使用强化学习调节PI控制器
这个例子展示了如何使用双延迟深层确定性策略梯度(TD3)强化学习算法对PI控制器进行优化,并将优化后的控制器的性能与使用控制系统调谐器应用程序。使用控制系统调谐器在Simulink®中调整控制器的应用程序需要Simu万博1manbetxlink控制设计™ 软件
对于具有少量可调参数的相对简单的控制任务,与基于无模型的RL方法相比,基于模型的调整技术可以获得更快的调整过程,并获得良好的结果。然而,RL方法更适合于高度非线性系统或自适应控制器的调整。
为了便于控制器比较,两种调谐方法都使用线性二次高斯(LQG)目标函数。
此示例使用强化学习(RL)代理计算PI控制器的增益。有关使用神经网络控制器替换PI控制器的示例,请参阅创建Simul万博1manbetxink环境并训练Agent.
环境模型
本例中的环境模型是水箱模型。该控制系统的目标是保持水箱中的水位与参考值相匹配。
开放式系统(“水箱LQG”)

该模型包含带方差的过程噪声 .
保持水位,同时尽量减少控制工作U,此示例中的控制器使用以下LQG标准。
要在此模型中模拟控制器,必须指定模拟时间Tf控制器采样时间Ts几秒钟之内。
Ts=0.1;Tf=10;
有关水箱模型的详细信息,请参见水箱Simulink万博1manbetx模型(万博1manbetxSimulink控制设计).
使用控制系统调谐器调整PI控制器
使用在Simulink中调整控制器的步骤万博1manbetx控制系统调谐器,必须将控制器块指定为优化块,并定义优化过程的目标。有关使用控制系统调谐器看见使用控制系统调谐器调整控制系统(万博1manbetxSimulink控制设计).
对于本例,请打开保存的会话ControlSystemTunerSession.mat使用控制系统调谐器。此会话指定中的PID控制器块水箱模型作为一个调整的块,并包含一个LQG调整目标。
控制系统调谐器(“ControlSystemTunerSession”)
要调整控制器,请在调谐选项卡,单击曲调.
调谐的比例增益和积分增益分别约为9.8和1e-6。
Kp_CST=9.801999804512;Ki_CST=1.00019996230706e-06;
为培训代理创造环境
要定义训练RL代理的模型,请使用以下步骤修改水箱模型。
删除PID控制器。
插入RL代理块。
创建观察向量 哪里 , 是油箱的高度,以及 是参考高度。将观察信号连接到RL代理块。
将RL代理的奖励函数定义为消极的在LQG成本中,也就是, .RL代理将此奖励最大化,从而最小化LQG成本。
由此产生的模型是rlwatertankPIDTune.slx.
mdl=“rlwatertankPIDTune”; 开放式系统(mdl)

创建环境接口对象。为此,请使用localCreatePIDEnv函数的定义。
[env,obsInfo,actInfo]=localCreatePIDEnv(mdl);
提取此环境的观察和行动维度。
numObservations=obsInfo.Dimension(1);数量=产品(活动尺寸);
修复随机生成器种子以获得再现性。
rng(0)
创建TD3代理
给定观察结果,TD3代理使用参与者表示来决定要执行的操作。要创建参与者,请首先使用观察输入和操作输出创建一个深度神经网络。有关更多信息,请参阅决定论呈现.
您可以将PI控制器建模为一个神经网络,其中有一个完全连接的层,具有误差和误差积分观测值。
在这里:
U是actor神经网络的输出。金伯利进程和碘化钾是神经网络权重的绝对值。, 是油箱的高度,以及 为参考高度。
梯度下降优化可以使权重为负值。为避免负权重,请替换正常权重完全连接层用一个完全连接的Pilayer。此层通过实现函数确保权重为正
。此层在中定义完全连接的Pilayer.m.
initialGain=single([1e-3 2]);actorNetwork=[featureInputLayer(numObservations,“正常化”,“没有”,“姓名”,“国家”) fullyConnectedPILayer (initialGain“行动”)];actorOptions=rlRepresentationOptions(“LearnRate”,1e-3,“梯度阈值”,1);actor=rlDeterministicActorRepresentation(actorNetwork、obsInfo、actInfo、,...“观察”,{“国家”},“行动”,{“行动”},动植物);
TD3代理使用两个临界值函数表示法来近似给定观察和行动的长期回报。要创建临界值,首先创建一个包含两个输入、观察和行动以及一个输出的深度神经网络。有关创建深度神经网络值函数表示法的更多信息,请参阅创建策略和值函数表示.
要创建批评者,请使用localCreateCriticNetwork本例末尾定义的函数。对两种表示使用相同的网络结构。
criticNetwork=localCreateCriticNetwork(numObservations,numActions);criticOpts=rlRepresentationOptions(“LearnRate”,1e-3,“梯度阈值”,1);临界C1=rlQValueRepresentation(临界网络、obsInfo、actInfo、,...“观察”,“国家”,“行动”,“行动”,criticOpts);critic2=rlQValueRepresentation(criticNetwork、obsInfo、actInfo、,...“观察”,“国家”,“行动”,“行动”,criticOpts);批评家=[critic1 critic2];
使用以下选项配置代理。
将代理设置为使用控制器采样时间
Ts.将小批量大小设置为128个经验样本。
将体验缓冲区长度设置为1e6。
将探索模型和目标策略平滑模型设置为使用方差为0.1的高斯噪声。
使用指定TD3代理选项rlTD3AgentOptions.
agentOpts=rlTD3AgentOptions(...“采样时间”,Ts,...“MiniBatchSize”,128,...“经验缓冲长度”,1e6);agentOpts.ExplorationModel.Variance=0.1;agentOpts.TargetPolicySmoothModel.Variance=0.1;
使用指定的参与者表示、评论家表示和代理选项创建TD3代理。有关详细信息,请参阅rlTD3AgentOptions.
代理=RLTD3代理(演员、评论家、代理);
列车员
要培训代理,请首先指定以下培训选项。
每次训练最多进行一次
1000剧集,每集最多持续1集00时间步长。在事件管理器中显示培训进度(设置
阴谋选项)并禁用命令行显示(设置冗长的选项)。当代理连续100集获得的平均累积奖励超过-355时,停止训练。此时,代理可以控制水箱中的水位。
有关详细信息,请参阅RL培训选项.
最大事件数=1000;最大步骤数=ceil(Tf/Ts);训练选项数=RL训练选项(...“最大集”,每集,...“MaxStepsPerEpisode”,maxsteps,...“ScoreAveragingWindowLength”,100,...“冗长”错误的...“情节”,“培训进度”,...“停止培训标准”,“平均向上”,...“停止训练值”,-355);
使用火车函数。培训此代理是一个计算密集型过程,需要几分钟才能完成。要在运行此示例时节省时间,请通过设置溺爱到错误的.要亲自培训特工,请设置溺爱到符合事实的.
doTraining=false;如果溺爱%培训代理人。trainingStats=列车(代理人、环境、列车员);其他的%为示例加载预训练代理。装载(“WaterTankPIDtd3.mat”,“代理人”)终止

验证训练有素的代理
通过仿真验证学习到的agent与模型的一致性。
simOpts=rlSimulationOptions(“MaxSteps”,maxsteps);体验=sim(环境、代理、simOpts);
PI控制器的积分增益和比例增益是参与者表示的绝对权重。要获得权重,首先从参与者中提取可学习的参数。
actor=getActor(代理);parameters=getLearnableParameters(actor);
获得控制器增益。
Ki=abs(参数{1}(1))
碘化钾=仅有一个的0.3958
Kp=abs(参数{1}(2))
金伯利进程=仅有一个的8.0822
将从RL代理获得的增益应用于原始PI控制器块,并运行阶跃响应模拟。
mdlTest=“水箱LQG”;开放式系统(mdlTest);设置参数([mdlTest“/PID控制器”],“P”,num2str(Kp))设置参数([mdlTest“/PID控制器”],“我很高兴,num2str(Ki))sim(mdlTest)
提取阶跃响应信息、LQG成本和模拟的稳定裕度localStabilityAnalysis函数的定义。
rlStep=simout;成本=成本;rlStabilityMargin=局部稳定性分析(mdlTest);
应用通过以下方式获得的收益:控制系统调谐器到原始PI控制器块并运行阶跃响应模拟。
设置参数([mdlTest“/PID控制器”],“P”,num2str(Kp_CST))设置参数([mdlTest“/PID控制器”],“我很高兴,num2str(Ki_CST))sim(mdlTest)cstStep=simout;成本=成本;cstStabilityMargin=局部稳定性分析(mdlTest);
比较控制器性能
绘制每个系统的阶跃响应。
图1:图(CST步骤)保持在…上绘图(rlStep)网格在…上传奇(“控制系统调谐器”,“RL”,“位置”,‘东南’)头衔(“阶跃响应”)
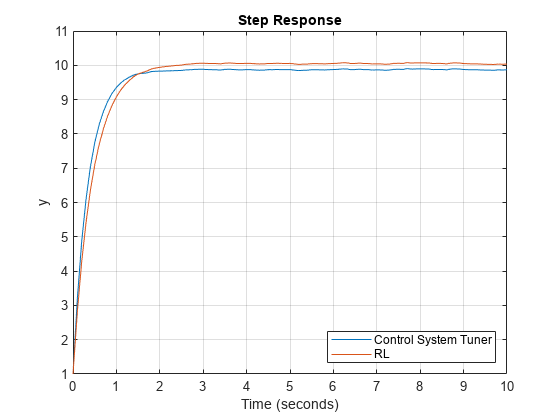
分析两种模拟的阶跃响应。
rlStepInfo = stepinfo (rlStep.Data rlStep.Time);cstStepInfo = stepinfo (cstStep.Data cstStep.Time);stepInfoTable = struct2table([cstStepInfo rlStepInfo]);stepInfoTable = removevars (stepInfoTable, {...“定居民”,“结算Max”,“下冲”,“PeakTime”});stepInfoTable.Properties.RowNames={“控制系统调谐器”,“RL”}步骤信息表
步进信息表=2×5表上升时间瞬变时间沉降时间超调峰值(uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu控制系统调谐器0.77737 1.3594 1.3278 0.33125 9.9023 RL0.24 1.708.077
分析两种模拟的稳定性。
stabilityMarginTable=struct2table([cstStabilityMargin rlStabilityMargin]);stabilityMarginTable=移除变量(stabilityMarginTable{...“GMF频率”,“PMF频率”,“延迟保证金”,“DMF频率”});stabilityMarginTable.Properties.RowNames={“控制系统调谐器”,“RL”};稳定表
稳定表=2×3表增益边缘相位边缘稳定控制系统调谐器8.1616 84.124真RL9.9226 84.242真
比较两个控制器的累积LQG成本。RL调谐控制器产生稍微更优的解决方案。
rlCumulativeCost=总和(rlCost.Data)
rlCumulativeCost=-375.9135
cstCumulativeCost=总和(cstCost.Data)
cstCumulativeCost=-376.9373
两个控制器都产生稳定的响应,控制器使用控制系统调谐器产生更快的响应。然而,RL调谐方法产生更高的增益裕度和更优的解决方案。
局部函数
功能创建水箱RL环境。
作用[env,obsInfo,actInfo]=localCreatePIDEnv(mdl)%定义观察规范obsInfo和行动规范actInfo。obsInfo=rlNumericSpec([2 1]);obsInfo.Name=“观察”;obsInfo.说明=“集成错误和错误”;actInfo=rlNumericSpec([1]);actInfo.Name=“PID输出”;%构建环境接口对象。env=rlSi万博1manbetxmulinkEnv(mdl,[mdl“/RL代理”],obsInfo,actInfo);%设置一个cutom重置函数,使模型的参考值随机化。env。ResetFcn = @(在)localResetFcn (, mdl);终止
在每集开始时,将参考信号和水箱的初始高度随机化的功能。
作用in=localResetFcn(in,mdl)%随机参考信号blk=sprintf([mdl“/所需的\n水位”]); hRef=10+4*(rand-0.5);in=设定锁定参数(in,blk,“价值”,num2str(hRef));%随机化初始高度hInit=0;blk=[mdl“/水箱系统/H”];in=参数(in,blk,“InitialCondition”,num2str(hInit));终止
函数,用于线性化和计算SISO水箱系统的稳定裕度。
作用保证金=本地稳定性分析(mdl)io(1)=linio([mdl“/Sum1”],1,“输入”);io(2)=linio([mdl“/水箱系统”],1,“openoutput”);op=操作点(mdl);op.时间=5;linsys=线性化(mdl,io,op);余量=所有余量(linsys);终止
功能创建评论网络。
作用criticNetwork=localCreateCriticNetwork(numObservations,numActions)状态路径=[featureInputLayer(numObservations,“正常化”,“没有”,“姓名”,“国家”)完全连接层(32,“姓名”,“fc1”)];actionPath=[featureInputLayer(numActions,“正常化”,“没有”,“姓名”,“行动”)完全连接层(32,“姓名”,“fc2”)]; commonPath=[连接层(1,2,“姓名”,“海螺”)雷卢耶(“姓名”,“重新注册1”)完全连接层(32,“姓名”,“fcBody”)雷卢耶(“姓名”,“重新注册2”)完全连接层(1,“姓名”,“qvalue”)]; 临界网络=layerGraph();临界网络=添加层(临界网络,状态路径);criticNetwork=addLayers(criticNetwork,actionPath);临界网络=添加层(临界网络,公共路径);临界网络=连接层(临界网络,“fc1”,“concat/in1”); 临界网络=连接层(临界网络,“fc2”,“concat/in2”);终止
另见
相关话题
您还可以从以下列表中选择网站: