このページの翻訳は最新ではありません。ここをクリックして、英語の最新版を参照してください。
実験マネージャー
深層学習ネットワークの学習および比較に向けた実験の設計と実行
説明
実験マネージャーアプリを使用すると、複数の初期条件でネットワークに学習させ、結果を比較するための深層学習実験を作成できます。たとえば、深層学習実験を使用して次のことができます。
ハイパーパラメーター値の範囲のスイープ、またはベイズ最適化の使用による最適な学習オプションの検出。ベイズ最適化には、Statistics and Machine Learning Toolbox™ が必要です。
組み込み関数
trainNetworkの使用、または独自のカスタム学習関数の定義。さまざまなデータ セットを使用した結果の比較、またはさまざまな深いネットワークのアーキテクチャのテスト。
実験をすばやくセットアップするために、事前構成済みのテンプレートを使用して開始できます。実験テンプレートは、イメージ分類、イメージ回帰、シーケンス分類、セマンティック セグメンテーション、およびカスタム学習ループといったワークフローをサポートします。
実験マネージャーは、学習プロットや混同行列などの可視化ツール、実験結果を絞り込むためのフィルター、および観測結果を記録するための注釈を提供します。再現性を向上させるために、実験マネージャーは、実験を実行するたびに、実験定義のコピーを保存します。過去の実験定義にアクセスして、各結果を生成するハイパーパラメーターの組み合わせを継続的に追跡できます。
その他
実験マネージャーは、実験および結果をプロジェクトに整理します。
同じプロジェクトに複数の実験を保存できる。
各実験には、毎回の実験に対する"結果"のセットが含まれる。
結果の各セットは、ハイパーパラメーターのさまざまな組み合わせに対応する 1 つ以上の"試行"で構成される。
既定では、実験マネージャーは一度に 1 つの試行を実行します。Parallel Computing Toolbox™ がある場合は、複数の GPU、1 つのクラスター、またはクラウドで複数の試行を同時に実行したり、試行を一度に 1 つずつ実行したりするように実験を構成できます。詳細については、実験マネージャーを使用したネットワークの並列学習を参照してください。
[実験ブラウザー]ペインには、プロジェクトの実験と結果の階層が表示されます。たとえば、このプロジェクトには 2 つの実験があり、それぞれにいくつかの結果があります。
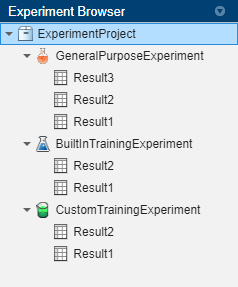
青のフラスコ![]() は、関数
は、関数trainNetworkを使用する組み込みの学習実験を表します。緑のビーカー![]() は、さまざまな学習関数を利用するカスタムの学習実験を表します。実験の構成を開いてその結果を表示するには、実験の名前または結果のセットをダブルクリックします。
は、さまざまな学習関数を利用するカスタムの学習実験を表します。実験の構成を開いてその結果を表示するには、実験の名前または結果のセットをダブルクリックします。

実験マネージャー アプリを開く
MATLAB®ツールストリップ:[アプリ]タブの[機械学習および深層学習]にあるアプリ アイコンをクリックします。
MATLAB コマンド プロンプト:
experimentManagerと入力します。
例
ハイパーパラメーターのスイープによるイメージ分類
この例では、ハイパーパラメーターのスイープによるイメージ分類のために実験テンプレートを使用する方法を示します。このテンプレートを使用すると、関数trainNetworkを使用する組み込みの学習実験をすばやくセットアップできます。実験マネージャーを使用したイメージの分類問題の解決に関するその他の例については、分類用の深層学習実験の作成および実験マネージャーを使用したネットワークの並列学習を参照してください。ハイパーパラメーターをスイープするための代替手法の詳細については、ベイズ最適化を使用した実験ハイパーパラメーターの調整を参照してください。
例を開き、検査と実行が可能な事前構成済みの実験を含むプロジェクトを読み込みます。実験を開くには、[実験ブラウザー]ペインで、実験の名前 (Experiment1) をダブルクリックします。

または、次の手順に従って、自分で実験を構成することもできます。
1.実験マネージャーを開きます。ダイアログ ボックスには、入門チュートリアルや最近使用したプロジェクトへのリンク、新規プロジェクトを作成するボタン、ドキュメンテーション内のサンプルを開くボタンが用意されています。

2.[新規]で[プロジェクト]を選択します。ダイアログ ボックスには、イメージ分類、イメージ回帰、シーケンス分類、セマンティック セグメンテーション、およびカスタム学習ループといったワークフローをサポートするいくつかの実験テンプレートが一覧表示されます。
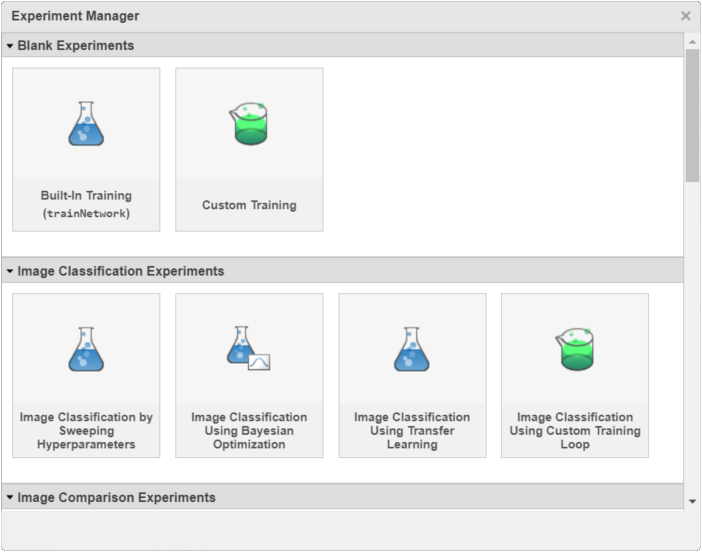
3.[イメージ分類実験]で[ハイパーパラメーターのスイープによるイメージ分類]を選択します。
4.新しいプロジェクトの名前と場所を指定します。実験マネージャーによって、プロジェクトで新しい実験が開きます。[実験]ペインには、実験を定義する説明、ハイパーパラメーター、セットアップ関数、およびメトリクスが表示されます。
5.[説明]フィールドに、実験の説明を次のように入力します。
Classification of digits, using various initial learning rates.
6.[ハイパーパラメーター]で、myInitialLearnRateの値を0.0025:0.0025:0.015に置き換えます。[手法]がExhaustive Sweepに設定されていることを確認します。
7.[セットアップ関数]で[編集]をクリックします。MATLAB エディターでセットアップ関数が開きます。セットアップ関数では、実験用の学習データ、ネットワーク アーキテクチャ、および学習オプションを指定します。この実験のセットアップ関数には 3 つのセクションがあります。
"学習データの読み込み"では、実験用の学習データと検証データを含むイメージ データストアを定義します。実験では、0 ~ 9 の数字から成る 28 x 28 ピクセルのグレースケール イメージ 10,000 個で構成される数字データ セットを使用します。このデータセットの詳細については、イメージ データセットを参照してください。
ネットワーク アーキテクチャの定義では、深層学習による分類用のシンプルな畳み込みニューラル ネットワークのアーキテクチャを定義します。
学習オプションの指定では、実験用の
trainingOptionsmyInitialLearnRateエントリから初期学習率の値を読み込みます。
実験を実行すると、実験マネージャーはセットアップ関数で定義されたネットワークに 6 回学習させます。各試行で、ハイパーパラメーター テーブルで指定された学習率の 1 つが使用されます。既定では、実験マネージャーは一度に 1 つの試行を実行します。Parallel Computing Toolbox がある場合は、複数の試行を同時に実行できます。最良の結果を得るには、実験を実行する前に、GPU と同じ数のワーカーで並列プールを起動します。詳細については、実験マネージャーを使用したネットワークの並列学習とリリース別の GPU サポート(Parallel Computing Toolbox)を参照してください。
一度に 1 つの実験の試行を実行するには、[実験マネージャー] ツールストリップで[実行]をクリックします。
複数の試行を同時に実行するには、[並列の使用]、[実行]の順にクリックします。現在の並列プールがない場合、実験マネージャーは既定のクラスター プロファイルを使用して並列プールを起動します。次に、実験マネージャーは、使用可能な並列ワーカーの数に応じて、複数の同時試行を実行します。
結果テーブルに、各試行の精度と損失が表示されます。

実験の実行中に[学習プロット]をクリックすると、学習プロットが表示され、各試行の進行状況を追跡できます。MATLAB コマンド ウィンドウで学習の進行状況を監視することもできます。

[混同行列]をクリックし、完了した各試行の検証データの混同行列を表示します。

実験の完了後、列ごとにテーブルを並べ替えたり、[フィルター]ペインを使用して試行をフィルター処理したりできます。結果テーブルに注釈を追加して、観測結果を記録することもできます。詳細については、実験結果の並べ替え、フィルター処理、および注釈追加を参照してください。
各試行の性能をテストするには、試行で使用した学習済みネットワークまたは試行の学習情報をエクスポートします。[実験マネージャー]ツールストリップで、[エクスポート]、[学習済みネットワーク]を選択するか、[エクスポート]、[学習情報]を選択します。詳細については、netおよびinfoを参照してください。
実験を閉じるには、[実験ブラウザー]ペインでプロジェクトの名前を右クリックし、[プロジェクトを閉じる]を選択します。実験マネージャーによって,プロジェクトに含まれるすべての実験と結果が閉じられます。
ハイパーパラメーターのスイープによるイメージ回帰
この例では、ハイパーパラメーターのスイープによるイメージ回帰のために実験テンプレートを使用する方法を示します。このテンプレートを使用すると、関数trainNetworkを使用する組み込みの学習実験をすばやくセットアップできます。実験マネージャーを使用した回帰問題の解決に関する他の例については、回帰用の深層学習実験の作成を参照してください。ハイパーパラメーターをスイープするための代替手法の詳細については、ベイズ最適化を使用した実験ハイパーパラメーターの調整を参照してください。
例を開き、検査と実行が可能な事前構成済みの実験を含むプロジェクトを読み込みます。実験を開くには、[実験ブラウザー]ペインで、実験の名前 (Experiment1) をダブルクリックします。

または、次の手順に従って、自分で実験を構成することもできます。
1.実験マネージャーを開きます。ダイアログ ボックスには、入門チュートリアルや最近使用したプロジェクトへのリンク、新規プロジェクトを作成するボタン、ドキュメンテーション内のサンプルを開くボタンが用意されています。
2.[新規]で[プロジェクト]を選択します。ダイアログ ボックスには、イメージ分類、イメージ回帰、シーケンス分類、セマンティック セグメンテーション、およびカスタム学習ループといったワークフローをサポートするいくつかの実験テンプレートが一覧表示されます。
3.[イメージ回帰実験]で[ハイパーパラメーターのスイープによるイメージ回帰]を選択します。
4.新しいプロジェクトの名前と場所を指定します。実験マネージャーによって、プロジェクトで新しい実験が開きます。[実験]ペインには、実験を定義する説明、ハイパーパラメーター、セットアップ関数、およびメトリクスが表示されます。
5.[説明]フィールドに、実験の説明を次のように入力します。
Regression to predict angles of rotation of digits, using various initial learning rates.
6.[ハイパーパラメーター]で、myInitialLearnRateの値を0.001:0.001:0.006に置き換えます。[手法]がExhaustive Sweepに設定されていることを確認します。
7.[セットアップ関数]で[編集]をクリックします。MATLAB エディターでセットアップ関数が開きます。セットアップ関数では、実験用の学習データ、ネットワーク アーキテクチャ、および学習オプションを指定します。この実験のセットアップ関数には 3 つのセクションがあります。
学習データの読み込みでは、実験用の学習データと検証データを 4 次元配列として定義します。学習データと検証データはそれぞれ数字データ セットからの 5000 枚のイメージで構成されています。各イメージは 0 ~ 9 の数字で、特定の角度の回転が付けられています。回帰値は、回転角度に対応しています。このデータセットの詳細については、イメージ データセットを参照してください。
"ネットワーク アーキテクチャの定義"では、深層学習による回帰用のシンプルな畳み込みニューラル ネットワークのアーキテクチャを定義します。
学習オプションの指定では、実験用の
trainingOptionsmyInitialLearnRateエントリから初期学習率の値を読み込みます。
実験を実行すると、実験マネージャーはセットアップ関数で定義されたネットワークに 6 回学習させます。各試行で、ハイパーパラメーター テーブルで指定された学習率の 1 つが使用されます。既定では、実験マネージャーは一度に 1 つの試行を実行します。Parallel Computing Toolbox がある場合は、複数の試行を同時に実行できます。最良の結果を得るには、実験を実行する前に、GPU と同じ数のワーカーで並列プールを起動します。詳細については、実験マネージャーを使用したネットワークの並列学習とリリース別の GPU サポート(Parallel Computing Toolbox)を参照してください。
一度に 1 つの実験の試行を実行するには、[実験マネージャー] ツールストリップで[実行]をクリックします。
複数の試行を同時に実行するには、[並列の使用]、[実行]の順にクリックします。現在の並列プールがない場合、実験マネージャーは既定のクラスター プロファイルを使用して並列プールを起動します。次に、実験マネージャーは、使用可能な並列ワーカーの数に応じて、複数の同時試行を実行します。
結果テーブルに、各試行の平方根平均二乗誤差 (RMSE) と損失が表示されます。

実験の実行中に[学習プロット]をクリックすると、学習プロットが表示され、各試行の進行状況を追跡できます。MATLAB コマンド ウィンドウで学習の進行状況を監視することもできます。

実験の完了後、列ごとにテーブルを並べ替えたり、[フィルター]ペインを使用して試行をフィルター処理したりできます。結果テーブルに注釈を追加して、観測結果を記録することもできます。詳細については、実験結果の並べ替え、フィルター処理、および注釈追加を参照してください。
各試行の性能をテストするには、試行で使用した学習済みネットワークまたは試行の学習情報をエクスポートします。[実験マネージャー]ツールストリップで、[エクスポート]、[学習済みネットワーク]を選択するか、[エクスポート]、[学習情報]を選択します。詳細については、netおよびinfoを参照してください。
実験を閉じるには、[実験ブラウザー]ペインでプロジェクトの名前を右クリックし、[プロジェクトを閉じる]を選択します。実験マネージャーによって,プロジェクトに含まれるすべての実験と結果が閉じられます。
カスタム学習ループを使用したイメージ分類
この例では、カスタム学習ループを使用したイメージ分類のために学習実験テンプレートを使用する方法を示します。このテンプレートを使用すると、カスタムの学習実験をすばやくセットアップできます。
例を開き、検査と実行が可能な事前構成済みの実験を含むプロジェクトを読み込みます。実験を開くには、[実験ブラウザー]ペインで、実験の名前 (Experiment1) をダブルクリックします。

または、次の手順に従って、自分で実験を構成することもできます。
1.実験マネージャーを開きます。ダイアログ ボックスには、入門チュートリアルや最近使用したプロジェクトへのリンク、新規プロジェクトを作成するボタン、ドキュメンテーション内のサンプルを開くボタンが用意されています。
2.[新規]で[プロジェクト]を選択します。ダイアログ ボックスには、イメージ分類、イメージ回帰、シーケンス分類、セマンティック セグメンテーション、およびカスタム学習ループといったワークフローをサポートするいくつかの実験テンプレートが一覧表示されます。
3.[イメージ分類実験]で[カスタム学習ループを使用したイメージ分類]を選択します。
4.新しいプロジェクトの場所と名前を選択します。実験マネージャーによって、プロジェクトで新しい実験が開きます。[実験]ペインには、実験を定義する説明、ハイパーパラメーター、および学習関数が表示されます。
3.[説明]フィールドに、実験の説明を次のように入力します。
Classification of digits, using various initial learning rates.
4.[ハイパーパラメーター]で、myInitialLearnRateの値を0.0025:0.0025:0.015に置き換えます。[手法]がExhaustive Sweepに設定されていることを確認します。
5.[学習関数]で[編集]をクリックします。MATLAB エディターで学習関数が開きます。学習関数では、実験で使用される学習データ、ネットワーク アーキテクチャ、学習オプション、および学習手順を指定します。この実験の学習関数には 4 つのセクションがあります。
"学習データの読み込み"では、実験用の学習データを 4 次元配列として定義します。実験では、0 ~ 9 の数字から成る 28 x 28 ピクセルのグレースケール イメージ 5,000 個で構成される数字データ セットを使用します。このデータセットの詳細については、イメージ データセットを参照してください。
ネットワーク アーキテクチャの定義では、深層学習による分類用のシンプルな畳み込みニューラル ネットワークのアーキテクチャを定義します。カスタム学習ループを使用してネットワークに学習させるため、この学習関数はネットワークを
dlnetworkオブジェクトとして表現します。"学習オプションの指定"では、実験で使用される学習オプションを定義します。この実験の学習関数では、ハイパーパラメーター テーブルの
myInitialLearnRateエントリから初期学習率の値を読み込みます。"モデルの学習"では、実験で使用されるカスタム学習ループを定義します。カスタム学習ループでは、各エポックについて、データをシャッフルしてデータのミニバッチを繰り返し実行します。カスタム学習ループでは、各ミニバッチについて、モデルの勾配、状態、および損失を評価し、時間ベースの減衰学習率スケジュールの学習率を決定し、ネットワーク パラメーターを更新します。学習の進行状況を追跡して学習損失の値を記録するため、この学習関数は
experiments.Monitorオブジェクトmonitorを使用します。
実験を実行すると、実験マネージャーは学習関数で定義されたネットワークに 6 回学習させます。各試行で、ハイパーパラメーター テーブルで指定された学習率の 1 つが使用されます。既定では、実験マネージャーは一度に 1 つの試行を実行します。Parallel Computing Toolbox がある場合は、複数の試行を同時に実行できます。最良の結果を得るには、実験を実行する前に、GPU と同じ数のワーカーで並列プールを起動します。詳細については、実験マネージャーを使用したネットワークの並列学習とリリース別の GPU サポート(Parallel Computing Toolbox)を参照してください。
一度に 1 つの実験の試行を実行するには、[実験マネージャー] ツールストリップで[実行]をクリックします。
複数の試行を同時に実行するには、[並列の使用]、[実行]の順にクリックします。現在の並列プールがない場合、実験マネージャーは既定のクラスター プロファイルを使用して並列プールを起動します。次に、実験マネージャーは、使用可能な並列ワーカーの数に応じて、複数の同時試行を実行します。
結果テーブルに、各試行の学習損失が表示されます。

実験の実行中に[学習プロット]をクリックすると、学習プロットが表示され、各試行の進行状況を追跡できます。

実験の完了後、列ごとにテーブルを並べ替えたり、[フィルター]ペインを使用して試行をフィルター処理したりできます。結果テーブルに注釈を追加して、観測結果を記録することもできます。詳細については、実験結果の並べ替え、フィルター処理、および注釈追加を参照してください。
各試行の性能をテストするには、試行における学習の出力をエクスポートします。[実験マネージャー]ツールストリップで[エクスポート]を選択します。この実験の学習の出力は、学習損失の値と学習済みネットワークを含む構造体です。
実験を閉じるには、[実験ブラウザー]ペインでプロジェクトの名前を右クリックし、[プロジェクトを閉じる]を選択します。実験マネージャーによって,プロジェクトに含まれるすべての実験と結果が閉じられます。
組み込みの学習実験の構成
この例では、実験マネージャー アプリを使用して組み込みの学習実験を設定する方法を示します。組み込みの学習実験は、関数trainNetworkによって、イメージ分類、イメージ回帰、シーケンス分類、セマンティック セグメンテーションといったワークフローをサポートします。
組み込みの学習実験は、説明、ハイパーパラメーターのテーブル、セットアップ関数、および実験の結果を評価するためのメトリクス関数の集合で構成されます。
[説明]フィールドに実験の説明を入力します。
[ハイパーパラメーター]で、実験に使用する手法を選択します。
ハイパーパラメーター値の範囲をスイープするには、[手法]を
[網羅的なスイープ]に設定します。ハイパーパラメーター テーブルで、実験で使用されるハイパーパラメーターの値を指定します。ハイパーパラメーター値は、数値、logical 値、または string 値をもつスカラーまたはベクトルとして指定できます。たとえば、以下のようなハイパーパラメーターの指定が有効です。0.010.01:0.01:0.05[0.01 0.02 0.04 0.08]["sgdm" "rmsprop" "adam"]
実験を実行すると、実験マネージャーは、テーブルで指定されたハイパーパラメーター値のすべての組み合わせを使用してネットワークに学習させます。
ベイズ最適化を使用して最適な学習オプションを見つけるには、[手法]を
[ベイズ最適化]に設定します。ハイパーパラメーターテーブルで,実験で使用される次のハイパーパラメーターのプロパティを指定します。範囲— 実数値または整数値のハイパーパラメーターの下限と上限を示す 2 要素のベクトル、または categorical ハイパーパラメーターが取り得る値をリストする string 配列または cell 配列を入力します。
型—
[実数](実数値のハイパーパラメーター)、[整数](整数値のハイパーパラメーター)、または[categorical](categorical ハイパーパラメーター) を選択します。変換—
[なし](変換なし) または[対数](対数変換) を選択します。[対数]の場合、ハイパーパラメーターは[実数]または[整数]で正でなければなりません。このオプションを使用すると、ハイパーパラメーターが検索され、対数スケールでモデル化されます。
実験を実行すると、実験マネージャーはハイパーパラメーターの最適な組み合わせを検索します。実験の各試行では、前の試行の結果に基づいてハイパーパラメーター値の新しい組み合わせが使用されます。
実験の期間を指定するには、[ベイズ最適化オプション]で、実行する最大時間 (秒単位) と最大試行回数を入力します。実験マネージャーは試行完了時にのみこれらのオプションをチェックするため、実験における実際の実行時間と試行回数はこれらの設定値を超える場合があることに注意してください。
ベイズ最適化には、Statistics and Machine Learning Toolbox が必要です。詳細については、ベイズ最適化を使用した実験ハイパーパラメーターの調整を参照してください。
[セットアップ関数]は、実験用の学習データ、ネットワーク アーキテクチャ、および学習オプションを構成します。セットアップ関数への入力は、ハイパーパラメーター テーブルのフィールドをもつ構造体です。セットアップ関数の出力は、関数trainNetworkの入力と一致しなければなりません。以下の表は、セットアップ関数でサポートされているシグネチャの一覧です。
| 実験の目的 | セットアップ関数のシグネチャ |
|---|---|
imagesで指定したイメージと応答、およびoptionsで定義した学習オプションを使用して、イメージ分類タスクとイメージ回帰タスクのためのネットワークに学習させます。 |
function[images,layers,options] = Experiment_setup(params)...end |
imagesで指定したイメージ、およびresponsesで指定した応答を使用してネットワークに学習させます。 |
function[images,responses,layers,options] = Experiment_setup(params)...end |
sequencesで指定したシーケンスと応答を使用して、シーケンス分類タスク、時系列分類タスク、および回帰タスクのためのネットワーク (LSTM ネットワークや GRU ネットワークなど) に学習させます。 |
function[sequences,layers,options] = Experiment_setup(params)...end |
sequencesで指定したシーケンス、およびresponsesで指定した応答を使用してネットワークに学習させます。 |
function[sequences,reponses,layers,options] = Experiment_setup(params)...end |
featuresで指定した特徴データと応答を使用して、特徴分類タスクまたは回帰タスクのためのネットワーク (多層パーセプトロン (MLP) ネットワークなど) に学習させます。 |
function[features,layers,options] = Experiment_setup(params)...end |
featuresで指定した特徴データ、およびresponsesで指定した応答を使用してネットワークに学習させます。 |
function[features,responses,layers,options] = Experiment_setup(params)...end |
メモ
学習オプションExecutionEnvironmentを"multi-gpu"または"parallel"に設定するか、学習オプションDispatchInBackgroundを有効にした場合、実験マネージャーは複数の試行の並列実行をサポートしません。実験の試行を一度に 1 つずつ実行する場合にのみ、これらのオプションを使用して学習を高速化するようにしてください。詳細については、実験マネージャーを使用したネットワークの並列学習を参照してください。
[メトリクス]セクションは、実験結果を評価するための関数を指定します。メトリクス関数への入力は、以下の 3 つのフィールドをもつ構造体です。
trainedNetworkは、関数trainNetworkによって返されるSeriesNetworkオブジェクトまたはDAGNetworkオブジェクトです。詳細については、学習済みネットワークを参照してください。trainingInfoは、関数trainNetworkによって返される学習情報を含む構造体です。詳細については、学習に関する情報を参照してください。parametersは、ハイパーパラメーター テーブルのフィールドをもつ構造体です。
メトリクス関数の出力は、スカラー数、logical 値、または string でなければなりません。
実験でベイズ最適化を使用する場合は、[最適化]リストから最適化するメトリクスを選択します。[方向]リストで、このメトリクスの[最大化]または[最小化]を指定します。実験マネージャーは、このメトリクスを使用して、実験に最適なハイパーパラメーターの組み合わせを決定します。学習または検証の標準的メトリクス (精度、RMSE、損失など) を選択することも、テーブルからカスタム メトリクスを選択することもできます。
カスタムの学習実験の構成
この例では、実験マネージャー アプリを使用してカスタムの学習実験を設定する方法を示します。カスタムの学習実験は、trainNetwork以外の学習関数を必要とするワークフローをサポートします。このワークフローには次が含まれます。
層グラフによって定義されていないネットワークの学習。
カスタム学習率スケジュールを使用した、ネットワークの学習。
カスタム関数を使用した、ネットワークの学習可能パラメーターの更新。
敵対的生成ネットワーク (GAN) の学習。
シャム ネットワークの学習。
カスタムの学習実験は、説明、ハイパーパラメーターのテーブル、および学習関数で構成されます。
[説明]フィールドに実験の説明を入力します。
[ハイパーパラメーター]で、実験に使用する手法を選択します。
ハイパーパラメーター値の範囲をスイープするには、[手法]を
[網羅的なスイープ]に設定します。ハイパーパラメーター テーブルで、実験で使用されるハイパーパラメーターの値を指定します。ハイパーパラメーター値は、数値、logical 値、または string 値をもつスカラーまたはベクトルとして指定できます。たとえば、以下のようなハイパーパラメーターの指定が有効です。0.010.01:0.01:0.05[0.01 0.02 0.04 0.08]["sgdm" "rmsprop" "adam"]
実験を実行すると、実験マネージャーは、テーブルで指定されたハイパーパラメーター値のすべての組み合わせを使用してネットワークに学習させます。
ベイズ最適化を使用して最適な学習オプションを見つけるには、[手法]を
[ベイズ最適化]に設定します。ハイパーパラメーターテーブルで,実験で使用される次のハイパーパラメーターのプロパティを指定します。範囲— 実数値または整数値のハイパーパラメーターの下限と上限を示す 2 要素のベクトル、または categorical ハイパーパラメーターが取り得る値をリストする string 配列または cell 配列を入力します。
型—
[実数](実数値のハイパーパラメーター)、[整数](整数値のハイパーパラメーター)、または[categorical](categorical ハイパーパラメーター) を選択します。変換—
[なし](変換なし) または[対数](対数変換) を選択します。[対数]の場合、ハイパーパラメーターは[実数]または[整数]で正でなければなりません。このオプションを使用すると、ハイパーパラメーターが検索され、対数スケールでモデル化されます。
実験を実行すると、実験マネージャーはハイパーパラメーターの最適な組み合わせを検索します。実験の各試行では、前の試行の結果に基づいてハイパーパラメーター値の新しい組み合わせが使用されます。
実験の期間を指定するには、[ベイズ最適化オプション]で、実行する最大時間 (秒単位) と最大試行回数を入力します。実験マネージャーは試行完了時にのみこれらのオプションをチェックするため、実験における実際の実行時間と試行回数はこれらの設定値を超える場合があることに注意してください。
ベイズ最適化には、Statistics and Machine Learning Toolbox が必要です。詳細については、在定制培训擅长使用贝叶斯优化imentsを参照してください。
[学習関数]では、実験で使用される学習データ、ネットワーク アーキテクチャ、学習オプション、および学習手順を指定します。学習関数への入力は以下のとおりです。
ハイパーパラメーター テーブルのフィールドをもつ構造体
学習の進行状況を追跡し、結果テーブルで情報フィールドを更新し、学習で使用したメトリクスの値を記録し、学習プロットを生成するために使用できる
experiments.Monitorオブジェクト
学習マネージャーでは学習関数の出力が保存されるため、学習完了時にこの出力を MATLAB ワークスペースにエクスポートできます。
メモ
実験の結果テーブルでは、情報列とメトリクス列の両方に数値が表示されます。さらに、メトリクス値が学習プロットに記録されます。結果テーブルには表示する必要があるものの学習プロットには表示したくないと考えている値については、情報列を使用してください。
実験でベイズ最適化を使用する場合は、[最適化]の[メトリクス]セクションで最適化するメトリクスの名前を入力します。[方向]リストで、このメトリクスの[最大化]または[最小化]を指定します。実験マネージャーは、このメトリクスを使用して、実験に最適なハイパーパラメーターの組み合わせを決定します。experiments.Monitorを使用して学習関数用に定義した任意のメトリクスを選択できます。
学習の停止と再開
実験マネージャーでは、実験を中断するための 2 つのオプションが用意されています。
 [停止]は、実行中の試行を
[停止]は、実行中の試行を[停止]とマークし、その結果を保存します。実験停止後、この試行に関する学習プロットを表示することや学習の出力をエクスポートすることができます。 [キャンセル]は、実行中の試行を
[キャンセル]は、実行中の試行を[キャンセル済み]とマークし、その結果を破棄します。実験停止後に、この試行に関する学習プロットを表示することや学習の出力をエクスポートすることはできません。
どちらのオプションでも、完了した試行の結果が保存され、キューに登録されている試行がキャンセルされます。通常、[キャンセル]のほうが[停止]よりも高速で処理されます。
実験を停止する代わりに、実行中の試行を個別に停止することや、キューに登録されている試行を個別にキャンセルすることができます。結果テーブルの[進行状況]列で、試行の停止ボタン![]() またはキャンセル ボタン
またはキャンセル ボタン![]() をクリックします。
をクリックします。

学習が完了すれば、停止またはキャンセルした試行を再開できます。結果テーブルの[進行状況]列で、試行の再開ボタン![]() をクリックします。
をクリックします。

あるいは、[実験マネージャー] ツールストリップで[キャンセル済みをすべて再開]![]() をクリックすることで、キャンセルした試行をまとめて再開することもできます。
をクリックすることで、キャンセルした試行をまとめて再開することもできます。
メモ
ベイズ最適化を使用する実験は、[キャンセル]オプションのみをサポートします。さらに、これらの実験はキャンセルした試行の再開をサポートしていません。
網羅的なスイープを使用するカスタムの学習実験は、[停止]オプションのみをサポートします。
実験結果の並べ替え、フィルター処理、および注釈追加
この例では、実験を実行した後に結果を比較したり観測結果を記録したりする方法を示します。
実験を実行すると、実験マネージャーはセットアップ関数で定義されたネットワークに複数回学習させます。試行ごとに、ハイパーパラメーターの異なる組み合わせが使用されます。実験が終了すると、各試行の学習メトリクスおよび検証メトリクス (精度、RMSE、損失など) がテーブルに表示されます。実験の結果を比較するため、これらのメトリクスを使用して、結果テーブルを並べ替えたり、試行をフィルター処理したりできます。
結果テーブルで試行を並べ替えるには、学習メトリクスまたは検証メトリクスに対応する列のドロップダウン メニューを使用します。
並べ替える列のヘッダーをポイントします。
三角形のアイコンをクリックします。
[昇順で並べ替え]または[降順で並べ替え]を選択します。


結果テーブルから試行をフィルター処理するには、[フィルター]ペインを使用します。
[実験マネージャー]ツールストリップで、[フィルター]を選択します。
[フィルター]ペインに、結果テーブルの数値メトリクスのヒストグラムが表示されます。[フィルター]ペインからヒストグラムを削除するには、結果テーブルで、対応する列のドロップダウン メニューを開き、[フィルターの表示]チェック ボックスをオフにします。
フィルター処理する学習メトリクスまたは検証メトリクスのヒストグラムの下にあるスライダーを調整します。

結果テーブルには、選択した範囲のメトリクス値をもつ試行のみが表示されます。

結果テーブルのすべての試行を復元するには、[Experiment Result]ペインを閉じ、[実験ブラウザー]ペインから結果を再度開きます。


実験結果に関する観測結果を記録するには、注釈を追加します。
結果テーブルのセルを右クリックし、[注釈の追加]を選択します。あるいは、結果テーブルでセルを選択し、[実験マネージャー] ツールストリップで[注釈]、[注釈の追加]を選択します。

[注釈]ペインで、テキスト ボックスに観測結果を入力します。

結果テーブルの各セルに複数の注釈を追加できます。注釈にはそれぞれタイム スタンプが付いています。
注釈に対応するセルを強調表示するには,注釈の上にあるリンクをクリックします。


[注釈]ペインを開いてすべての注釈を表示するには、[実験マネージャー] ツールストリップで[注釈]、[注釈の表示]を選択します。
過去の実験定義のソースの表示
この例では、特定の結果を生成した実験の構成を検査する方法を示します。
実験を実行した後、[Experiment ソース]ペインを開いて、実験の説明とハイパーパラメーター テーブルの読み取り専用コピー、および実験によって使用されたすべての関数へのリンクを表示できます。このペインの情報を使用して、各結果を生成するデータ、ネットワーク、および学習オプションの構成を追跡できます。
たとえば、実験を複数回実行するとします。実験を実行するたびに、セットアップ関数の内容を変更しますが、関数名は常に同じものを使用します。最初に実験を実行するときは、イメージ分類用の実験テンプレートによって提供される既定のネットワークを使用します。2 回目に実験を実行するときは、セットアップ関数を変更して、事前学習済みの GoogLeNet ネットワークを読み込み、最終層を転移学習用の新しい層に置き換えます。これら 2 つのネットワーク アーキテクチャを使用する例については、分類用の深層学習実験の作成を参照してください。
最初の[Experiment Result]ペインで、[実験のソースの表示]リンクをクリックします。実験マネージャーは、最初の結果セットを生成した実験の定義を含む[Experiment ソース]ペインを開きます。ペインの下部にあるリンクをクリックして、最初の実験の実行時に使用したセットアップ関数を開きます。このセットアップ関数をコピーし、シンプルな分類ネットワークを使用して実験を再実行できます。
2 番目の[Experiment Result]ペインで、[実験のソースの表示]リンクをクリックします。実験マネージャーは、2 番目の結果セットを生成した実験の定義を含む[Experiment ソース]ペインを開きます。ペインの下部にあるリンクをクリックして、2 回目の実験の実行時に使用したセットアップ関数を開きます。このセットアップ関数をコピーし、転移学習を使用して実験を再実行できます。
使用するすべての関数のコピーが実験マネージャーによって保存されるため、実験を変更して再実行するときに、これらの関数の名前を手動で変更する必要はありません。
関連する例
- 分類用の深層学習実験の作成
- 回帰用の深層学習実験の作成
- メトリクス関数を使用した深層学習実験の評価
- ベイズ最適化を使用した実験ハイパーパラメーターの調整
- 在定制培训擅长使用贝叶斯优化iments
- 転移学習用の事前学習済みのネットワークを複数試用
- 転移学習用の重み初期化子を使用した実験
- Choose Training Configurations for LSTM Using Bayesian Optimization
- Run a Custom Training Experiment for Image Comparison
- Use Experiment Manager to Train Generative Adversarial Networks (GANs)
ヒント
ハイパーパラメーターをスイープせずにネットワークの可視化、構築、学習を行うには、ディープ ネットワーク デザイナーアプリを使用します。ネットワークに学習させた後、深層学習実験の開始点として使用するスクリプトを生成します。詳細については、Generate Experiment Using Deep Network Designerを参照してください。
MATLAB Online を使用して実験を並列実行するには、Cloud Center クラスターにアクセスできなければなりません。詳細については、MATLAB Online における Cloud Center クラスターとの Parallel Computing Toolbox の使用(Parallel Computing Toolbox)を参照してください。
マウスを使用できない環境で実験マネージャーを操作するには、キーボード ショートカットを使用します。詳細については、Keyboard Shortcuts for Experiment Managerを参照してください。
バージョン履歴
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)