이번역페이지는최신내용을담고있지않습니다。최신내용을문으로보려면여기를클릭하십시오。
사전훈련된심층신경망
자연영상에서강력하고유익한특징을추출하도록학습된사전훈련된영상분류신경망을새로운작업을학습하기위한출발점으로사용할수있습니다。대부분의사전훈련된신경망은ILSVRC(ImageNet大规模视觉识别挑战赛)[2]에서사용되는ImageNet데이터베이스[1]의데이터로훈련되어있습니다。이러한신경망은1백만개가넘는영상에대해훈련되었으며영상을키보드,커피머그잔,연필,각종동물등1000가지사물범주로분류할수있습니다。사전훈련된신경망을전이학습을통해사용하는것이일반적으로신경망을처음부터훈련시키는것보다훨씬더빠르고쉽습니다。
사전에훈련된신경망은다음과같은작업에서사용할수있습니다。
| 목적 | 설명 |
|---|---|
| 분류 | 분류문제에직접사전훈련된신경망을적용합니다。새로운상을분류하려면 |
| 특징 추출 | 계층활성화를특징으로사용하여사전훈련된신경망을특징추출기로사용합니다。활성화를특징으로사용하여서포트벡터머신(SVM)과같은여타머신러닝모델을훈련시킬수있습니다。자세한내용은특징 추출항목을참조하십시오。예제는사전훈련된신경망을사용하여상특징추출하기항목을참조하십시오。 |
| 전이 학습 | 대규모데이터세트에서훈련된신경망의계층을가져와새로운데이터세트에대해미세조정합니다。자세한내용은전이 학습항목을참조하십시오。간단한예제는전이학습시작하기항목을참조하십시오。더많은사전훈련된신경망을사용해보려면새로운상을분류하도록딥러닝신경망훈련시키기항목을참조하십시오。 |
사전훈련된신경망비교하기
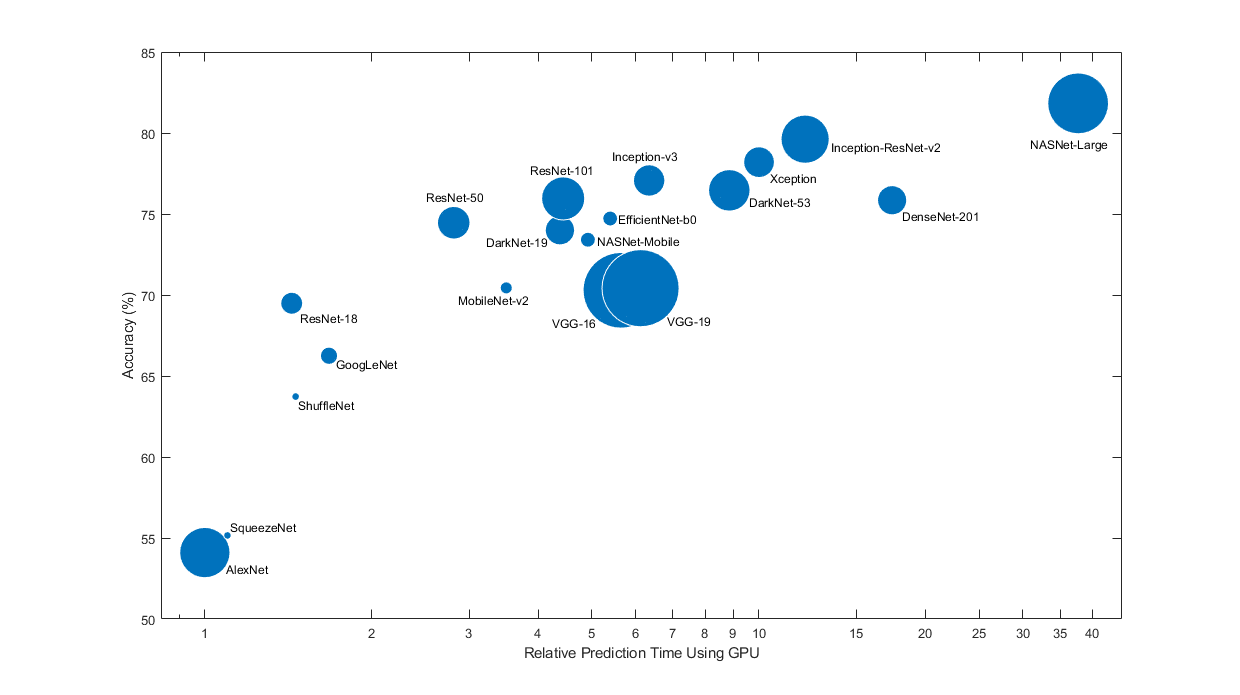
사전훈련된신경망은저마다다른특징을갖습니다。문제에적용할신경망을선택할때이러한특징을고려해야합니다。가장중한특징은신경망의정확도,속도및크기입니다。신경망을선택할때는일반적으로이러한특징사이의장단점을절충하여선택하게됩니다。아래플롯에서ImageNet검증정확도와이신경망을사용하여예측을수행하는데소요되는시간과비교해보십시오。
팁
전이학습을시작하려면SqueezeNet이나GoogLeNet과같이상대적으로속도가빠른신경망을선택해보십시오。그런다음빠르게반복하며데이터전처리단계와훈련옵션과같은다양한설정을사용해볼수있습니다。어느설정이적절한지파악했으면Inception-v3이나ResNet과같이보다정확한신경망을사용해보며결과가개선되는지살펴봅니다。
참고
위플롯은여러신경망의상대적속도를대략적으로만보여줍니다。정확한예측및훈련반복시간은사용하는하드웨어와미니배치크기에따라달라집니다。
양호한신경망은정확도가높고속도가빠릅니다。다음플롯에는최신gpu (英伟达®特斯拉®128年P100)와미니배치크기을사용했을때예측시간대비분류정확도가표시되어있습니다。예측시간은가장빠른신경망을기준으로측정되었습니다。각마커의면적은디스크에있는신경망의크기에비례합니다。
ImageNet검증세트에대한분류정확도는ImageNet에서훈련된신경망의정확도를측정하는가장일반적인방법입니다。ImageNet에서정확한신경망은보통전이학습이나특징추출을사용하여다른자연영상데이터세트에적용할때도정확합니다。이러한일반화는이들신경망이다른비슷한데이터세트로일반화되는자연영상으로부터강력하고정보가많은특징을추출하도록학습되었기때문에가능합니다。그러나ImageNet에서의높은정확도가항상다른작업으로곧바로전이되는것은아니므로여러신경망을시도해보는것이좋습니다。
한정된하드웨어나인터넷을통해분산신경망을사용하여예측을수행하려는경우에는디스크와메모리에있는신경망의크기도고려하십시오。
신경망정확도
ImageNet검증세트에대해분류정확도를계산하는방법에는여러가지가있으며,소스마다서로다른방법을사용합니다。여러모델의앙상블이사용되는경우도있고,각영상을여러번잘라서여러번평가하는경우도있습니다。` ` ` `준(top-1)정확도대신top-5정확도를사용하는경우도있습니다。이러한차이때문에서로다른소스간에는정확도를직접비교하는것이불가능한경우가종종있습니다。深度学习工具箱™의사전훈련된신경망의정확도는단일모델과단일중앙영상자르기를사용하는표준(()정확도입니다。
사전훈련된신경망불러오기
SqueezeNet신경망을불러오려면명령줄에squeezenet을입력하십시오。
网=挤压网;
다른신경망을불러오려면googlenet과같은함수를사용하여애드온탐색기에서사전훈련된신경망을다운로드하는링크를가져오십시오。
다음표에는ImageNet에서사전훈련된신경망과그속성중일부가나열되어있습니다。신경망심도는입력계층에서출력계층까지이르는경로에있는순차컨벌루션계층또는완전연결계층의가장큰개수로정의됩니다。모든신경망의입력값은RGB상입니다。
| 신경망 | 심도 | 크기 | 파라미터(단위:백만) | 상입력크기 |
|---|---|---|---|---|
squeezenet |
18 | 5.2 mb |
1.24 | 227×227 |
googlenet |
22 | 27 mb |
7.0 | 224×224 |
inceptionv3 |
48 | 89 mb |
23.9 | 299×299 |
densenet201 |
201 | 77 mb |
20.0 | 224×224 |
mobilenetv2 |
53 | 13 mb |
3.5 | 224×224 |
resnet18 |
18 | 44 mb |
11.7 | 224×224 |
resnet50 |
50 | 96 mb |
25.6 | 224×224 |
resnet101 |
101 | 167 mb |
44.6 | 224×224 |
xception |
71 | 85 mb |
22.9 | 299×299 |
inceptionresnetv2 |
164 | 209 mb |
55.9 | 299×299 |
shufflenet |
50 | 5.4 mb | 1.4 | 224×224 |
nasnetmobile |
* | 20 mb | 5.3 | 224×224 |
nasnetlarge |
* | 332 mb | 88.9 | 331×331 |
darknet19 |
19 | 78 mb | 20.8 | 256×256 |
darknet53 |
53 | 155 mb | 41.6 | 256×256 |
efficientnetb0 |
82 | 20 mb | 5.3 | 224×224 |
alexnet |
8 | 227 mb |
61.0 | 227×227 |
vgg16 |
16 | 515 mb |
138 | 224×224 |
vgg19 |
19 | 535 mb |
144 | 224×224 |
* NASNet-Mobile신경망과NASNet-Large신경망은모듈로구성된선형시퀀스로이루어지지않습니다。
Places365에서훈련된GoogLeNet
표준GoogLeNet신경망은ImageNet데이터세트에서훈련되었지만,원하는경우Places365데이터세트에서훈련된신경망도불러올수있습니다[4].Places365에서훈련된신경망은영상을들판,공원,활주,로로비등365가지장소범주로분류합니다。地方365데이터세트에서훈련된사전훈련된GoogLeNet을불러오려면googlenet(“重量”、“places365”)를사용하십시오。전이학습을수행하여새로운작업을수행할때가장일반적인방법은ImageNet에서사전훈련된신경망을사용하는것입니다。새로운작업이장면분류와비슷한경우,Places365에서훈련된신경망을사용하면더높은정확도를얻을수있습니다。
사전훈련된신경망시각화하기
심층신경망디자이너를사용하여사전훈련된신경망을불러오고시각화할수있습니다。
deepNetworkDesigner (squeezenet)

계층속성을보고편집하려면계층을선택하십시오。계층속성에대한자세한정보를보려면계층이름옆에있는도움말아이콘을클릭하십시오。

새로만들기를클릭하여심층신경망디자이너에서사전훈련된다른신경망을살펴봅니다。

신경망을다운로드해야할경우에는원하는신경망에서잠시멈추고설치를클릭하여애드온탐색기를엽니다。
특징 추출
특징추출은전체신경망을훈련시키는데시간과노력을투입하지않고도딥러닝의강력한기능을사용할수있는쉽고빠른방법입니다。특징추출은훈련영상을한번만통과하면되기때문에GPU가없을때특히유용합니다。사전훈련된신경망을사용하여학습된영상특징을추출한다음그러한특징을사용하여분류기를훈련시킵니다。예를 들어fitcsvm(统计和机器学习工具箱)을사용하여서포트벡터머신분류기를훈련시킬수있습니다。
새로운데이터세트의크기가매우작을때특징추출을사용해보십시오。추출된특징에대해간단한분류기를훈련시키는것이기때문에훈련속도가매우빠릅니다。또한,학습할데이터가적기때문에신경망의더깊은계층을미세조정한다고해서정확도가높아질확률도낮습니다。
데이터가원본데이터와매우비슷하다면신경망의더깊은계층으로부터추출된보다구체적인특징이새로운작업에유용할수있습니다。
데이터가원본데이터와매우다르면신경망의더깊은계층으로부터추출된특징이작업에덜유용할수있습니다。신경망의앞쪽계층에서추출한보다일반적인특징에대해최종분류기를훈련시켜보십시오。새로운데이터세트의크기가매우크다면신경망을처음부터훈련시켜볼수도있습니다。
효과적marketing특징추출기로ResNet을들수있습니다。사전훈련된신경망을사용하여특징을추출하는방법을보여주는예제는사전훈련된신경망을사용하여상특징추출하기항목을참조하십시오。
전이 학습
사전훈련된신경망을출발점으로사용하여새로운데이터세트에서신경망을훈련시킴으로써신경망의더깊은계층을미세조정할수있습니다。전이학습을통해신경망을미세조정하는것이신경망을새로만들어훈련시키는것보다더빠르고간편한경우가종종있습니다。신경망은이미다양한영상특징을학습한상태지만,이신경망을미세조정하면사용자만의새로운데이터세트에특화된특징을학습할수있습니다。데이터세트의크기가매우크다면전이학습이처음부터훈련시키는것보다빠르지못할수있습니다。
팁
신경망을미세조정하면가장높은정확도를갖게되는경우가많습니다。데이터세트의크기가매우작은경우에는(클래스당영상20개미만)대신특징추출을사용해보십시오。
신경망을미세조정하는것은간단한특징추출에비해상대적으로속도가느리고더많은노력이필요하지만,신경망에서여러다른특징이추출되도록학습시킬수있으므로최종신경망이종종더정확합니다。새로운데이터세트의크기가매우작지만않다면신경망이새로운특징을학습할데이터가있는것이기때문에일반적으로미세조정이특징추출보다더효과적입니다。전이학습을수행하는방법을보여주는예제는심층신경망디자이너를사용한전이학습및새로운상을분류하도록딥러닝신경망훈련시키기항목을참조하십시오。

신경망가져오기및내보내기
TensorFlow®-Keras,咖啡및ONNX™(打开)神经网络交换모델형식에서신경망과신경망아키텍처를가져올수있습니다。훈련된신경망을onnx모델형식으로내보낼수도있습니다。
Keras에서가져오기
importKerasNetwork를사용하여TensorFlow-Keras에서사전훈련된신경망을가져옵니다。신경망과가중치는하나의HDF5 (.h5)파일에서가져오거나HDF5파일과JSON (. JSON)파일에서각각따로가져올수있습니다。자세한내용은importKerasNetwork를참조하십시오。
importKerasLayers를사용하여TensorFlow-Keras에서신경망아키텍처를가져옵니다。가중치를포함하거나포함하지않고신경망아키텍처를가져올수있습니다。신경망아키텍처와가중치는하나의HDF5 (.h5)파일에서가져오거나HDF5파일과JSON (. JSON)파일에서각각따로가져올수있습니다。자세한내용은importKerasLayers를참조하십시오。
Caffe에서가져오기
importCaffeNetwork함수를사용하여Caffe에서사전훈련된신경망을가져옵니다。Caffe模型动物园에는훈련된신경망이다수있습니다[5].원하는.prototxt및.caffemodel파일을다운로드하고,importCaffeNetwork를사용하여matlab®으로사전훈련된신경망을가져옵니다。자세한내용은importCaffeNetwork를참조하십시오。
Caffe신경망의신경망아키텍처를가져올수있습니다。원하는.prototxt파일을다운로드하고,importCaffeLayers를사용하여matlab으로신경망계층을가져옵니다。자세한내용은importCaffeLayers를참조하십시오。
ONNX에서가져오고내보내기
ONNX를중간형식으로이용하면ONNX모델을내보내거나가져올수있는다른종류의딥러닝프레임워크를함께운용할수있습니다。이러한프레임워크에는TensorFlow, PyTorch, Caffe2,微软®认知工具包(CNTK), Core ML, Apache MXNet™등이포함됩니다。
훈련된深度学习工具箱신경망을exportONNXNetwork함수를사용하여onnx로내보내십시오。그런다음ONXX모델가져오기를지원하는다른딥러닝프레임워크로ONNX모델을가져올수있습니다。
importONNXNetwork를사용하여onnx에서사전훈련된신경망을가져오고,importONNXLayers를사용하여가중치를포함하거나포함하지않고신경망아키텍처를가져옵니다。

오디오응용분야에대한사전훈련된신경망
深度学习工具箱를音频工具箱™와함께사용하여오디오및음성처리응용분야에대해사전훈련된신경망을사용합니다。
音频工具箱는사전훈련된VGGish및YAMNet신경망을제공합니다。vggish(音频工具箱)및yamnet(音频工具箱)함수를사용하여사전훈련된신경망과직접상호작용합니다。classifySound(音频工具箱)함수는소리를찾아서521개카테고리중하나로분류할수있도록YAMNet에대해필요한전처리와후처리를수행합니다。yamnetGraph(音频工具箱)함수를사용하여YAMNet온톨로지를살펴볼수있습니다。vggishFeatures(音频工具箱)함수는특징임베딩을추출하여머신러닝및딥러닝시스템에입력할수있도록VGGish에대해필요한전처리와후처리를수행합니다。오디오응용분야에대해딥러닝을사용하는것에대한자세한내용은音频应用的深度学习简介(音频工具箱)항목을참조하십시오。
VGGish와YAMNet을사용하여전이학습과특징추출을수행합니다。예제는预训练音频网络的迁移学习(音频工具箱)항목을참조하십시오。
GitHub의사전훈련된모델
최근에사전훈련된모델과예제를보려면MATLAB深度学习(GitHub)을참조하십시오。
예를들면다음과같습니다。
GPT-2, BERT,芬伯特와같은변환기모델은MATLAB变压器模型GitHub®리포지토리를참조하십시오。
사전훈련된YOLO-v4객체검출모델(예:YOLOv4-coco YOLOv4-tiny-coco)은目标检测预训练YOLO-v4网络GitHub리포지토리를참조하십시오。
참고 문헌
[1] ImageNet。http://www.image-net.org
[2] Russakovsky, O., Deng, J., Su, H.等。“ImageNet大规模视觉识别挑战。”国际计算机视觉杂志(IJCV)。115卷,第3期,2015年,第211-252页
[3] Zhou, Bolei, Aditya Khosla, Agata Lapedriza, Antonio Torralba和Aude Oliva。“场所:用于深度场景理解的图像数据库。”arXiv预印本:1610.02055(2016)。
[4]的地方。http://places2.csail.mit.edu/
咖啡动物园模型。http://caffe.berkeleyvision.org/model_zoo.html
참고 항목
alexnet|googlenet|inceptionv3|densenet201|darknet19|darknet53|resnet18|resnet50|resnet101|vgg16|vgg19|shufflenet|nasnetmobile|nasnetlarge|mobilenetv2|xception|inceptionresnetv2|squeezenet|importCaffeNetwork|importCaffeLayers|importKerasLayers|importKerasNetwork|exportONNXNetwork|importONNXLayers|importONNXNetwork|심층신경망디자이너
관련 항목
您也可以从以下列表中选择一个网站: