套索正规化
本例通过查看数据集并识别人群中糖尿病的预测因子,演示了套索用于特征选择的使用。数据集包含10个预测因子。目标是确定重要的预测因素,并丢弃那些不必要的预测因素。
查看完整的数据和功能集对于这个演示。
文件名=“diabetes.txt”;urlwrite (“http://www.stanford.edu/ hastie /论文/拉/ diabetes.data”文件名);
保存文件后,可以将数据作为表导入MATLAB导入工具使用默认选项。或者,您可以使用下面的代码,可以从导入工具自动生成:
formatSpec =' % f % % f % % % f % f % % % f % f % ^ \ n \ [r];fileID = fopen(文件名,“r”);dataArray = textscan(fileID, formatSpec,“分隔符”,' \ t ',“HeaderLines”, 1“ReturnOnError”、假);文件关闭(文件标识);糖尿病= table(dataArray{1:end-1},“VariableNames”, {“年龄”,“性”,“身体质量指数”,“英国石油公司”,“S1 ',“S2”,“S3”,S4的,“S5”,“S6”,“Y”});clearvars文件名分隔符startRowformatSpec文件标识dataArray答;删除文件删除diabetes.txt
predNames = diabetes.Properties.VariableNames(1:end-1);X =糖尿病{:,1:end-1};Y =糖尿病{:,end};
[beta, FitInfo] =套索(X,y,“标准化”,真的,“简历”10“PredictorNames”, predNames);FitInfo lassoPlot(β,“PlotType”,“λ”,“XScale”,“日志”);Hlplot = get(gca,“孩子”);为图中的每条线生成颜色颜色= hsv(数字(hlplot));为Ii = 1:数字(hlplot) set(hlplot(Ii),“颜色”、颜色(ii,:));结束集(hlplot,“线宽”2)组(gcf“单位”,“归一化”,“位置”,[0.2 0.4 0.5 0.35])图例(“位置”,“最佳”)
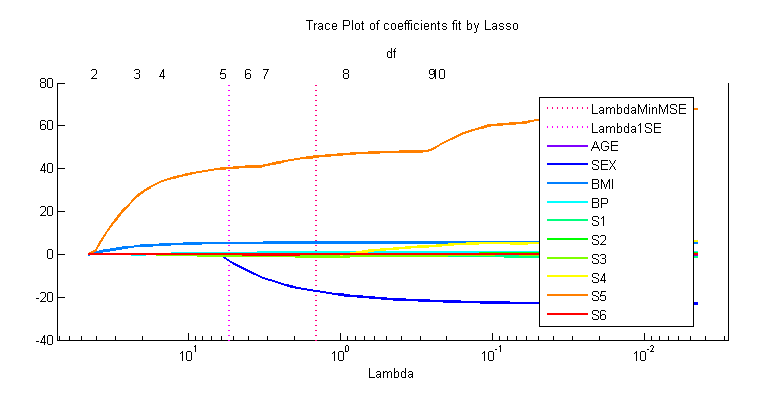
较大的lambda值出现在图的左侧,这意味着正则化增加。随着lambda值的增加,非零预测器的数量也会增加。
作为经验法则,一个标准误差值通常用于选择一个较小的模型,具有良好的拟合性。
lam = FitInfo.Index1SE;isImportant = beta(:,lam) ~= 0;disp (predNames(重要信息)
' bmi ' ' bp ' ' s3 ' ' s5 '
mdlFull = fitlm(X,y,“拦截”、假);disp (mdlFull)
线性回归模型:y ~ x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + x9 + x10估计SE tStat pValue x1 0.022296 0.22256 0.10018 0.92025 x2 -26.073 5.9561 -4.3775 1.5074e-05 x3 5.3537 0.73462 7.2877 1.5112e-12 x4 1.0178 0.2304 4.4175 1.2635e-05 x5 1.2636 0.33044 3.8239 0.00015068 x6 -1.2849 0.3468 -3.7051 0.00023877 x7 -3.0683 0.37189 -8.2505 1.9259e-15 x8 -5.508 5.5883 -0.98565 0.32486 x9 5.5034 9.4293 0.58365 0.55976 x10 0.12339 0.2788 0.44256 0.6583观测数:442,误差自由度:432均方根误差:55.6
比较正则模型和非正则模型的MSE。
disp ([“套索MSE:”, num2str(FitInfo.MSE(lam))]) disp([“全MSE:”num2str (mdlFull.MSE)])
套索均方误差:3176.5163全均方误差:3092.896
仅使用套索确定的重要预测因子的拟合的均方误差(MSE)非常接近使用所有预测因子的线性模型的误差。套索常用于防止过拟合或去除冗余预测因子以提高模型精度。
您也可以从以下列表中选择一个网站: