集群评价
聚类用于未标记的数据,以找到自然分组和模式。大多数聚类算法需要研究人员预先了解聚类的数量。当此信息不可用时,可以使用聚类评估技术根据指定的度量来确定数据中存在的聚类数量。这个例子识别了Fisher的虹膜数据中的集群。
Fisher的虹膜数据包括对150个虹膜标本的萼片长度、萼片宽度、花瓣长度和花瓣宽度的测量。
清晰的负载fisheririsX = meas;Y =分类(物种);
eva = evalclusters(X,“kmeans”,“CalinskiHarabasz”,“中”[1:10]);情节(eva) disp(类别(y)”)
警告:在复制1期间,在迭代1中创建了空集群。" setosa " " versicolor " " virginica "
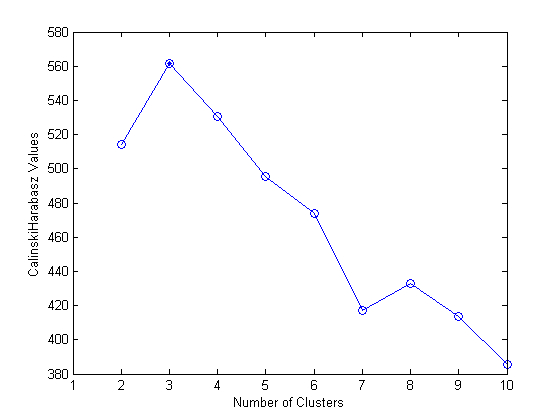
我们可以确认评估结果,因为我们事先知道有三个物种,因此有三个聚类:Setosa, versicolor和virginica
您可以使用主成分分析来降低数据的维数以实现可视化。在这个例子中,我们将探索非负矩阵分解,它(除了提供特征数量的减少)也保证了特征是非负的,如果你的预测器本身是非负的。
由于我们的特征都不是负面的,让我们用nnmf来确认3可视%群集Xred = nnmf(X,2);gscatter (xr (: 1) xr (:, 2), y)包含(第一列的) ylabel (第2列的)图例(类别(y))网格在

Fisher的虹膜数据包括对150个虹膜标本的萼片长度、萼片宽度、花瓣长度和花瓣宽度的测量。这里有三个物种各50个标本。这个数据集是随附的统计和机器学习工具箱™.
您也可以从以下列表中选择一个网站: