利用GPU和代码生成加速杂波仿真
这个示例展示了如何在图形处理单元(GPU)或通过代码生成(MEX)而不是MATLAB™解释器上模拟杂波。该实例将时空自适应处理(STAP)技术中的样本矩阵反演(SMI)算法应用于六元均匀线性阵列(ULA)机载雷达接收的信号。本例重点比较了GPU、代码生成和MATLAB解释器对杂波仿真的性能。您可以在示例中找到模拟和算法的详细信息时空自适应处理导论.
此示例的完整功能需要并行计算工具箱™和MATLAB Coder™。
杂波模拟
雷达系统工程师经常需要模拟杂波返回来测试信号处理算法,如STAP算法。然而,生成一个高保真的杂波返回涉及许多步骤,因此通常是昂贵的计算。例如,constantGammaClutter使用以下步骤模拟杂波:
将整个地形划分成小的杂波块。补丁的大小取决于方位角补丁的跨度和距离分辨率。
对于每个patch,计算其对应的参数,如随机回报、掠掠角、天线阵列增益等。
综合所有杂波补丁的收益,生成总杂波收益。
杂波斑块的数量取决于地形覆盖,但通常在数千到数百万的范围内。此外,上述所有步骤都需要对每个脉冲执行(假设使用脉冲雷达)。因此,杂波仿真往往是系统仿真中的高杆。
为了提高杂波模拟的速度,可以利用并行计算的优势。注意,后期脉冲返回的杂波可能取决于早期脉冲产生的信号,因此MATLAB提供了某些并行解决方案,例如万博 尤文图斯parfor,并不总是适用的。但是,由于每个补丁的计算独立于其他补丁的计算,因此适合于GPU加速。
如果你有一个受支持的GPU,万博1manbetx并且可以访问并行计算工具箱,那么你可以利用GPU来生成杂波返回gpuConstantGammaClutter而不是constantGammaClutter.在大多数情况下,使用gpuConstantGammaClutter系统对象™是您需要进行的唯一更改。
如果你有MATLAB Coder,你也可以通过为C生成C代码来加速杂波仿真onstantGammaClutter,编译它,并运行编译后的版本。在代码生成模式下运行时,此示例将进行编译stapclutter使用codegen命令:
codegen(“stapclutter”,“参数”,…{coder.Constant (maxRange)……coder.Constant (patchAzSpan)});
c的所有属性值onstantGammaClutter必须作为常量传递。代码生成命令将生成MEX文件stapclutter_mex,该文件将在循环中调用。
比较杂波模拟时间
为了比较MATLAB解释器、代码生成和GPU之间的杂波仿真性能,通过键入启动以下GUIstapcpugpu在MATLAB命令行中。启动的GUI如下图所示。
GUI的左侧包含四个图,分别显示原始接收信号、接收信号的角度多普勒响应、处理后的信号以及STAP处理权值的角度多普勒响应。相关处理的详细信息可以在示例中找到时空自适应处理导论.在GUI的右侧,通过在方位角方向(以度为单位)和最大杂波范围(以公里为单位)上修改杂波斑块跨度来控制杂波斑块的数量。然后单击开始按钮开始模拟,模拟5个相干处理间隔(CPI),其中每个CPI包含10个脉冲。处理后的信号和角度多普勒响应每CPI更新一次。
下一节将展示不同模拟运行的时间。在这些模拟中,每个脉冲由200个距离样本组成,距离分辨率为50米。杂波斑块跨度和最大杂波范围的组合可以得到不同数量的杂波斑块。例如,杂波斑块跨度为10度,最大杂波范围为5公里,意味着3600个杂波斑块。在以下系统配置下进行仿真:
CPU: Xeon X5650, 2.66 GHz, 24gb内存
GPU:特斯拉C2075, 6gb内存
计时结果如下图所示。
helperCPUGPUResultPlot
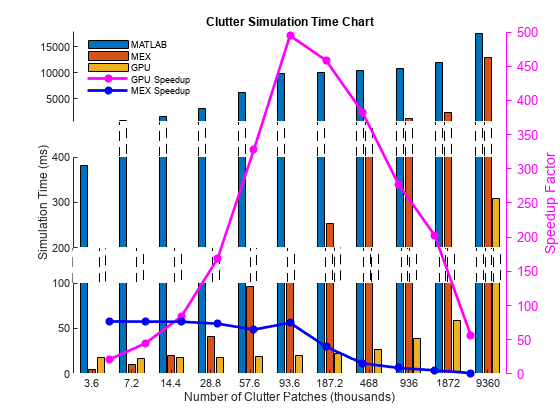
从图中可以看出,总体上GPU将模拟速度提高了几十倍,有时甚至是几百倍。两个有趣的发现是:
当杂波补丁数量较小时,只要数据能塞进GPU内存,GPU的性能几乎是恒定的。对于MATLAB解释器来说,情况并非如此。
一旦杂波补丁数量变大,数据就无法再放入GPU内存中。因此,GPU相对于MATLAB解释器提供的速度开始下降。然而,对于近千万的杂波补丁,GPU仍然提供了超过50倍的加速。
由于代码生成而产生的仿真速度的提高不如GPU速度的提高,但仍然是显著的。代码生成constantGammaClutter将收集到的杂波预先计算为常量值数组。对于大量的杂波补丁,数组的大小会变得太大,从而由于内存管理的开销而降低了速度的提高。代码生成需要访问MATLAB Coder,但不需要特殊的硬件。
其他模拟计时结果
尽管本例中使用的模拟计算了数百万个杂波补丁,但得到的数据立方体的大小为200 × 6 × 10,这表明每个脉冲、6个通道和10个脉冲中只有200个范围样本。与实际问题相比,这个数据立方体很小。本示例选择这些参数来展示使用GPU或代码生成可以获得的好处,同时确保示例在MATLAB解释器中合理的时间内运行。一些具有较大数据立方体的模拟产生了以下结果:
使用GPU进行模拟,为50个元素的ULA生成50个脉冲,每个脉冲中有5000个范围样本,即一个5000 × 50 × 50的数据立方体。距离分辨率为10米。雷达覆盖60度的总方位角,每个杂波斑块有1度。最大杂波范围为50公里。杂波斑块总数为305,000个。
使用GPU进行上述模拟的60倍加速,除了180度方位角覆盖和最大杂波范围等于地平线范围(约130公里)。在本例中,杂波斑块总数为2,356,801个。
总结
本例比较了使用MATLAB解释器、GPU或代码生成模拟杂波返回所获得的性能。结果表明,与MATLAB解释器相比,GPU和代码生成的速度有了很大的提高。
您也可以从以下列表中选择一个网站: