이번역최신을있지않습니다않습니다。최신내용으로보려면를하십시오하십시오하십시오。
딥러닝을사용시퀀스분류
이(LSTM)신경망신경망신경망사용시퀀스를하는방법보여줍니다줍니다줍니다줍니다줍니다줍니다。
시퀀스데이터하도록심층을을훈련위해위해위해신경망신경망할있습니다있습니다있습니다。lstm신경망사용신경망에데이터하고시퀀스데이터개별시간스텝을을기준으로예측예측을할할수수있습니다있습니다。
이[1]과[2]에서에서한한日本元音데이터데이터사용합니다합니다。2개해서된된된된개일본어을나타내는시계열시계열데이터를주고주고화자화자를를인식인식하도록하도록하도록하도록하도록하도록하도록하도록하도록하도록하도록신경망신경망신경망신경망신경망을을을을9명명명시계열데이터를합니다합니다합니다합니다。12 12개특징을길이가다릅니다다릅니다다릅니다다릅니다다릅니다다릅니다。270개의관측값과과과과과개테스트값을합니다합니다합니다。
시퀀스데이터불러오기
日本元音훈련데이터옵니다옵니다。Xtrain12 12개된서로다른길이길이의시퀀스시퀀스시퀀스시퀀스개개포함셀형배열입니다입니다y9명의화자에대응하는레이블“ 1”,“ 2”,...,“ 9”로구성된된된된입니다입니다입니다입니다입니다Xtrain의요소특징에하나하나행행을행행개행과각시간스텝에대해대해하나의의열열을을갖는가변가변가변개수개수개수개수의의열로열로이루어진입니다
[Xtrain,Ytrain] = japanyvowelstraindata;Xtrain(1:5)
ans =5×1单元格数组{12x20 double} {12x26 double} {12x22 double} {12x20 double} {12x21 double}
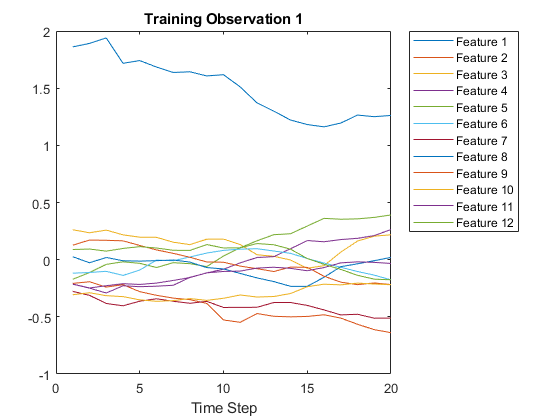
첫번째을으로화합니다합니다。선은각각의에됩니다됩니다。
图图(Xtrain {1}')Xlabel(“时间步长”) 标题(“训练观察1”)numFeatures = size(xtrain {1},1);传奇(“特征 ”+字符串(1:数字),'地点',,,,“东北”)
채우기를위해준비하기
기본적중훈련가미니분할모든시퀀스의길이가같아지도록시퀀스채워집니다채워집니다채워집니다。너무많이성능이될있습니다있습니다있습니다。
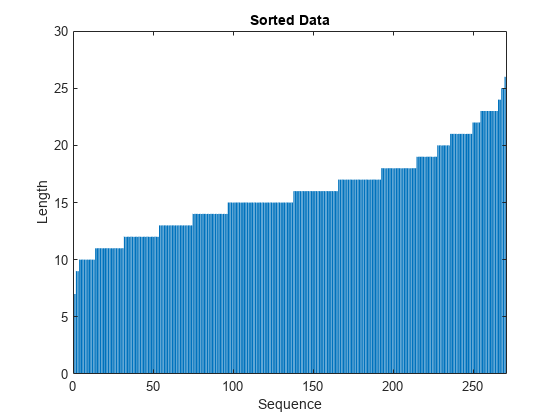
훈련과정많이않도록하려면길이길이시퀀스를를정렬한다음미니미니배치크기크기를선택하여하나의의미니미니미니배치배치에에속한속한시퀀스들이시퀀스들이비슷한비슷한길이길이길이를를합니다。다음그림데이터정렬하기전과시퀀스의효과보여줍니다줍니다줍니다。

각관측에시퀀스를가져옵니다가져옵니다。
numObservations = numel(xtrain);为了i = 1:numObservations序列= xtrain {i};序列长度(i)= size(序列,2);结尾
시퀀스길이기준데이터정렬합니다합니다。
[sequenceLengths,idx] = sort(sequenceLengths);Xtrain = Xtrain(idx);ytrain = ytrain(idx);
정렬된를막대로합니다합니다합니다。
图栏(序列长)ylim([0 30])xlabel(“序列”)ylabel(“长度”) 标题(“排序数据”)
27로로선택하여훈련를하게나누고배치에채워지는양양줄입니다입니다。다음그림시퀀스더채우기채우기줍니다줍니다줍니다。
minibatchsize = 27;

lstm신경망아키텍처하기하기
lstm신경망아키텍처합니다합니다。12(12(입력)로지정지정지정합니다합니다지정지정합니다합니다합니다합니다。100개개양방향방향계층계층지정시퀀스마지막를출력출력합니다。마지막마지막,9인완전연결을하여하여하여개의를지정하고하고,이어서이어서하고하고하고소프트맥스계층계층분류계층계층을지정지정합니다。
예측시점시퀀스액세스할수있다면신경망양방향방향방향방향계층계층계층사용할수있습니다있습니다있습니다。lastm계층계층시간스텝전체로부터합니다합니다합니다합니다합니다。예측시점시퀀스액세스할수수수수없다면없다면값전망전망하거나한번번에하나하나하나의시간시간스텝스텝을을하려하려하려하려한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면한다면
InputSize = 12;numhidendunits = 100;numClasses = 9;层= [...sequenceInputlayer(Inputsize)Bilstmlayer(numhiddenunits,,,'outputmode',,,,'最后的')完整连接的layerer(numClasses)SoftMaxlayer分类器]
层= 5x1层阵列,带有层:1''序列输入序列输入,带12个维度2''bilstm bilstm,带有100个隐藏单元3''完全连接的9个完全连接的层4'softmax softmax 5'分类'
이번에는옵션을합니다합니다。솔버를'亚当'으로지정,기울기임계값을을로로하고하고하고,최대최대횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수횟수하고하고하고하고하고하고하고미니배치채우기을줄이려면미니배치배치크기를를를하십시오하십시오하십시오하십시오하십시오하십시오。데이터가긴의와같도록데이터채우려면시퀀스길이를'最长'로지정하십시오。데이터가를으로정렬된를유지하려면가섞이지않도록지정하십시오하십시오。
cpu를에는에는에는에는를를를를사용사용하는하는것이더적합적합합니다합니다합니다합니다。“执行环境”를'中央处理器'로지정합니다。gpu를사용수있는경우경우경우를를를“执行环境”를'汽车'(디폴트)로설정。
maxepochs = 100;minibatchsize = 27;选项=训练('亚当',,,,...“执行环境”,,,,'中央处理器',,,,...“梯度阈值”,1,...“ maxepochs”,maxepochs,...“ MINIBATCHSIZE”,minibatchsize,...“序列长度”,,,,'最长',,,,...“洗牌”,,,,'绝不',,,,...“冗长”,0,...“绘图”,,,,“训练过程”);
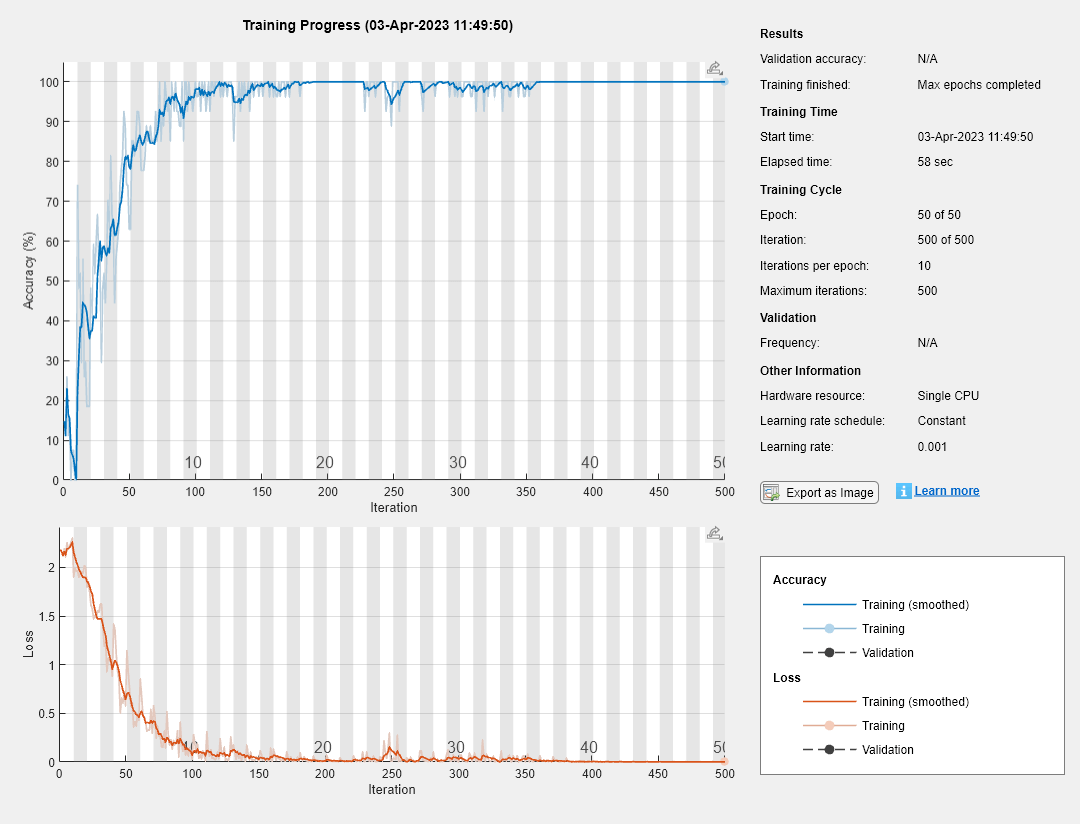
LSTM신경망훈련
火车网lastm신경망훈련시킵니다훈련시킵니다훈련시킵니다훈련시킵니다훈련시킵니다훈련시킵니다훈련시킵니다훈련시킵니다훈련시킵니다훈련시킵니다。
net = trainnetwork(Xtrain,Ytrain,Layers,options);
LSTM신경망테스트
테스트세트불러오고를분류합니다합니다。
日本元音테스트데이터옵니다옵니다。XTEST12개개서로다른길이길이의시퀀스시퀀스시퀀스시퀀스시퀀스개개를하는입니다입니다입니다ytest9명명화자대응레이블레이블레이블“ 1”,“ 2”,...“ 9”로된된된된입니다입니다。
[xtest,ytest] = japanyvowelstestdata;XTEST(1:3)
ans =3×1单元格数组{12x19 double} {12x17 double} {12x19 double}
LSTM신경망网은비슷한갖는를포함미니배치사용하여되었습니다되었습니다되었습니다。테스트데이터도방식구성합니다합니다。시퀀스길이으로테스트를합니다합니다합니다。
numobservationstest = numel(xtest);为了i = 1:numobservationstest序列= xtest {i};sequenceLengthstest(i)= size(序列,2);结尾[sequenceLengthstest,idx] = sort(suequenceLengthstest);Xtest = XTest(idx);ytest = ytest(idx);
테스트데이터분류합니다。분류과정채워지는을줄이려면미니배치배치크기를를를하십시오하십시오하십시오하십시오하십시오하십시오。훈련데이터한양채우기를적용시퀀스를를를'最长'로지정하십시오。
minibatchsize = 27;ypred =分类(net,xtest,...“ MINIBATCHSIZE”,minibatchsize,...“序列长度”,,,,'最长');
예측의정확도계산합니다。
acc = sum(ypred == ytest)./ numel(ytest)
ACC = 0.9730
참고문헌
[1] M. Kudo,J。Toyama和M. Shimbo。“使用传递区域的多维曲线分类。”图案识别字母。卷。20,编号11-13,第1103–1111页。
[2] UCI机器学习存储库:日本元音数据集。https://archive.ics.uci.edu/ml/datasets/japanese+vowels
참고항목
火车网|训练|lstmlayer|Bilstmlayer|sequenceInputlayer
관련항목
您还可以从以下列表中选择一个网站:
美洲
- AméricaLatina(Español)
- 加拿大(英语)
- 美国(英语)