이번역페이지는최신내용을담고있지않습니다。최신내용을문으로보려면여기를클릭하십시오。
분류
이예제에서는판별분석,나이브베이즈분류기,결정트리를사용하여분류를수행하는방법을보여줍니다。여러변수(예측변수라고함)의측정값과각각의알려진클래스레이블이있는관측값을포함하는데이터세트가있다고가정하겠습니다。새관측값의예측변수값을구하면이러한관측값이속해있을수있는클래스를확인할수있을까요?이것이바로분류의문제입니다。
피셔(费雪)의붓꽃데이터
피셔의붓꽃데이터는150개붓꽃표본의꽃받침길이,꽃받침너비,꽃잎길이,꽃잎너비에대한측정값으로구성되어있습니다。세종에서각각50개의본이추출되었습니다。데이터를불러오고꽃받침측정값이두종사이에어떻게다른지확해봅니다。꽃받침측정값을포함하는두열을사용할수있습니다。
负载fisheririsF =数字;Gscatter (meas(:,1), meas(:,2), species,“rgb”,osd的);包含(“花萼长度”);ylabel (萼片宽的);

N = size(meas,1);
한붓꽃의꽃받침과꽃잎을측정하고이러한측정값을기반으로하여해당종을확인해야한다고가정하겠습니다。이문제를해결할수있는한가지방법으로판별분석(判别分析)이알려져있습니다。
선형판별분석및2차판별분석
fitcdiscr함수는여러유형의판별분석을사용하여분류를수행할수있습니다。먼저,디폴트선형판별분석(lda)을사용하여데이터를분류하겠습니다。
Lda = fitcdiscr(meas(:,1:2),物种);ldaClass = resubPredict(lda);
알려진클래스레이블을갖는관측값을대개훈련데이터(训练数据)라고합니다。이제재대입오차,즉훈련세트에대한오분류오차(오분류된관측값의비율)를계산합니다。
ldaResubErr = resubLoss(lda)
ldaResubErr = 0.2000
또한,훈련세트에대한혼동행렬을계산할수도있습니다。혼동행렬에는알려진클래스레이블과예측된클래스레이블에대한정보가포함됩니다。일반적으로,혼동행렬에서(i, j)요소는알려진클래스레이블이클래스我이고예측된클래스가j인표본개수입니다。대각선소는올바르게분류된관측값을나타냅니다。
图ldaResubCM =混淆图(物种,ldaClass);
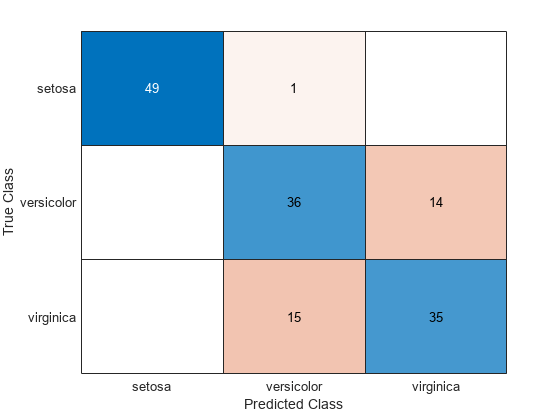
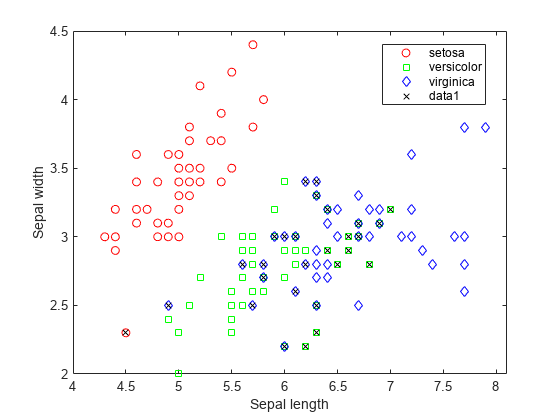
150개훈련측정값의20%,즉30개관측값이선형판별분석함수에의해오분류되었습니다。오분류된점에x를그려이러한점을@시할수있습니다。
图(f) bad = ~strcmp(ldaClass,species);持有在;情节(量(坏,1),量(坏,2),“kx”);持有从;
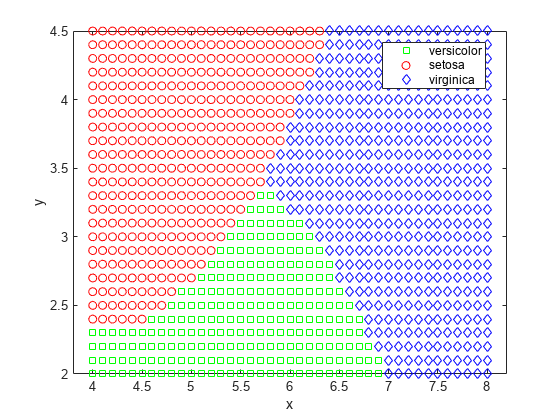
이함수는평면을선으로분할된、역으로나누고여러、이함수는평면을선으로분할된、역을여러종에할당했습니다。이러한역을시각화하는한가지방법은(x, y)값으로구성된그리드를생성하고분류함수를해당그리드에적용하는것입니다。
[x,y] = meshgrid(4:.1:8,2:.1:4.5);X = X (:);Y = Y (:);J = category ([x y],meas(:,1:2),species);gscatter (x, y, j,“伽马线暴”,‘草地’)

데이터세트에따라여러클래스의역이선으로제대로분리되지않는경우가있습니다。이런경우,선형판별분석이적합하지않습니다。대신,데이터에2차판별분석(qda)을시도해볼수있습니다。
2차판별분석에대한재대입오차를계산합니다。
Qda = fitcdiscr(meas(:,1:2),物种,“DiscrimType”,“二次”);qdaResubErr = resubLoss(qda)
qdaResubErr = 0.2000
재대입오차를계산했습니다。일반적으로많은사람들이독립적인세트에대해예상되는예측오차인검정오차(일반화오차라고도함)에관심이많습니다。실제로,재대입오차가검정오차보다작게추정될가능성이높습니다。
이경우,레이블이지정된다른데이터세트가없지만교차검증을수행하여이를시뮬레이션할수있습니다。층화된10겹교차검증이분류알고리즘에서검정오차를추정하는데흔히사용되는방법입니다。이방법은훈련세트를10개의서로소부분집합으로임의로나눕니다。각부분집합은크기가대략같으며그클래스비율도훈련세트에서의클래스비율과대략같습니다。한부분집합을제외하고나머지9개부분집합을사용하여분류모델을훈련시킨후,제외한부분집합을훈련된모델을사용하여분류합니다。10개부분집합을한번에하나씩제외시키며이작업을반복할수있습니다。
교차검증이데이터를임의로나누기때문에검증결과는초기난수시드값에따라달라집니다。이예제의결과를정확히재현하기위해다음명령을실행합니다。
rng (0,“旋风”);
먼저,cvpartition을사용하여10개의층화된서로소부분집합을생성합니다。
Cp = cvpartition(species,“KFold”, 10)
cp = K-fold交叉验证分区NumObservations: 150 NumTestSets: 10 TrainSize: 135 135 135 135 135 135 135 135 135 135 135 135 TestSize: 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15 15
crossval메서드와kfoldLoss메서드는주어진데이터분할cp를사용하여lda와qda모두에대한오분류오차를추정할수있습니다。
층화된10겹교차검을사용하여lda에대한실제검정오차를추정합니다。
Cvlda = crossval(lda,“CVPartition”, cp);ldaCVErr = kfoldLoss(cvlda)
ldaCVErr = 0.2000
이데이터에서lda교차검오차는lda재대입오차와동일한값을가집니다。
층화된10겹교차검을사용하여qda에대한실제검정오차를추정합니다。
Cvqda = crossval(qda,“CVPartition”, cp);qdaCVErr = kfoldLoss(cvqda)
qdaCVErr = 0.2200
Qda가lda보다교차검오차가약간더큽니다。이는복잡한모델보다단순한모델에서더견줄만한,즉더나은성능을얻을수있음을보여줍니다。
나이브베이즈분류기
fitcdiscr함수에는두가지다른유형“DiagLinear”와“DiagQuadratic”이있습니다。이는“线性”및“二次”과유사하지만대각공분산행렬추정값을사용합니다。이러한대각옵션은클래스레이블이주어진경우변수가조건부로독립적임을가정하므로나이브베이즈분류기를보여주는구체적인예가됩니다。나이브베이즈분류기는가장많이사용되는분류기중하나입니다。일반적으로두변수가클래스에조건부로독립적이라는가정이맞지는않지만,실제로많은데이터세트에서나이브베이즈분류기가제대로역할을하는것으로확인되었습니다。
fitcnb함수를사용하면더일반적나이브베이즈분류기유형을생성할수있습니다。
먼저,가우스분포를사용하여각클래스에포함된각각의변수를모델링합니다。재대입오차와교차검오차를계산할수있습니다。
nbGau = fitcnb(meas(:,1:2),种);nbGauResubErr = nbGau
nbGauResubErr = 0.2200
nbGauCV = crossval(nbGau,“CVPartition”, cp);nbGauCVErr = kfoldLoss(nbGauCV)
nbGauCVErr = 0.2200
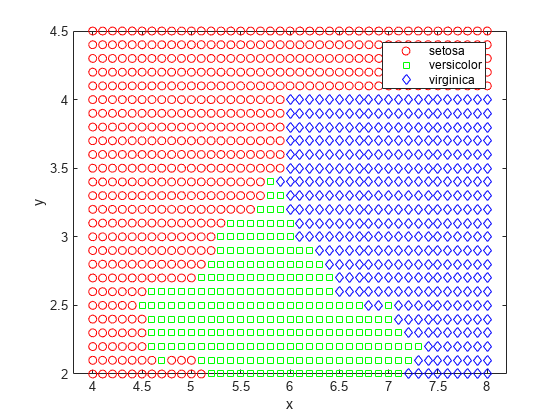
标签=预测(nbGau, [x y]);gscatter (x, y,标签,“伽马线暴”,‘草地’)
지금까지는각클래스의변수가다변량정규분포를가진다고가정했습니다。이가정이타당한경우가많지만,이렇게가정하고싶지않거나이러한가정이유효하지않다는것을확실히알수있는경우가있습니다。이제,더유연한비모수적기법인커널밀도추정을사용하여각클래스에포함된각변수를모델링하겠습니다。여기서는커널을盒子로설정합니다。
nbKD = fitcnb(meas(:,1:2), species,“DistributionNames”,“内核”,“内核”,“盒子”);nbKDResubErr = rebloss (nbKD)
nbKDResubErr = 0.2067
nbKDCV = crossval(nbKD,“CVPartition”, cp);nbKDCVErr = kfoldLoss(nbKDCV)
nbKDCVErr = 0.2133
标签=预测(nbKD, [x y]);gscatter (x, y,标签,“rgb”,osd的)
이데이터세트에대해커널밀도추정을사용하는나이브베이즈분류기는가우스분포를사용하는나이브베이즈분류기보다더작은재대입오차와교차검증오차를가집니다。
결정 트리
결정트리를기반으로하는또다른분류알고리즘이있습니다。결정트리는”꽃받침길이가5.45보다작은경우이표본을setosa로분류한다”와같은단순한규칙집합입니다。또한,결정트리는각클래스의변수분포에대한어떠한가정도필요로하지않으므로비모수적기법입니다。
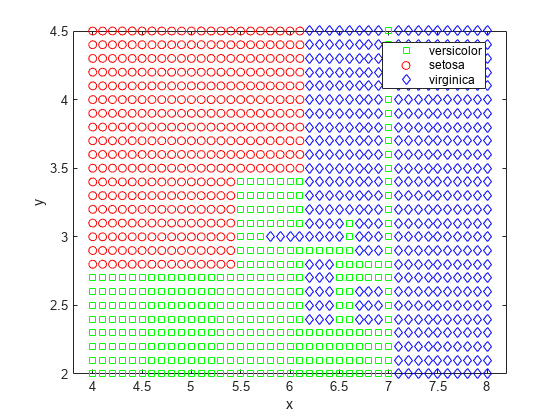
fitctree함수는결정트리를생성합니다。붓꽃데이터에대한결정트리를생성하고결정트리가붓꽃을종으로얼마나잘분류하는지를확인해봅니다。
T = fitctree(meas(:,1:2),种,“PredictorNames”, {“SL”“西南”});
결정트리방법이평면을나누는과정을보면흥미롭습니다。위에나와있는동일한기법을사용하여각종에할당된역을시각화합니다。
[grpname,node] = predict(t,[x y]);grpname gscatter (x, y,“伽马线暴”,‘草地’)
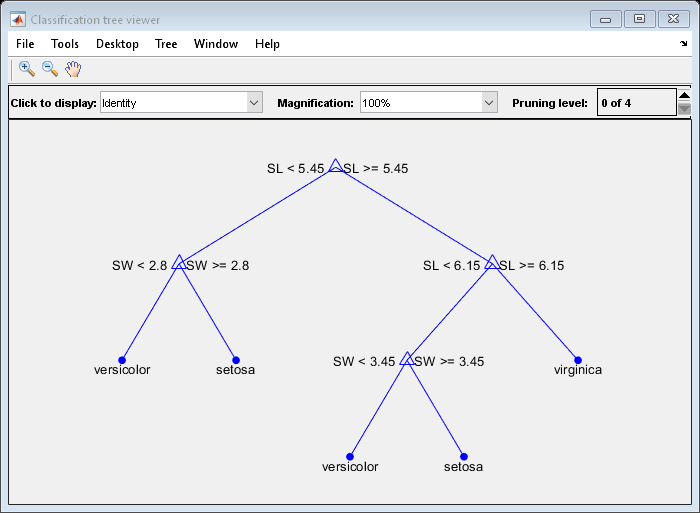
결정트리를시각화하는또다른방법은결정규칙과클래스할당을보여주는도식을그리는것입니다。
视图(t)“模式”,“图”);
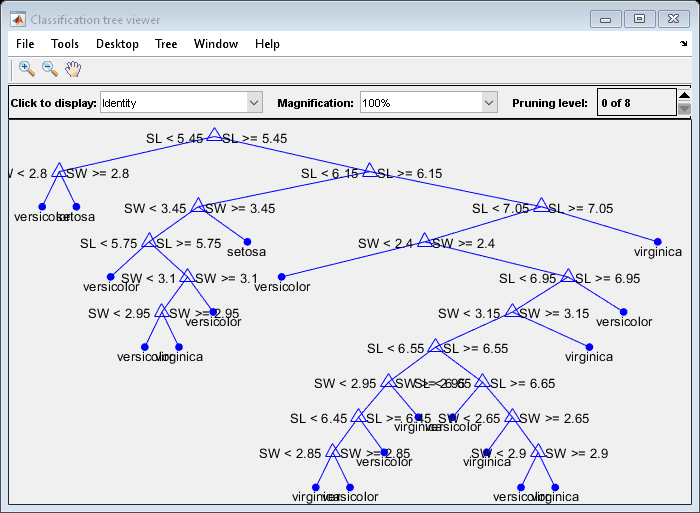
이복잡해보이는트리는" SL < 5.45”형식의일련의규칙을사용하여각표본을19개종점노드중하나로분류합니다。하나의관측값에대한종할당을확인하려면최상위노드에서시작하여규칙을적용하십시오。점이규칙을충족하면왼쪽경로를취하고,충족하지않으면오른쪽경로를취합니다。최종적으로,관측값을3개종중하나에할당하는종점노드에도달하게됩니다。
결정트리에대한재대입오차와교차검오차를계산합니다。
dtResubErr = resubLoss(t)
dtResubErr = 0.1333
CVT =交叉val(t,“CVPartition”, cp);dtCVErr = kfoldLoss(cvt)
dtCVErr = 0.3000
결정트리알고리즘의경우교차검증오차추정값이재대입오차추정값보다훨씬더큽니다。이는생성된트리가훈련세트에과적합되었다는것을보여줍니다。다시말해서이는원래훈련세트를올바르게분류하는트리이지만,트리의구조가이특정훈련세트에민감하므로,새데이터에대한성능이저하될가능성이높습니다。대개의경우,새데이터에대해복잡한트리보다성능이더높은단순한트리를찾을수있습니다。
트리를가지치기해봅니다。먼저,원래트리의다양한부분집합에대한재대입오차를계산합니다。그런다음,이하위트리에대한교차검오차를계산합니다。그래프를보면재대입오차가지나치게낙관적임을알수있습니다。트리크기가증가하면항상재대입오차가감소하지만,특정점을넘어가면트리크기가증가함에따라교차검증오차율이증가합니다。
resubcost = resubLoss(t“子树”,“所有”);[cost,secost,ntermnodes,bestlevel] = cvloss(t,“子树”,“所有”);情节(ntermnodes、成本“b -”ntermnodes resubcost,“r——”)图(gcf);包含('终端节点数量');ylabel (成本(错误分类错误))传说(交叉验证的,“Resubstitution”)
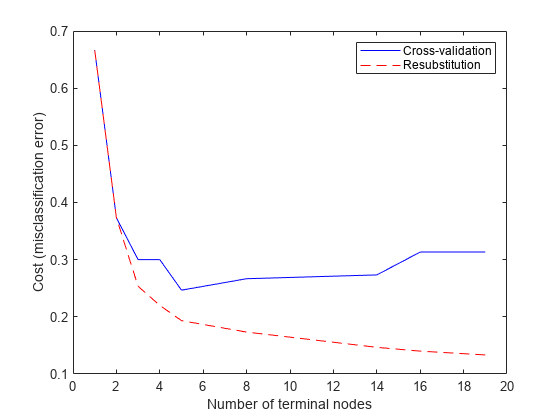
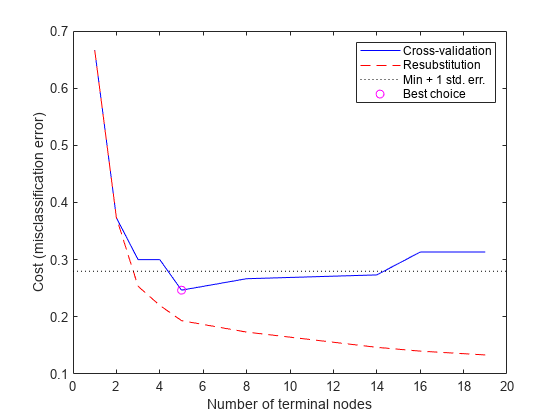
어떤트리를선택해야할까?간단한규칙은교차검오차가가장작은트리를선택하는것입니다。이규칙에만족할수도있지만,더복잡한트리와거의동일하게양호한더단순한트리를사용하고자할수있습니다。이예제에서는최솟값의1 @ @준오차내에서가장단순한트리를선택하겠습니다。이것이ClassificationTree의cvloss메서드에서사용하는디폴트규칙입니다。
최소비용과1표준오차를더한값에해당하는절단값을계산하여그래프에이를표시할수있습니다。cvloss메서드에서계산되는“최상의”수준은이절단값아래에있는최솟값트리입니다。(참고로,bestlevel=0은가지치기된트리에해당하므로cvloss에서계산되는벡터출력값에대한marketing덱스로이를사용하려면1을더해야합니다.)
[mincost,minloc] = min(成本);Cutoff = mincost + secost(minloc);持有在Plot ([0 20], [cutoff cutoff],凯西:”(ntermnodes(bestlevel+1), cost(bestlevel+1),“莫”)传说(交叉验证的,“Resubstitution”,'Min + 1标准。err。',“最好的选择”)举行从
마지막으로,가지치기된트리를살펴보고이트리에대해추정된오분류오차를계산할수있습니다。
Pt = prune(t,“水平”, bestlevel);视图(pt,“模式”,“图”)
成本(bestlevel + 1)
Ans = 0.2467
결론
이예제에서는MATLAB®에서统计和机器学习工具箱™함수를사용하여분류를수행하는방법을보여줍니다。
이예제는피셔(费雪)의붓꽃데이터에대한최적의분석이아닙니다。사실상꽃받침측정값대신또는이와함께꽃잎측정값을사용할경우더나은분류결과를얻을수있습니다。또한,이예제는여러분류알고리즘의장점과단점을비교하려는것이아닙니다。다른데이터세트에대한분석을수행하고여러알고리즘을비교하는것이유용할수있습니다。또한,다른분류알고리즘을구현하는工具箱함수도있습니다。예를들어,使用TreeBagger的分类树的Bootstrap聚合(Bagging)예제에설명된것처럼TreeBagger를사용하여결정트리의앙상블에대해부트스트랩집계를수행할수있습니다。
您也可以从以下列表中选择一个网站: