Analyze Text Data Using Topic Models
This example shows how to use the Latent Dirichlet Allocation (LDA) topic model to analyze text data.
A Latent Dirichlet Allocation (LDA) model is a topic model which discovers underlying topics in a collection of documents and infers the word probabilities in topics.
Load and Extract Text Data
Load the example data. The filefactoryReports.csvcontains factory reports, including a text description and categorical labels for each event.
data = readtable("factoryReports.csv",TextType="string"); head(data)
ans=8×5 tableDescription Category Urgency Resolution Cost _____________________________________________________________________ ____________________ ________ ____________________ _____ "Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" 45 "Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" 35 "There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" 16200 "Fried capacitors in the assembler." "Electronic Failure" "High" "Replace Components" 352 "Mixer tripped the fuses." "Electronic Failure" "Low" "Add to Watch List" 55 "Burst pipe in the constructing agent is spraying coolant." "Leak" "High" "Replace Components" 371 "A fuse is blown in the mixer." "Electronic Failure" "Low" "Replace Components" 441 "Things continue to tumble off of the belt." "Mechanical Failure" "Low" "Readjust Machine" 38
Extract the text data from the fieldDescription.
textData = data.Description; textData(1:10)
ans =10×1 string"Items are occasionally getting stuck in the scanner spools." "Loud rattling and banging sounds are coming from assembler pistons." "There are cuts to the power when starting the plant." "Fried capacitors in the assembler." "Mixer tripped the fuses." "Burst pipe in the constructing agent is spraying coolant." "A fuse is blown in the mixer." "Things continue to tumble off of the belt." "Falling items from the conveyor belt." "The scanner reel is split, it will soon begin to curve."
Prepare Text Data for Analysis
Create a function which tokenizes and preprocesses the text data so it can be used for analysis. The functionpreprocessText, listed in thePreprocessing Functionsection of the example, performs the following steps in order:
Tokenize the text using
tokenizedDocument.Lemmatize the words using
normalizeWords.Erase punctuation using
erasePunctuation.Remove a list of stop words (such as "and", "of", and "the") using
removeStopWords.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.
Prepare the text data for analysis using thepreprocessTextfunction.
documents = preprocessText(textData); documents(1:5)
ans = 5×1 tokenizedDocument: 6 tokens: item occasionally get stuck scanner spool 7 tokens: loud rattling bang sound come assembler piston 4 tokens: cut power start plant 3 tokens: fry capacitor assembler 3 tokens: mixer trip fuse
创建一个bag-of-words模型标记化的文档uments.
bag = bagOfWords(documents)
bag = bagOfWords with properties: Counts: [480×338 double] Vocabulary: [1×338 string] NumWords: 338 NumDocuments: 480
Remove words from the bag-of-words model that have do not appear more than two times in total. Remove any documents containing no words from the bag-of-words model.
bag = removeInfrequentWords(bag,2); bag = removeEmptyDocuments(bag)
bag = bagOfWords with properties: Counts: [480×158 double] Vocabulary: [1×158 string] NumWords: 158 NumDocuments: 480
Fit LDA Model
Fit an LDA model with 7 topics. For an example showing how to choose the number of topics, seeChoose Number of Topics for LDA Model. To suppress verbose output, set theVerbose选项为0。再现性,使用rngfunction with the"default"option.
rng("default") numTopics = 7; mdl = fitlda(bag,numTopics,Verbose=0);
If you have a large dataset, then the stochastic approximate variational Bayes solver is usually better suited as it can fit a good model in fewer passes of the data. The default solver forfitlda(collapsed Gibbs sampling) can be more accurate at the cost of taking longer to run. To use stochastic approximate variational Bayes, set theSolveroption to"savb". For an example showing how to compare LDA solvers, seeCompare LDA Solvers.
Visualize Topics Using Word Clouds
You can use word clouds to view the words with the highest probabilities in each topic. Visualize the topics using word clouds.
figure t = tiledlayout(“流”); title(t,"LDA Topics")fori = 1:numTopics nexttile wordcloud(mdl,i); title("Topic "+ i)end

View Mixtures of Topics in Documents
Create an array of tokenized documents for a set of previously unseen documents using the same preprocessing function as the training data.
str = ["Coolant is pooling underneath assembler.""Sorter blows fuses at start up.""There are some very loud rattling sounds coming from the assembler."]; newDocuments = preprocessText(str);
Use thetransformfunction to transform the documents into vectors of topic probabilities. Note that for very short documents, the topic mixtures may not be a strong representation of the document content.
topicMixtures = transform(mdl,newDocuments);
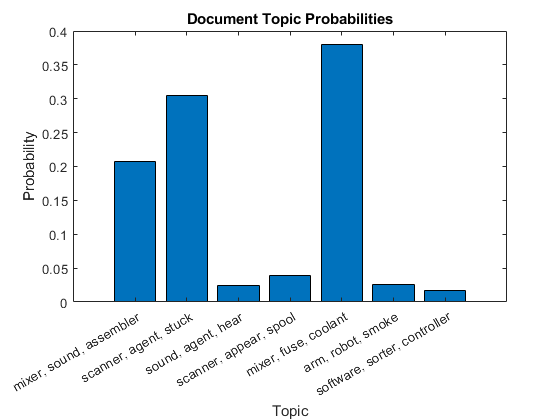
Plot the document topic probabilities of the first document in a bar chart. To label the topics, use the top three words of the corresponding topic.
fori = 1:numTopics top = topkwords(mdl,3,i); topWords(i) = join(top.Word,", ");endfigure bar(topicMixtures(1,:)) xlabel("Topic") xticklabels(topWords); ylabel("Probability") title("Document Topic Probabilities")
Visualize multiple topic mixtures using stacked bar charts. Visualize the topic mixtures of the documents.
figure barh(topicMixtures,"stacked") xlim([0 1]) title("Topic Mixtures") xlabel("Topic Probability") ylabel("Document") legend(topWords,...Location="southoutside",...NumColumns=2)

Preprocessing Function
The functionpreprocessText, performs the following steps in order:
Tokenize the text using
tokenizedDocument.Lemmatize the words using
normalizeWords.Erase punctuation using
erasePunctuation.Remove a list of stop words (such as "and", "of", and "the") using
removeStopWords.Remove words with 2 or fewer characters using
removeShortWords.Remove words with 15 or more characters using
removeLongWords.
functiondocuments = preprocessText(textData)% Tokenize the text.documents = tokenizedDocument(textData);% Lemmatize the words.documents = addPartOfSpeechDetails(documents); documents = normalizeWords(documents,Style="lemma");% Erase punctuation.documents = erasePunctuation(documents);% Remove a list of stop words.documents = removeStopWords(documents);% Remove words with 2 or fewer characters, and words with 15 or greater% characters.documents = removeShortWords(documents,2); documents = removeLongWords(documents,15);end
See Also
tokenizedDocument|bagOfWords|removeStopWords|fitlda|ldaModel|wordcloud|addPartOfSpeechDetails|removeEmptyDocuments|removeInfrequentWords|transform
Related Topics
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)