Audio Labeler
Define and visualize ground-truth labels
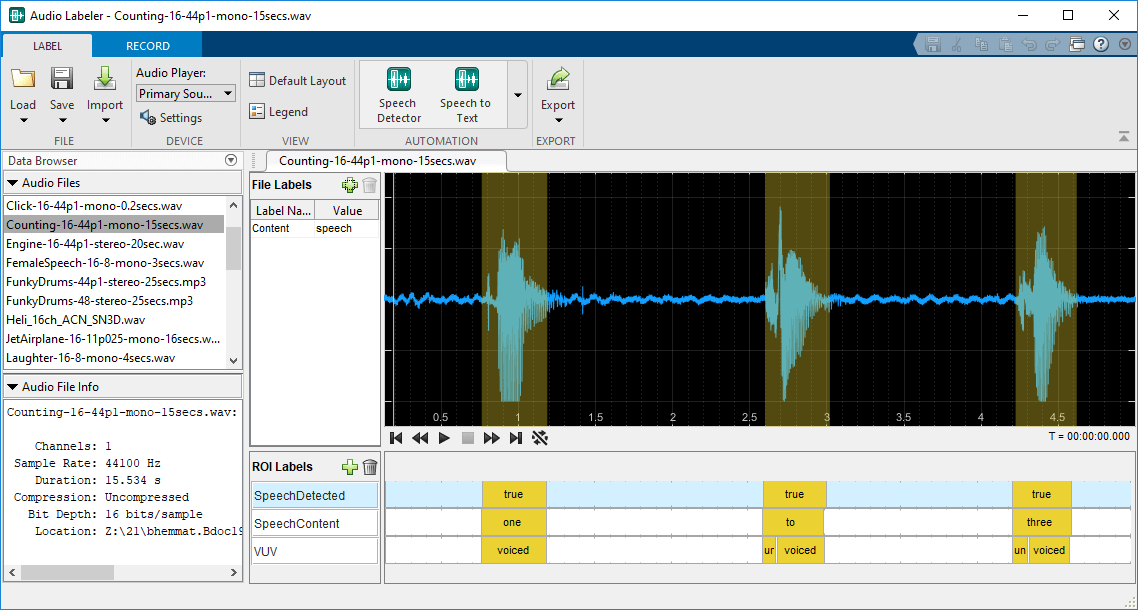
Open the Audio Labeler App
MATLAB®toolstrip: On theAppstab, underSignal Processing and Communications, click the app icon.
MATLAB command prompt: Enter
audioLabeler.
Examples
Create Keyword Spotting Mask Using Audio Labeler
In this example, you create a logical mask for an audio signal where ones correspond to the utterance "yes" and zeros correspond to the absence of the utterance "yes". To create the mask, you use the IBM™ speech-to-text API through theAudio Labeler应用程序。
This example requires that you install theSpeech-to-Text Transcriptionfunctionality.
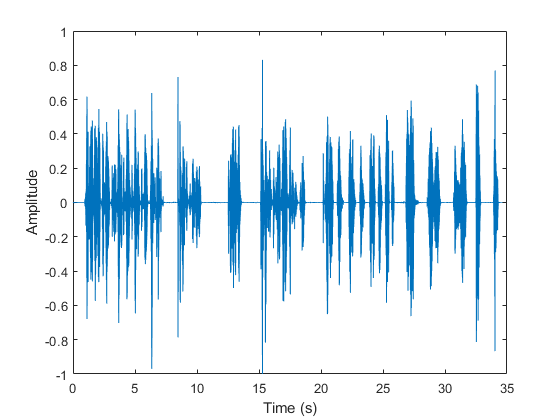
Listen to the audio file that you want to label and then visualize it in the time domain.
[audioIn,fs] = audioread("KeywordSpeech-16-16-mono-34secs.flac"); sound(audioIn,fs) t = (0:numel(audioIn)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude')
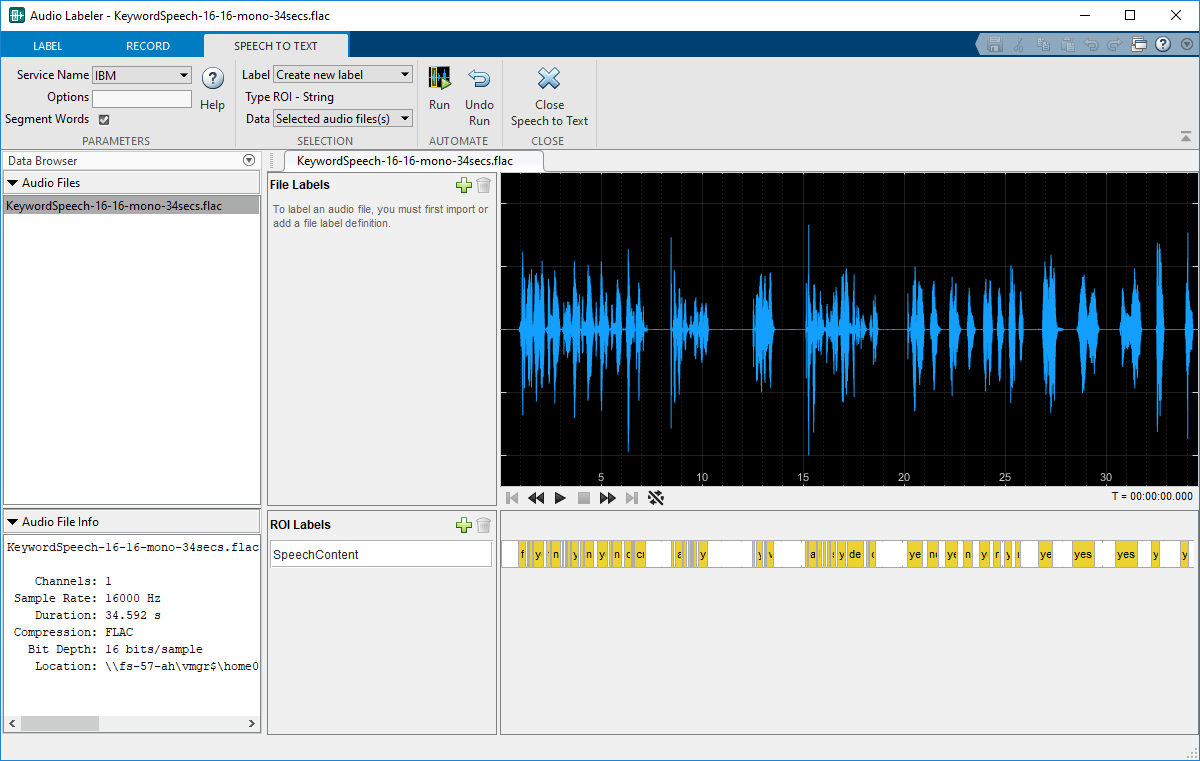
Open theAudio Labelerapp and load theKeywordSpeech-16-16-mono-34secs.flacfile into theData Browser.

UnderAutomation, clickSpeech to Text. On theSpeech to Texttab, select your preferred speech-to-text API. This example uses the IBM speech-to-text API. SelectSegment Wordsso that the text labels are divided into individual words instead of sentences. ClickRunto interface with the speech-to-text API and create a new region of interest (ROI) label. The ROI label contains words detected and labeled by IBM's speech-to-text API.
Close theSpeech to Texttab and then export the labeled signal set to the workspace.

The labels are exported to the workspace aslabeledSignalSetobject with a time stamp. Set the variablelabeledSetto the time-stampedlabeledSignalSetobject.
labeledSet = myLabeledSet;
Inspect theSpeechContentlabel.
speechContent = labeledSet.Labels.SpeechContent{1}
speechContent=52×2 tableROILimits Value ____________ _________ 0.87 1.31 "first" 1.31 1.41 "you" 1.41 1.63 "said" 1.63 2.22 "yes" 2.25 2.52 "then" 2.52 3.03 "no" 3.09 3.22 "and" 3.22 3.32 "you" 3.32 3.52 "said" 3.52 3.94 "yes" 3.94 4.16 "then" 4.16 4.66 "no" 4.83 5.39 "yes" 5.42 5.57 "the" 5.57 6.07 "no" 6.15 6.56 "driving" ⋮
The speech-to-text API returns the limits of the ROI labels in seconds. Use theSpeechContenttable to create a logical vector.
keywordLabels = speechContent(speechContent.Value =="yes",:); keywordROILimitsInSamples = round(keywordLabels.ROILimits*fs); mask = zeros(size(audioIn),"logical");fori = 1:size(keywordROILimitsInSamples) mask(keywordROILimitsInSamples(i,1):keywordROILimitsInSamples(i,2)) = true;end
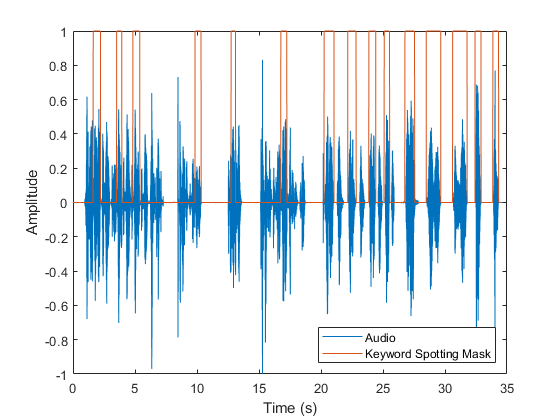
Plot the speech signal and the keyword spotting mask.
plot(t,audioIn,...t,mask) xlabel('Time (s)') ylabel('Amplitude') legend('Audio','Keyword Spotting Mask','Location','southeast')
Related Examples
Programmatic Use
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select:.
Selectweb site你也可以从下面选择一个网站list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
Europe
- Belgium(English)
- Denmark(English)
- Deutschland(Deutsch)
- España(Español)
- Finland(English)
- France(Français)
- Ireland(English)
- Italia(Italiano)
- Luxembourg(English)
- Netherlands(English)
- Norway(English)
- Österreich(Deutsch)
- Portugal(English)
- Sweden(English)
- Switzerland
- United Kingdom(English)