GoogLeNetを使用したaapl . exeメ
この例では,事前学習済みの深層畳み込みニューラルネットワークGoogLeNetを使用してイメージを分類する方法を説明します。
100年GoogLeNetは万枚を超えるイメージで学習しており,イメージを1000個のオブジェクトカテゴリ(キーボード,マグカップ,鉛筆,多くの動物など)に分類できます。このネットワクは広範囲にわたるメジにいての豊富な特徴表現を学習しています。このネットワークは入力としてイメージを取り,イメージ内のオブジェクトのラベルを各オブジェクトカテゴリの確率と共に出力します。
事前学習済みのネットワ,クの読み込み
事前学習済みのGoogLeNetネットワ,クを読み込みます。この手順には,深度学习工具箱™模型为GoogLeNet网络サポ,トパッケ,ジが必要です。必要なサポトパッケジがンストルされていない場合,ダウンロド用リンクが表示されます。
。別の事前学習済みネットワークを試すには,この例をMATLAB®で開き,別のネットワークを選択します。たとえば,googlenetよりも高速なネットワ,クであるsqueezenetを試すことができます。この例は,他の事前学習済みネットワ,クを使用して実行することもできます。使用可能なすべてのネットワクにいては,事前学習済みのネットワ,クの読み込みを参照してください。
网= googlenet;
googlenet;

分類するメジのサズは,ネットワクの入力サズと同じでなければなりません。GoogLeNetでは,ネットワ,クの层プロパティの最初の要素は▪▪メ▪▪ジ入力層です。ネットワク入力サズはメジ入力層のInputSizeプロパティです。
inputSize = net.Layers(1).InputSize
inputSize =1×3224 224 3
层プロパティの最後の要素は分類出力層です。この層の一会プロパティには,ネットワ,クによって学習されたクラスの名前が含まれています。合計1000個のクラス名のう10個をランダムに表示します。
classNames = net.Layers(end).ClassNames;numClasses = numel(classNames);disp(类名(randperm (numClasses 10)))
“蝶耳犬”、“蛋酒”、“菠萝蜜”、“城堡”、“睡袋”、“红腿”、“创可贴”、“炒锅”、“安全带”、“橙子”
@ @ @ @ @ @ @ @ @ @ @ @ @ @
分類する▪▪メ▪▪ジを読み取って表示します。
I = imread(“peppers.png”);图imshow(我)

@ @ @ @ @ @ @ @ @ @ @ @ @ @。このメジは384 × 512ピクセルで3のカラチャネル(RGB)があります。
大小(我)
ans =1×3384 512 3
imresize。このサ@ @ズ変更では,@ @メ@ @ジの縦横比が多少変化します。
I = imresize(I,inputSize(1:2));图imshow(我)

用途によっては,異なる方法で@ @ @ジのサ@ @ @ @ @ @ @たとえば,我(1:inputSize (1), 1: inputSize (2):)を使用して,。图像处理工具箱™がある場合は,関数imcropを使用できます。
メ,ジの分類
分类を使用して。このネットワクはメジをピマンとして正しく分類します。分類用のネットワークは,イメージに複数のオブジェクトが含まれていても各入力イメージに対して1つのラベルを出力するように学習されています。
[label,scores] = category (net,I);标签
标签=分类甜椒
。
图imshow(I) title(字符串(标签)+”、“+ num2str(100*scores(classNames == label),3) +“%”);

上位の予測の表示
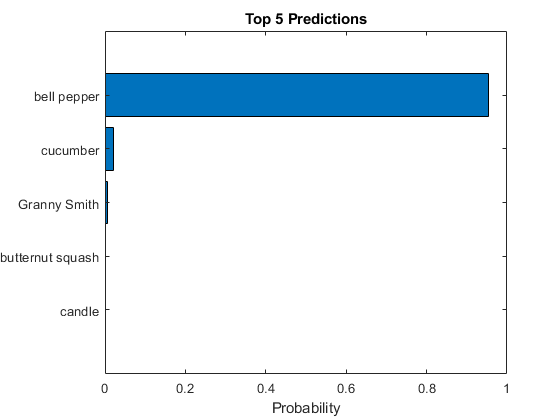
上位5の予測ラベルとそれらに対応する確率をヒストグラムとして表示します。ネットワークはイメージを非常に多くのオブジェクトカテゴリに分類しますが,多くのカテゴリは似ているため,ネットワークを評価するときは,通常,上5位つの精度を考慮します。このネットワクは高い確率でこのメジをピマンとして分類します。
[~,idx] = sort(scores,“下”);Idx = Idx (5:-1:1);classNamesTop = net.Layers(end).ClassNames(idx);scoresTop = scores(idx);图barh(scoresTop) xlim([0 1])“五大预测”)包含(“概率”) yticklabels (classNamesTop)
参照
[1]塞格迪,克里斯蒂安,刘伟,贾扬青,皮埃尔·塞尔曼内,斯科特·里德,德拉戈米尔·安格洛夫,杜米特鲁·埃尔汉,文森特·范豪克和安德鲁·拉宾诺维奇。“更深入地研究卷积。”在IEEE计算机视觉和模式识别会议论文集,第1-9页。2015.
[2] BVLC GoogLeNet模型。https://github.com/BVLC/caffe/tree/master/models/bvlc_googlenet
参考
DAGNetwork|googlenet|分类|预测|squeezenet
関連するトピック
您也可以从以下列表中选择一个网站: