创建Simul万博1manbetxink环境和培训代理
这个例子演示了如何在watertank万博1manbetxSimulink®模型的一个强化学习深度确定性策略梯度(DDPG) agent。在MATLAB®中训练DDPG代理的示例,请参见培训DDPG Agent控制双积分系统.
水箱模型
本例的原始模型是水箱模型。目标是控制水箱中的水的水平。有关水箱型号的更多信息,请参见watertank仿万博1manbetx真软件模型(万博1manbetx仿真软件控制设计).
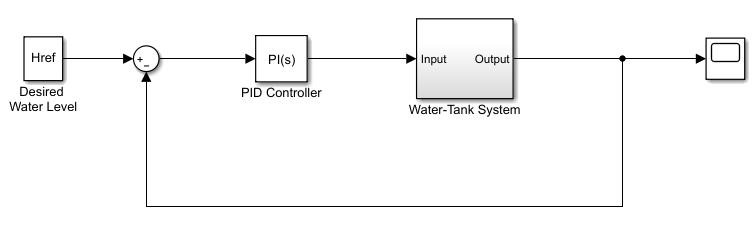
通过以下更改修改原始模型:
删除PID控制器。
插入RL Agent块。
连接观测向量 , 在哪里 是坦克的高度, , 是参考高度。
赏 .
配置终止信号,使得模拟停止如果 或 .
得到的模型是rlwatertank.slx.有关此模型和更改的更多信息,请参阅创建Simul万博1manbetxink强化学习环境.
Open_System(“rlwatertank”)

创建环境界面
创建环境模型包括定义以下内容:
操作和观察信号表示代理用于与环境交互。有关更多信息,请参见
rlNumericSpec和rlfinitesetspec..代理用于衡量其成功的奖励信号。有关更多信息,请参见定义奖励信号.
定义观察规范obsInfo和行为规范Actinfo..
obsInfo = rlNumericSpec([3 1],......'lowerimit',[ - inf-inf 0]'',......“UpperLimit”,[inf inf inf]');ObsInfo.name =.'观察';Obsinfo.description =.'集成错误,错误和测量高度';numObservations = obsInfo.Dimension (1);actInfo = rlNumericSpec([1 1]);actInfo。Name =“流”;数量= actinfo.dimension(1);
构建环境界面对象。
ent = rl万博1manbetxsimulinkenv(“rlwatertank”,'rlwatertank / rl代理',......obsInfo actInfo);
设置一个自定义重置函数,随机化模型的参考值。
env。ResetFcn = @(在)localResetFcn(的);
指定模拟时间TF.以及样本时间TS.在几秒钟内。
t = 1.0;Tf = 200;
修复随机发生器种子以进行再现性。
RNG(0)
创建DDPG代理
鉴于观察和动作,DDPG代理使用批评值函数表示来近似长期奖励。要创建评论家,首先创建一个具有两个输入,观察和动作的深度神经网络,以及一个输出。有关创建深度神经网络值函数表示的更多信息,请参阅创建策略和值函数表示.
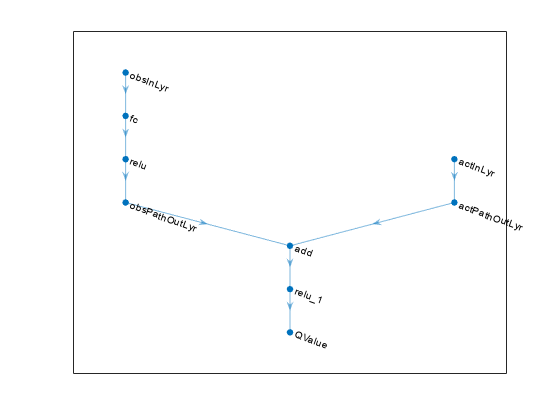
statePath = [featureInputLayer(numObservations,'正常化',“没有”,“名字”,'状态') fullyConnectedLayer (50,“名字”,“CriticStateFC1”) reluLayer (“名字”,'rictrelu1') fullyConnectedLayer (25,“名字”,“CriticStateFC2”));actionPath = [featureInputLayer(numActions,'正常化',“没有”,“名字”,'行动') fullyConnectedLayer (25,“名字”,'批评FC1'));commonPath =[附加路径]“名字”,'添加') reluLayer (“名字”,“CriticCommonRelu”)全连接层(1,“名字”,“CriticOutput”));criticNetwork = layerGraph ();criticNetwork = addLayers (criticNetwork statePath);criticNetwork = addLayers (criticNetwork actionPath);criticNetwork = addLayers (criticNetwork commonPath);criticNetwork = connectLayers (criticNetwork,“CriticStateFC2”,“添加/三机一体”);criticNetwork = connectLayers (criticNetwork,'批评FC1',“添加/ in2”);
查看critical网络配置。
图绘制(criticNetwork)
为使用的批评家表示指定选项rlRepresentationOptions.
criticOpts = rlRepresentationOptions (“LearnRate”,1e-03,“GradientThreshold”1);
使用指定的深度神经网络和选项创建批评批评表示。您还必须指定从环境界面获取的批评者的操作和观察规范。有关更多信息,请参见rlqvalueerepresentation.
评论家= rlQValueRepresentation (criticNetwork obsInfo actInfo,'观察', {'状态'},'行动', {'行动'}, criticOpts);
根据观察结果,DDPG代理使用参与者表示来决定采取什么行动。要创建参与者,首先创建一个深度神经网络,有一个输入,一个观察,和一个输出,一个动作。
以与评论家相似的方式构造行动者。有关更多信息,请参见RLDETerminyActorRepresentation.
ActorNetWork = [FeatureInputLayer(numobservations,'正常化',“没有”,“名字”,'状态')全连接列(3,“名字”,'Actorfc')Tanhlayer(“名字”,“actorTanh”)全连接列(数量,“名字”,'行动')];ACTOROPTIONS = RLREPRESENTATIONOPTIONS(“LearnRate”,1E-04,“GradientThreshold”1);演员= rlDeterministicActorRepresentation (actorNetwork obsInfo actInfo,'观察', {'状态'},'行动', {'行动'},ActorOptions);
要创建DDPG代理,首先使用rlDDPGAgentOptions.
代理= rlddpgagentoptions(......'采样时间'Ts,......“TargetSmoothFactor”,1e-3,......“DiscountFactor”, 1.0,......'迷你atchsize', 64,......“ExperienceBufferLength”1 e6);agentOpts.NoiseOptions.Variance = 0.3;agentOpts.NoiseOptions.VarianceDecayRate = 1 e-5;
然后,使用指定的参与者表示、评论家表示和代理选项创建DDPG代理。有关更多信息,请参见rlddpgagent..
代理= rlDDPGAgent(演员、评论家、agentOpts);
火车代理
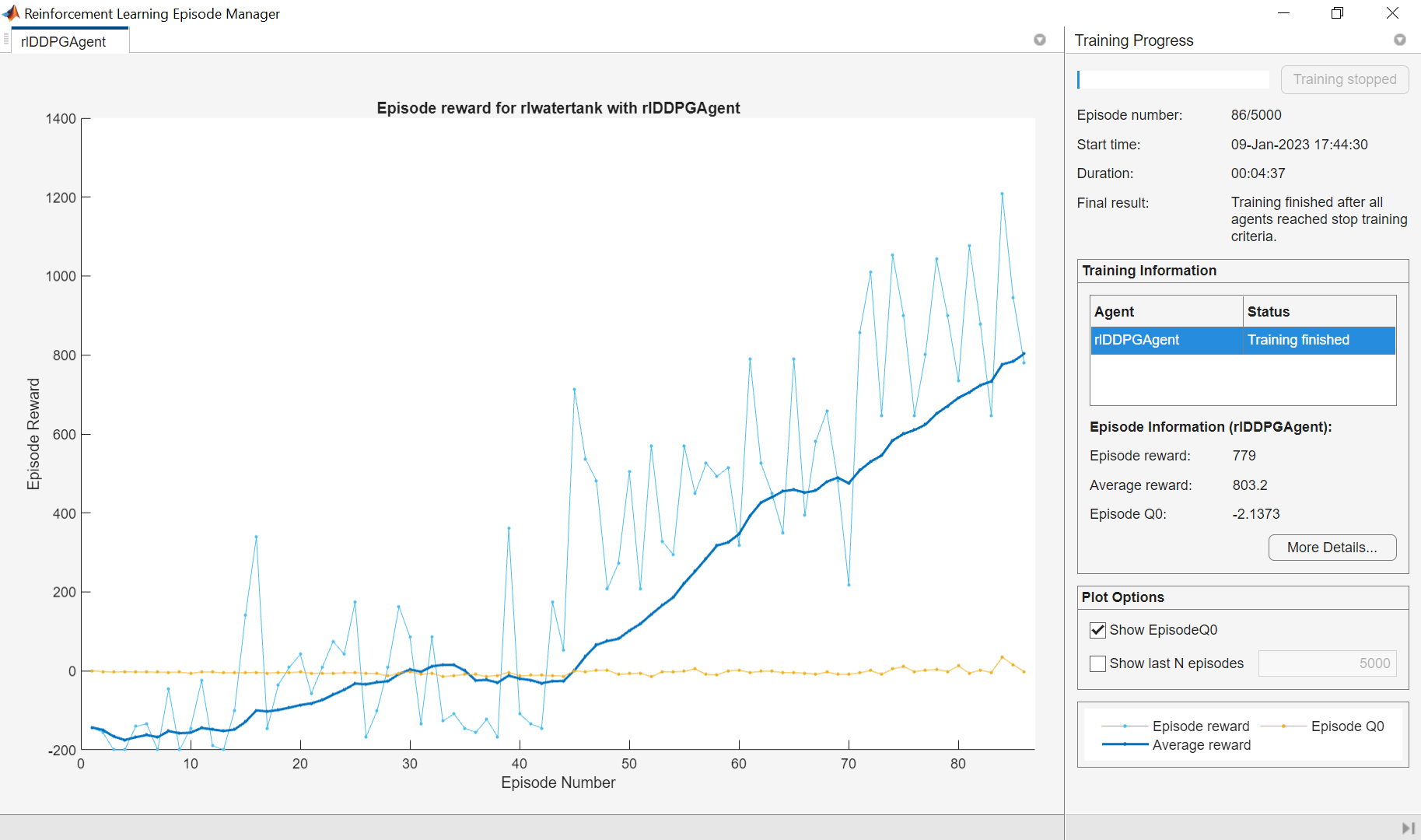
要培训代理,首先指定培训选项。对于此示例,请使用以下选项:
最多运行每个培训
5000剧集。指定每个剧集最多持续装天花板(Tf / Ts)(那是200)时间步骤。在Episode Manager对话框中显示培训进度(设置
绘图选项),并禁用命令行显示(设置详细的选择假)。停止训练时,代理收到的平均累积奖励大于
800在20.连续集。此时,药剂可以控制水箱内的水位。
有关更多信息,请参见rlTrainingOptions.
maxepisodes = 5000;maxsteps = ceil(tf / ts);训练= rltrainingOptions(......'maxepisodes',maxepisodes,......'maxstepperepisode'maxsteps,......“ScoreAveragingWindowLength”,20,......'verbose'假的,......“阴谋”,'培训 - 进步',......“StopTrainingCriteria”,'平均',......“StopTrainingValue”, 800);
使用培训代理商使用火车功能。培训是一个计算密集型进程,需要几分钟才能完成。要在运行此示例的同时节省时间,请通过设置加载预制代理doTraining到假.自己训练代理人,设置doTraining到真正的.
doTraining = false;如果doTraining%训练代理人。TrainingStats =火车(代理商,ENV,训练);其他的%加载预磨料的代理。加载('watertankddpg.mat','代理人')结束
验证培训的代理
通过仿真验证了该模型的有效性。
simOpts = rlSimulationOptions ('maxsteps'maxsteps,'stoponerror',“上”);经验= sim (env,代理,simOpts);

本地功能
函数在= localresetfcn(in)%随机化参考信号blk = sprintf('rlwatertank / veanced \ nwater等级');H = 3*randn + 10;而h <= 0 ||h> = 20 h = 3 * randn + 10;结束在= setBlockParameter(黑色,“价值”num2str (h));%随机化初始高度H = 3*randn + 10;而h <= 0 ||h> = 20 h = 3 * randn + 10;结束黑色='rlwatertank /水箱系统/ h';在= setBlockParameter(黑色,'初始条件'num2str (h));结束
另请参阅
相关的话题
你也可以从以下列表中选择一个网站: