最新のリリースでは,このページがまだ翻訳されていません。このページの最新版は英语でご覧になれます。
残差分析
残差のプロットと解析
近似モデルの残差は,各予测子値における応答データと応答データの近似の差として定义されます。
“残差”= “データ”- “近似”
曲线近似アプリで残差を表示するには,ツールバーボタンを选択するか,メニュー项目の[表示],[残差プロット]を选択します。
数学的に,特定の予测子値の残差は応答値ýと予测された応答値ŷの差です。
R =ÿ - ŷ
データを近似するモデルが正しいと仮定すると,残差は确率的误差に近づきます。そのため,残差がランダムに振る舞っているように见える场合,モデルがデータを适切に近似していることを示しています。一方,残差が体系的なパターンを示している场合,それはモデルがデータを适切に近似していないという明白な印です。モデルがデータに対して着しく不适切な场合,信頼限界など,モデル近似の多くの结果は无效であることを常に忘れないでください。
1次多项式近似の残差のグラフ表示を次に示します。上のプロットは,データ点から近似曲线までの垂直距离として残差が计算されることを示しています。下の図は,近似(0のライン)に対する残差を示しています。
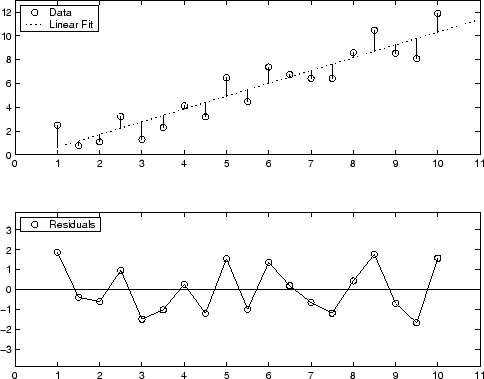
残差はゼロの周りでランダムに散在しているように见え,モデルがデータを适切に说明していることを示しています。
2次多项式近似の残差のグラフ表示を次に示します。このモデルは,2次の项のみを含み,线形项と定数项を含みません。

データ范囲の大部分で残差は体系的に正であり,このモデルがこのデータについて适切な近似ではないことを示しています。
例:残差分析
この例では,いくつかの多项式モデルを使用して生成データを近似し,これらのモデルがどれだけ适切にデータを近似しているか,どれだけ正确に予测できるか评価します。データは3次曲线から生成されたもので,変数Xの范囲内にデータが存在しない大きな隙间があります。
X = [1:0.1:3 9:0.1:10]';C = [2.5 -0.5 1.3 -0.1];。Y = C(1)+ C(2)* X + C(3)* X ^ 2 + C(4)* X ^ 3 +(兰特(大小(X)) - 0.5)。
曲线近似アプリで3次多项式と5次多项式を使用してデータを近似します。データ,近似および残差を以下に示します。曲线近似アプリで[表示],[残差プロット]を选択して残差を表示します。

どちらのモデルもデータを适切に近似し,残差はゼロの周りでランダムに分布しているように见えます。そのため,これらの近似のグラフィカルな评価では,2つの方程式の违いがはっきりとはわかりません。
[结果]ペインで数値的な近似结果を确认し,系数の信頼限界を比较します。
この结果は,3次近似の系数は正确に求められている(范囲が小さい)が,5次近似の系数は正确に求められていないことを示しています。生成データは3次曲线に従うため,予想どおりPOLY3の近似结果が妥当です。近似系数の95%信頼限界は,许容できる范囲で系数が正确であることを示しています一方。poly5の95%信頼限界は,近似系数が正确に求められていないことを示しています。
适合度の统计量は[近似テーブル]に表示されます。既定の设定では,自由度调整済み决定系数とRMSEの统计量がテーブルに表示されます。これらの统计量では,2つの方程式の実质的な违いがわかりません。统计量の表示または非表示を选択するには,列ヘッダーを右クリックします。
新しい観测値の95%非同时予测限界を次に示します。曲线近似アプリで予测限界を表示するには,[ツール],[予测限界],[95%]を选択します。
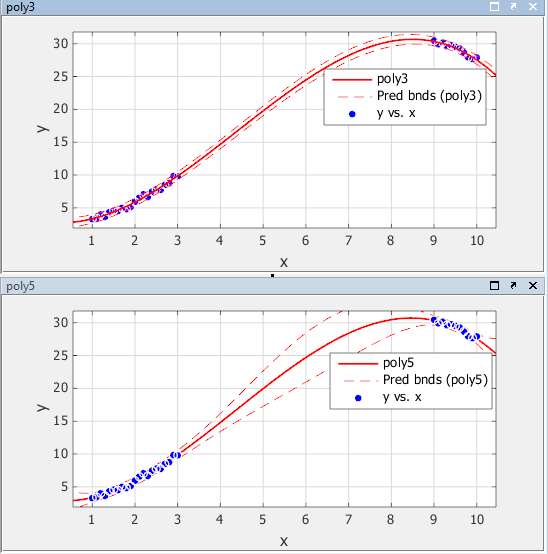
POLY3の予测限界は,データ范囲全体において小さな不确定性で新しい観测値を予测できることを示しています。poly5の场合はそうではありません。データが存在しない领域で予测限界が広くなっています。これは明らかに,高次多项式项を正确に推定できるだけの十分な情报がデータに含まれていないためです。つまり,5次多项式はデータに过适合しています。
poly5を使用した近似关数の95%予测限界を次に示します。これでわかるように,关数の予测の不确定性がデータの中央で大きくなります。そのため,5次多项式を使用して正确に予测するには,より多くのデータを收集しなければならないと结论づけることになります。
结论として,目的に最适な近似であると判断する前に,使用できる适合度による方法をすべて検证する必要があります。最初のアプローチとして必ず,近似と残差をグラフィカルに検证してください。ただし,一部の近似特性は数値的な近似结果,统计量および予测限界からのみ明らかになります。
您还可以选择从下面的列表中的网站:
