel (“球场(Hz)”)包含(“时间(s)”)标题(“轮廓”)

Mel-Frequency倒谱系数(MFCC)
MFCC流行特征从语音信号中提取用于识别任务。source-filter模型中的言论,MFCC理解代表过滤器(声道)。声道相对平滑的频率响应,而言论表达的来源可以建模为一个脉冲序列。结果是可以估计的声道谱包络的语音段。
MFCC的激励思想是压缩信息声道(光谱平滑)少量系数基于对耳蜗的理解。
虽然没有计算MFCC硬标准,概述了图的基本步骤。
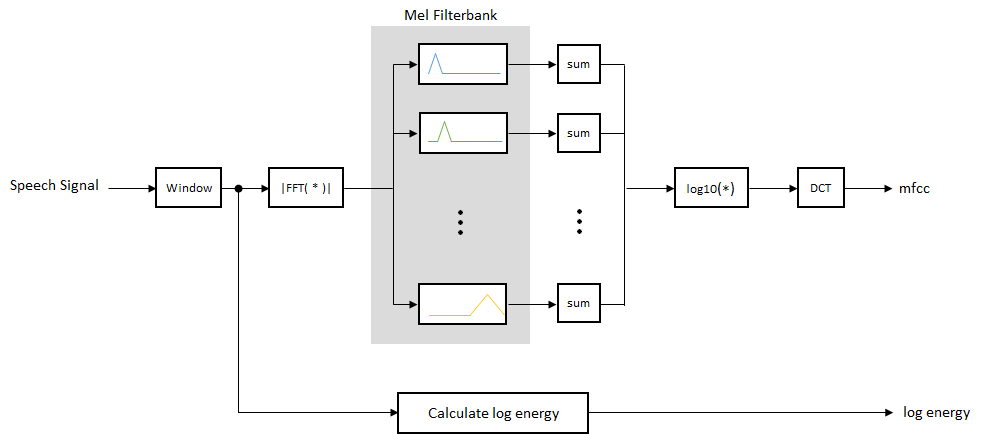
梅尔filterbank线性空间的第一个10三角过滤器和对数空间剩余的过滤器。个人乐队甚至加权能量。图是梅尔filterbank的典型代表。

这个示例使用mfcc计算每个文件的MFCC。
数据集
这个示例使用常见的声音从Mozilla数据集的一个子集[1]。数据集包含48 kHz的录音主题说短句子。本节中的helper函数并返回一个组织下载数据audioDatastore对象。数据集使用1.36 GB的内存。
下载数据集,如果不存在并将其解压缩tempdir。
downloadFolder = matlab.internal.examples.download万博1manbetxSupportFile (“音频”,“commonvoice.zip”);dataFolder = tempdir;如果~ datasetExists (dataFolder) +(字符串“无法推进”)解压缩(downloadFolder dataFolder);结束
提取语音文件10人(5女5男),将它们放入一个audioDatastore使用commonVoiceHelper函数。数据存储,您可以收集必要的文件的文件格式和阅读。函数是放置在当前文件夹当你打开这个例子。
广告= commonVoiceHelper
广告= audioDatastore属性:文件:{“…\ AppData \当地\ Temp \无法推进\ \培训\剪辑common_voice_en_116626.wav”;’……\ AppData \当地\ Temp \无法推进\ \培训\剪辑common_voice_en_116631.wav”;“…\ AppData \当地\ Temp \ \ common_voice_en_116643无法推进\培训\片段。wav”……文件夹和172}:{“C: \ \ jblock \ AppData \用户当地\ Temp \无法推进\培训\剪辑}标签:[3;3;3……和172年更直言]AlternateFileSystemRoots: {} OutputDataType:“双”SupportedOutputFormats: 万博1manbetx[“wav”“flac”“ogg”“作品”“mp4”“m4a格式”]DefaultOutputFormat:“wav”
的splitEachLabel的函数audioDatastore将数据存储到两个或两个以上的数据存储。由此产生的数据存储的音频文件指定的比例从每个标签。在本例中,数据存储分为两个部分。80%的数据为每个标签是用于训练,剩下的20%是用于测试。的countEachLabel的方法audioDatastore用于计算音频文件的数量每标签。在这个例子中,标签标识演讲者。
[adsTrain, adsTest] = splitEachLabel(广告,0.8);
显示数据存储和扬声器在火车上数据存储的数量。
adsTrain
adsTrain = audioDatastore属性:文件:{“…\ AppData \当地\ Temp \无法推进\ \培训\剪辑common_voice_en_116626.wav”;’……\ AppData \当地\ Temp \无法推进\ \培训\剪辑common_voice_en_116631.wav”;“…\ AppData \当地\ Temp \ \ common_voice_en_116643无法推进\培训\片段。wav”……文件夹和136}:{“C: \ \ jblock \ AppData \用户当地\ Temp \无法推进\培训\剪辑}标签:[3;3;3……和136年更直言]AlternateFileSystemRoots: {} OutputDataType:“双”SupportedOutputFormats: 万博1manbetx[“wav”“flac”“ogg”“作品”“mp4”“m4a格式”]DefaultOutputFormat:“wav”
trainDatastoreCount = countEachLabel (adsTrain)
trainDatastoreCount =10×2表标签数_____ _____ 1 14 10 12 2 12 3 18 4 14 5 16 6 17 7 11 8 11 9 14
显示数据存储和扬声器在测试数据存储的数量。
adsTest
adsTest = audioDatastore属性:文件:{“…\ AppData \当地\ Temp \无法推进\ \培训\剪辑common_voice_en_116761.wav”;’……\ AppData \当地\ Temp \无法推进\ \培训\剪辑common_voice_en_116762.wav”;“…\ AppData \当地\ Temp \ \ common_voice_en_116769无法推进\培训\片段。wav”……文件夹和33}:{“C: \ \ jblock \ AppData \用户当地\ Temp \无法推进\培训\剪辑}标签:[3;3;3……和33更直言]AlternateFileSystemRoots: {} OutputDataType:“双”SupportedOutputFormats: [万博1manbetx“wav”“flac”“ogg”“作品”“mp4”“m4a格式”]DefaultOutputFormat:“wav”
testDatastoreCount = countEachLabel (adsTest)
testDatastoreCount =10×2表标签数_____ _____ 1 4 10 3 2 3 3 4 4 4 5 6 7 8 3 9 4
预览的内容您的数据存储,读取一个示例文件并使用默认的音频设备播放。
[sampleTrain, dsInfo] =阅读(adsTrain);声音(sampleTrain dsInfo.SampleRate)
阅读从火车数据存储将读指针,这样您就可以遍历数据库。重置数据存储返回的火车读指针开始下面的特征提取。
重置(adsTrain)
特征提取
从每一帧中提取音高和MFCC特征对应的言论表示训练数据存储。音频工具箱™提供audioFeatureExtractor这样你就能快速有效地提取多个特性。配置一个audioFeatureExtractor提取音高,短时能量,zcr和MFCC。
fs = dsInfo.SampleRate;windowLength =圆(0.03 * fs);overlapLength =圆(0.025 * fs);afe = audioFeatureExtractor (SampleRate = fs,…窗口=汉明(windowLength,“周期”),OverlapLength = OverlapLength,…zerocrossrate = true, shortTimeEnergy = true, = true, mfcc = true);
当你叫的提取功能audioFeatureExtractor,所有功能连接并返回一个矩阵。您可以使用信息函数来确定哪些列矩阵对应的功能。
featureMap = info (afe)
featureMap =结构体字段:mfcc:(1 2 3 4 5 6 7 8 9 10 11 12 13]情节:14 zerocrossrate: 15 shortTimeEnergy: 16
从数据中提取特征集。
特点= [];标签= [];energyThreshold = 0.005;zcrThreshold = 0.2;keepLen =圆(长度(sampleTrain) / 3);而hasdata (adsTrain) [audioIn dsInfo] =阅读(adsTrain);%将每个记录加速代码的第一部分audioIn = audioIn (1: keepLen);audioIn壮举=提取(afe);(isSpeech =壮举:featureMap.shortTimeEnergy) > energyThreshold;(isVoiced =壮举:featureMap.zerocrossrate) < zcrThreshold;voicedSpeech = isSpeech & isVoiced;壮举(~ voicedSpeech,:) = [];(的壮举:[featureMap.zerocrossrate featureMap.shortTimeEnergy]) = [];标签= repelem (dsInfo.Label、尺寸(功绩,1));特点=(功能;壮举);标签=(标签,标签);结束
音高和MFCC并不相同的规模。这将偏差分类器。规范化的特性通过减去均值和标准差分裂。
M =意味着(功能,1);S =性病(特性,[],1);特点= (features-M)。/ S;
训练一个分类器
现在您已经收集所有10个扬声器功能,你可以训练一个分类器基于他们。在本例中,您使用一个再(资讯)分类器。然而,自然是一种分类技术适合于多类分类。最近邻分类器的hyperparameters包括最近的邻居,邻居的距离度量用于计算距离,距离度量的重量。选择hyperparameters优化验证精度和性能测试集。在这个例子中,邻居的数量设置为5和距离选择的指标是squared-inverse加权欧氏距离。关于分类器的更多信息,请参考fitcknn(统计和机器学习的工具箱)。
训练分类器和打印交叉验证精度。crossval(统计和机器学习的工具箱)和kfoldLoss(统计和机器学习的工具箱)用于计算交叉验证资讯分类器的精度。
指定所有分类器的选择和训练分类器。
trainedClassifier = fitcknn(特性、标签…距离=“欧几里得”,…NumNeighbors = 5,…DistanceWeight =“squaredinverse”,…规范= false,…一会=独特(标签);
执行交叉验证。
k = 5;组=标签;c = cvpartition(集团KFold = k);% 5倍分层交叉验证partitionedModel = crossval (trainedClassifier CVPartition = c);
计算验证精度。
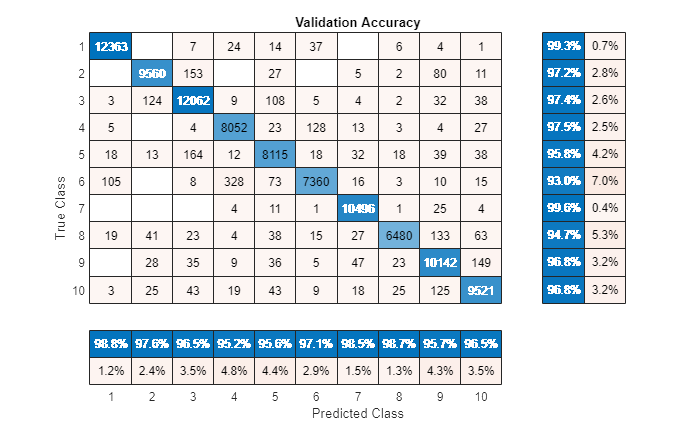
validationAccuracy = 1 - kfoldLoss (partitionedModel LossFun =“ClassifError”);流(' \ nValidation精度= % .2f % % \ n ',validationAccuracy * 100);
验证准确率= 97.69%
图表可视化混乱。
validationPredictions = kfoldPredict (partitionedModel);图(单位=“归一化”位置= [0.4 - 0.4 0.4 - 0.4])confusionchart(标签、validationPredictions title =“验证准确性”,…ColumnSummary =“column-normalized”RowSummary =“row-normalized”);
您还可以使用分类学习者(统计和机器学习的工具箱)应用程序尝试和比较各种分类器与表的功能。
测试分类器
在本节中,您用语音信号从每个测试资讯分类器训练的10个扬声器,看看它如何行为的信号都不是用来训练它。
读文件,从测试集,提取特征和规范化。
特点= [];标签= [];numVectorsPerFile = [];而hasdata (adsTest) [audioIn dsInfo] =阅读(adsTest);%先相同的每个记录加速代码的一部分audioIn = audioIn (1: keepLen);audioIn壮举=提取(afe);(isSpeech =壮举:featureMap.shortTimeEnergy) > energyThreshold;(isVoiced =壮举:featureMap.zerocrossrate) < zcrThreshold;voicedSpeech = isSpeech & isVoiced;壮举(~ voicedSpeech,:) = [];numVec =大小(功绩,1);(的壮举:[featureMap.zerocrossrate featureMap.shortTimeEnergy]) = [];标签= repelem (dsInfo.Label numVec);numVectorsPerFile = [numVectorsPerFile, numVec]; features = [features;feat]; labels = [labels,label];结束特点= (features-M)。/ S;
预测的标签为每个框架通过调用(扬声器)预测在trainedClassifier。
预测=预测(trainedClassifier、特点);预测=分类(string(预测);
图表可视化混乱。
图(单位=“归一化”位置= [0.4 - 0.4 0.4 - 0.4])confusionchart(标签(:),预测、标题=“测试精度(每帧)”,…ColumnSummary =“column-normalized”RowSummary =“row-normalized”);

对于一个给定的文件,预测每一帧。确定预测的模式为每一个文件,然后情节混乱图表。
r2 =预测(1:元素个数(adsTest.Files));idx = 1;为2 = 1:元素个数(adsTest.Files) r2 (ii) =模式(预测(idx: idx + numVectorsPerFile (ii) 1));idx = idx + numVectorsPerFile (ii);结束图(单位=“归一化”位置= [0.4 - 0.4 0.4 - 0.4])confusionchart (adsTest.Labels, r2,标题=“测试精度(每个文件)”,…ColumnSummary =“column-normalized”RowSummary =“row-normalized”);
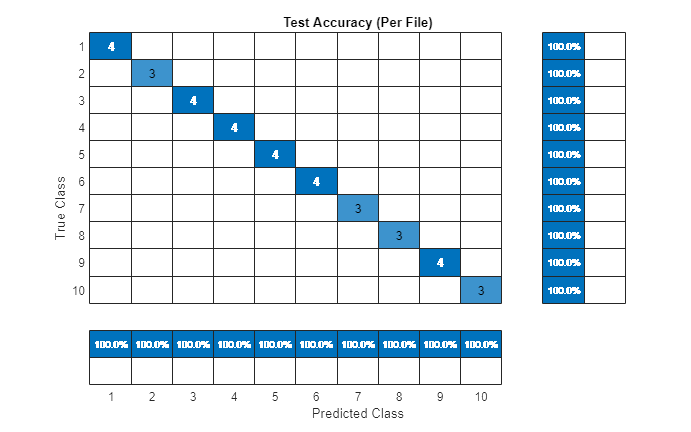
预测喇叭匹配预期的扬声器测试下的所有文件。