ClassificationEnsemble
包裹:classreg.learning.classif.
超类:CompactClassificationEnsemble
集成分类器
描述
ClassificationEnsemble结合一组训练过的弱学习者模型和这些学习者训练过的数据。它可以通过聚合弱学习者的预测来预测新数据的集成响应。它存储用于训练的数据,可以计算重新替换预测,如果需要,还可以恢复训练。
建造
使用创建分类集成对象fitcensemble..
特性
|
数值预测器的箱边,指定为P数字向量,在哪里P是预测值的数量。每个向量包括数值预测器的箱边。分类预测器单元格数组中的元素为空,因为软件不存储分类预测器。 仅当您指定 您可以重现Binned Predictor数据 x = mdl.x;%predictor数据xbinned = zeros(size(x));边缘= mdl.bineges;%查找箱预测因子的指数。idxnumeric = find(〜cellfun(@ isempty,边));如果是iscumn(idxnumeric)idxnumeric = idxnumeric';j = idxnumeric x = x(:,j);如果x是表,%将x转换为数组。如果是Istable(x)x = table2array(x);结束%X通过使用X进入垃圾箱
Xbinned包含用于数字预测器的容器索引,范围从1到容器数量。Xbinned分类预测值的值为0。如果X包含楠s,然后相应的Xbinned价值观是楠s。 |
|
分类预测索引指定为正整数的向量。 |
|
中的元素列表 |
|
描述如何的字符矢量 |
|
方矩阵,在哪里 |
|
扩展的预测器名称,存储为字符向量的单元格数组。 如果模型对分类变量使用编码,那么 |
|
拟合信息的数字数组。这个 |
|
描述向量的意义 |
|
超参数的交叉验证优化的描述,存储为a
|
|
具有集合中弱学习者名称的字符向量单元数组。每个学习者的名字只出现一次。例如,如果有100棵树的集合, |
|
描述创造方法的字符矢量 |
|
用于培训的参数 |
|
数字标量包含培训数据中的观察次数。 |
|
培训的弱学习者数量 |
|
预测器变量的名称单元格数组,按它们出现的顺序排列 |
|
每个类别的先验概率的数值向量。元素的顺序 |
|
描述原因的字符矢量 |
|
带有响应变量名称的字符向量 |
|
用于转换分数的功能手柄,或表示内置变换函数的字符矢量。 添加或更改 ens.ScoreTransform = '作用' 或者 ens.ScoreTransform = @作用 |
|
训练分类模型的细胞矢量。
|
|
网络中弱学习者训练权重的数值向量 |
|
大小逻辑矩阵 如果合奏不是类型 |
|
按比例缩小的 |
|
训练集合的预测值矩阵或表。每一列的 |
|
数字向量、分类向量、逻辑向量、字符数组或字符向量的单元格数组。每行 |
目标函数
紧凑的 |
紧凑分类集成 |
比较控股 |
使用新数据比较两个分类模型的准确性 |
克罗斯瓦尔 |
交叉验证合奏 |
边 |
分类边缘 |
聚集 |
收集属性统计和机器学习工具箱来自GPU的对象 |
石灰 |
局部可解释模型不可知解释(LIME) |
损失 |
分类错误 |
利润 |
分类的利润率 |
部分依赖 |
计算部分依赖 |
plotPartialDependence |
创建部分依赖图(PDP)和单个条件期望图(ICE) |
预测 |
使用分类模型集成对观测值进行分类 |
预测重要性 |
决策树分类集成中预测器重要性的估计 |
再沉积 |
通过重新替换对边缘进行分类 |
恢复 |
重新替换导致的分类错误 |
resubMargin |
通过重新替换的分类边距 |
再预测 |
分类在分类模型的集合中的观察 |
简历 |
恢复训练合奏 |
夏普利 |
福利价值观 |
testckfold. |
通过重复的交叉验证比较两个分类模型的精度 |
复制语义
要了解值类如何影响复制操作,请参阅复制对象.
例子
列车推进分类集成
加载电离层数据集。
负载电离层
使用所有的测量值和adaboostm1.方法。
Mdl = fitcensemble (X, Y,'方法',“AdaBoostM1”)
mdl = classificationsemble racatectename:'y'pationoricalpricictors:[] classnames:{'b'g'} scoreTransform:'none'numobservations:351 numtromed:100方法:'adaboostm1'学员:{'树'}原理:'正常终止完成所要求的培训周期后。fitinfo:[100x1 double] fitinfodescription:{2x1 cell}属性,方法
Mdl是A.ClassificationEnsemble模型对象。
Mdl.训练有素是存储经过训练的分类树的100×1单元向量的属性(CompactClassificationTree.组成集合的模型对象。
绘制第一个训练的分类树的图。
视图(Mdl.Trained{1},“模式”,'图形')
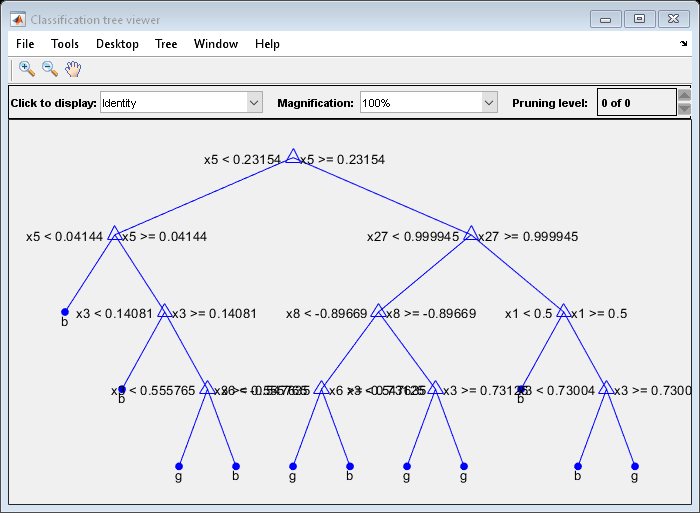
默认情况下,fitcensemble.为树木的增强集合增长浅树。
预测均值的标签X.
predmeanx =预测(mdl,均值(x))
predmeanx =1 x1单元阵列{' g '}
提示
对于分类树的集合训练有素性质恩斯存储一个ens.NumTrained-1 Compact分类模型的1个细胞矢量。用于树的文本或图形显示T在单元向量中,输入:
查看(ens.tromed {对于使用LogitBoost或GentleBoost聚合的集成。T}.Compact(学习者)查看(ens.tromed {对于所有其他聚合方法。T})
扩展能力
您还可以从以下列表中选择网站:
