确定评估的关键参数(GUI)
这个例子展示了如何使用灵敏度分析来缩小拟合模型时需要估计的参数数量。这个例子使用前庭-眼反射模型,产生代偿性眼球运动。
模型描述
前庭眼反射(VOR)使眼睛以与头部相同的速度和相反的方向移动,因此在正常活动中头部移动时,视觉不会模糊。例如,如果头向右转,眼睛就会以同样的速度向左转。即使在黑暗中也会发生这种情况。事实上,VOR最容易在黑暗中测量,以确保眼球运动主要由VOR驱动。
头部转动是由内耳的半规管器官感知的。它们检测头部运动并将头部运动的信号传递给大脑,大脑将运动指令发送给眼部肌肉,因此眼部运动补偿了头部运动。我们希望使用眼动数据来估计这些不同阶段的模型参数。我们将使用的模型如下所示。模型中有四个参数:延迟,获得,Tc,Tp.
open_system (“sdoVOR”)

该文件sdoVOR_Data.mat包含统一采样的刺激和眼球运动数据。如果VOR是完全补偿的,那么当垂直翻转时,眼动数据图将恰好覆盖在头部运动数据图上。这样的系统可以用增益1和相位180度来描述。然而,真正的眼球运动是接近的,但不是完全的代偿。
负载sdoVOR_Data.mat;%列向量:Time HeadData EyeData
我们将使用灵敏度分析UI来查看模型输出与数据的拟合程度,并探索哪些模型参数对拟合优度影响最大。要打开灵敏度分析UI,请在应用程序选项卡上,单击灵敏度分析仪下控制系统启动灵敏度分析仪.
要将数据与模型关联,请单击新的需求,选择信号匹配要求。这指定了一个目标函数,由数据和模型输出之间的误差平方和组成。在信号匹配对话框中,指定输出为(时间EyeData),并指定输入为(时间HeadData).

若要查看眼动数据,请在用户界面左侧的数据浏览器中,右键单击SignalMatching要求,并选择Plot & simulation。下面的图显示了由一系列脉冲组成的刺激。上面的图显示了眼球运动数据,它与刺激相似,但并不完全匹配。这也表明模型模拟输出与眼动数据不匹配,因为模型参数需要估计。

探索设计空间
该模型试图捕捉导致头部运动和眼球运动之间差异的现象。在这里,我们将探索由模型参数形成的设计空间。单击,指定灵敏度分析界面中要浏览的参数选择参数并创建一个新的参数集。选择所有模型参数:延迟,获得,Tc而且Tp.
通过生成参数值来探索设计空间。点击生成值并选择随机值。为了示例的可重复性,请重置随机数生成器。
rng (“默认”)
由于有4个参数,我们将生成40个样本。
的延迟参数模拟了从内耳向大脑和眼睛传递信号有一些延迟的事实。这种延迟是由于化学神经递质穿过神经细胞之间的突触间隙所需的时间。根据前庭-眼反射突触的数量,这种延迟预计在5毫秒左右。我们将用均匀分布建模,其下界为2 ms,上界为9 ms。
的获得参数模拟了这样一个事实,即在黑暗中,眼睛不像头部那样移动。我们将用一个下界为0.6,上界为1的均匀分布来建模。
的Tc参数模型与半规管相关的动力学,以及一些额外的神经处理。这些神经管是高通滤波器,因为当一个实验对象被置于旋转运动状态后,神经管中的神经活性膜会慢慢放松到静止位置,因此神经管停止感知运动。因此,在刺激经历过渡边缘后,随着时间的推移,眼球运动倾向于脱离刺激。基于导管的力学特性,结合额外的神经处理(延长时间常数以提高VOR的精度),我们将建模Tc具有正态分布(即钟形曲线),均值为15秒,标准差为3秒。
最后,Tp参数模型的动眼器植物的动态,即眼睛和肌肉和组织附着在它。植物可以用两个极点来建模,但人们认为,具有较大时间常数的极点被大脑中的预先补偿取消了,以使眼睛能够快速运动。因此,在图中,当刺激经历过渡边缘时,眼球运动只会有一点延迟。我们将建模Tp均匀分布,下界为0.005秒,上界为0.05秒。

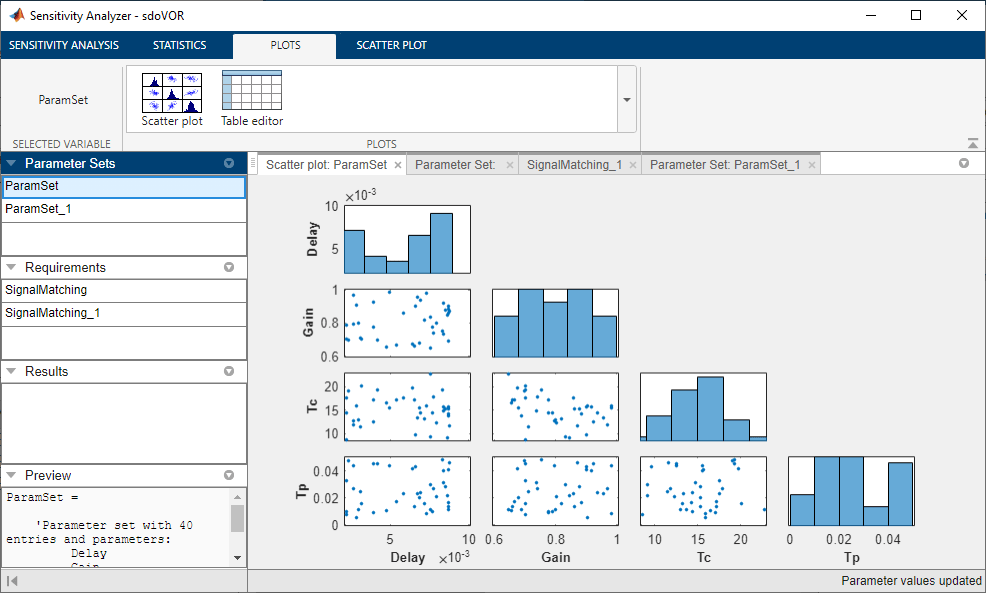
当生成样例值时,它们会出现在Sensitivity Analysis UI中的一个表中。要绘制它们,请选择ParamSet在数据浏览器中,单击情节标记,并制作散点图。上面的抽样使用了默认选项,这些选项反映在散点图中。对于采用均匀分布建模的参数,直方图呈现近似均匀。然而,参数Tc采用正态分布建模,直方图呈钟形曲线。如果统计和机器学习工具箱™可用,则可以使用许多其他分布,并且可以使用Sobol或Halton低差异序列进行抽样。非对角线图显示了不同变量对之间的散点图。由于我们没有指定参数之间的相互相关性,所以散点图看起来不相关。但是,如果认为参数是相关的,则可以使用对话框中的Correlation Matrix选项卡来生成随机参数值。
评估模型
现在我们已经为参数集生成了值,并指定了一个需求(SignalMatching),我们可以对模型进行评估。在敏感性分析选项卡上,单击评估模型.
模型为每组参数值运行一次,结果散点图随着新的计算结果的出现而更新。使用并行计算也可以加快计算速度。评估完成后,所有结果也显示在一个表中。

从评价结果的散点图中可以看出SignalMatching的函数,需求似乎系统地变化获得而且Tc,但不是延迟或Tp.在等高线图中可以看到类似的东西。选择EvalResults变量在数据浏览器中,单击情节制作等高线图。的函数,需求不会从左到右系统地变化延迟,但它在垂直方向上是获得.

统计分析
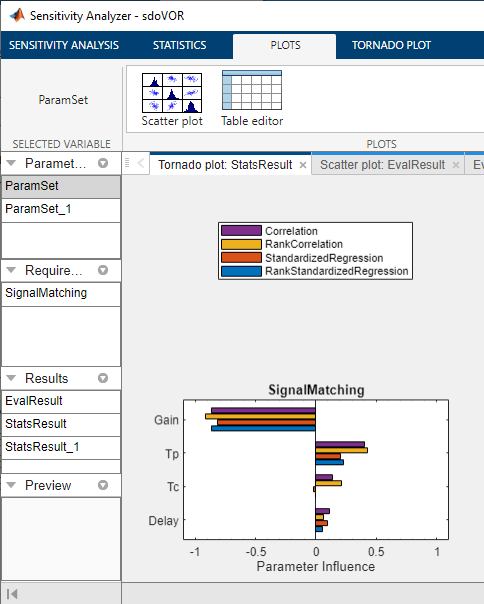
我们可以使用统计分析来量化每个参数对需求的影响程度。单击统计数据TAB,同时选择相关和标准化回归;线性和排序分析类型。如果有“统计和机器学习工具箱”,也可以选择偏相关和Kendall相关。点击计算统计数据进行计算并显示龙卷风图。龙卷风图按照对需求影响最大的参数的顺序从上到下显示结果。统计值的范围从-1到1,其中大小表示参数对需求的影响程度,符号表示参数值的增加是否对应于需求值的增加或减少。以大多数标准衡量,这是SignalMatching需求更敏感获得而且Tc,不太敏感延迟而且Tp.
选择估算参数
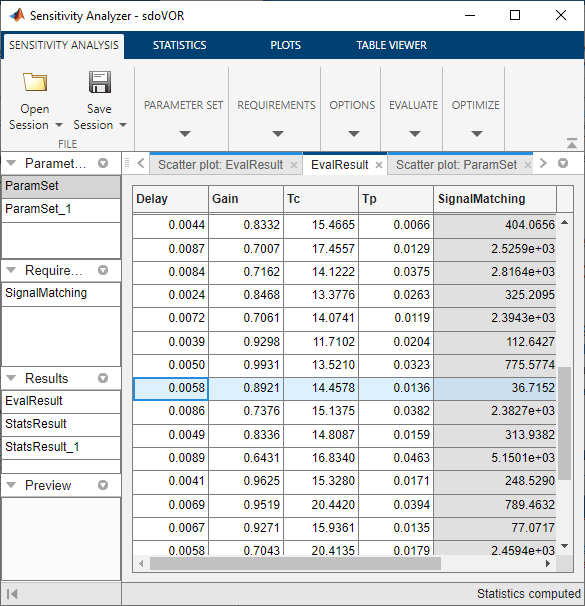
对于参数估计,我们需要为参数指定起始值。单击评估结果表,然后单击SignalMatching列标题对结果进行排序。属性的最小值选择参数值行SignalMatching要求。右键单击该行并提取这些参数值。一个新变量,ParamValues,显示在数据浏览器中。
若要从灵敏度分析转换到参数估计,请导航到敏感性分析选项卡上,单击优化,打开参数估计会话。在出现的对话框中,指定要在中使用参数值ParamValues,以及SignalMatching要求。
因为我们在参数上面找到了获得而且Tc对价值影响最大的是什么SignalMatching,我们希望只估计这两个参数,因为估计的时间随着估计参数的数量而增加。在“参数估计界面”中,单击选择参数只选择获得而且Tc估计。

由于实验定义已导入SignalMatching并且参数值已从ParamValues,我们已经有了估算所需的一切。点击估计进行参数估计获得而且Tc.因为我们只估计了两个最具影响力的参数,所以估计收敛很快,模型输出与数据非常匹配。就像灵敏度分析中的模型评估一样,并行计算可以用来加速估计。

综上所述,使用Sensitivity Analysis UI来探索参数设计空间,确定两个参数,获得而且Tc,比其他国家的影响力要大得多。估算的起始点也确定了。在参数估计界面中引入了该起始点和对实验数据的良好拟合要求。由于只需要估计两个参数,估计很快完成,模型输出与数据拟合,残差很小。
关闭模型。
bdclose (“sdoVOR”)
相关的话题
您也可以从以下列表中选择一个网站: