가우스혼합모델을사용하여군집화하기
이항목에서는统计和机器学习工具箱™함수集群를사용하여가우스혼합모델(gmm)로군집화하는방법을소개하고,fitgmdist를사용하여GMM모델을피팅할때선택적파라미터를지정하면어떠한효과가있는지보여주는예제를살펴봅니다。
가우스혼합모델이데이터를군집화하는방법
가우스혼합모델(gmm)은데이터군집화에자주사용됩니다。Gmm을사용하여,쿼리데이터에대해하드군집화또는소프트군집화를수행할수있습니다。
GMM은주어진데이터에대해성분사후확률을극대화하는다변량정규성분에쿼리데이터점을할당하여하드군집화를수행합니다。즉,피팅된gmm이주어진경우,集群는가장높은사후확률을생성하는성분에쿼리데이터를할당합니다。하드군집화는정확히하나의군집에하나의데이터점을할당합니다。GMM을데이터에피팅하고피팅된모델을사용하여군집화하며성분사후확률을추정하는방법을보여주는예는基于硬聚类的高斯混合数据聚类항목을참조하십시오。
또한gmm을사용하여데이터에대해보다유연한군집화를수행할수있는데,이방식을소프트(또는)퍼지)군집화라고합니다。소프트군집화방법은각군집에대한데이터점에점수를할당합니다。점수값은군집에대한데이터점의연결강도를나타냅니다。하드군집화방법과달리,소프트군집화방법은둘이상의군집에데이터점을할당할수있기때문에유연합니다。GMM군집화를수행할경우점수는사후확률입니다。Gmm을사용한소프트군집화의예는基于软聚类的高斯混合数据聚类항목을참조하십시오。
GMM군집화는크기와상관관계구조가각기다른군집을수용할수있습니다。따라서특정응용사례에서는GMM군집화가k-평균군집화같은방법보다더적합할수있습니다。여러군집화방법과마찬가지로,GMM군집화를수행하려면모델피팅전에군집개수를지정해야합니다。군집개수에따라gmm의성분개수가지정됩니다。
Gmm을수행할경우다음모범사례를따르십시오。
성분공분산구조를사용해보십시오。대각공분산행렬또는완전공분산행렬을지정할수있고,모든성분이동일한공분산행렬을가지는지여부를지정할수있습니다。
초기조건을지정하십시오。기대값최대화(em)알고리즘은gmm을피팅합니다。k——평균군집화알고리즘에서와같이EM은초기조건에민감하며국소최적해로수렴할수있습니다。모수에대한고유한시작값을지정하거나데이터점에대한초기군집할당을지정하거나이러한값을임의로선택되도록하거나k-평균++알고리즘을사용하도록지정할수있습니다。
정규화를구현하십시오。예를들어,데이터점보다예측변수가더많은경우정규화하여추정안정성을높일수있습니다。
다양한공분산옵션과초기조건을사용하여GMM피팅하기
이예제에서는GMM군집화를수행할때공분산구조에대한다양한옵션과초기조건을지정하면어떠한효과가있는지살펴봅니다。
피셔(费雪)의붓꽃데이터세트를불러옵니다。꽃받침측정값을군집화해보고,꽃받침측정값을사용하여데이터를2차원으로시각화합니다。
负载fisheriris;X = meas(:,1:2);[n,p] = size(X);情节(X (: 1) X (:, 2),“。”,“MarkerSize”15);标题(“Fisher的虹膜数据集”);包含(“萼片长度(厘米)”);ylabel (“萼片宽度(厘米)”);
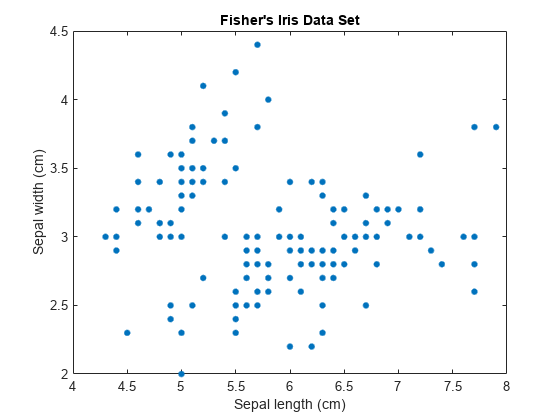
Gmm의성분개수k는부모집단또는군집개수를결정합니다。이그림에서는2개,3개또는더많은가우스성분이적합한지여부를판단하기가어렵습니다。k가가함에따라gmm의복잡도가가합니다。
다양한공분산구조옵션지정하기
각가우스성분에는공분산행렬이있습니다。기하학적으로,공분산구조는군집에그려지는타원체모양을띠는신뢰영역의형태를결정합니다。모든성분에대한공분산행렬이대각공분산행렬인지아니면완전공분산행렬인지를지정할수있고,모든성분에동일한공분산행렬이있는지여부를지정할수있습니다。각각의지정조합에따라타원체의형태와방향이결정됩니다。
3개의GMM성분을지정하고,EM알고리즘의최대반복횟수를1000으로지정합니다。재현이가능하도록난수시드값을설정합니다。
提高(3);K = 3;% GMM组件个数选项= statset(“麦克斯特”, 1000);
공분산구조옵션을지정합니다。
σ = {“对角线”,“全部”};%选择协方差矩阵类型西格玛=数字(西格玛);sharedco方差= {true,false};相同或不相同协方差矩阵的指示器SCtext = {“真正的”,“假”};nSC =数字(sharedco方差);
측정값의극값으로구성된평면을포함하는2차원그리드를생성합니다。이그리드는나중에군집에타원체모양을띠는신뢰역을그릴때사용됩니다。
D = 500;方格长度%x1 = linspace(min(X(:,1))-2, max(X(:,1))+2, d);x2 = linspace(min(X(:,2))-2, max(X(:,2))+2, d);[x1grid,x2grid] = meshgrid(x1,x2);X0 = [x1grid(:) x2grid(:)];
다음과같이지정합니다。
공분산구조옵션으로가능한모든조합에대해3개의성분으로gmm을피팅하십시오。
피팅된gmm을사용하여2차원그리드를군집화하십시오。
각신뢰각신뢰역에대한99%의확률분계점을지정하는점수를구하십시오。이렇게지정된값에따라타원체의주축과보조축의길이가결정됩니다。
군집과유사한색으로각타원체에색을칠하십시오。
阈值=√(chi2inv(0.99,2));Count = 1;为i = 1:nSigma为j = 1:nSC gmfit = fitgmdist(X,k,“CovarianceType”σ{我},...“SharedCovariance”, SharedCovariance {j},“选项”、选择);%装配的GMMclusterX = cluster(gmfit,X);%聚类指数mahalDist = mahal(gmfit,X0);%从每个格点到每个GMM组件的距离在每个GMM组件上绘制椭球并显示聚类结果。次要情节(2,2,数);h1 = gscatter(X(:,1),X(:,2),clusterX);持有在为m = 1:k idx = mahalDist(:,m)<=threshold;颜色= h1(m)。颜色*0.75 - 0.5*(h1(m)。颜色- 1);h2 = plot(X0(idx,1),X0(idx,2),“。”,“颜色”、颜色、“MarkerSize”1);uistack (h2,“底”);结束情节(gmfit.mu (: 1) gmfit.mu (:, 2),“kx”,“线宽”,2,“MarkerSize”10)标题(sprintf ('Sigma is %s\ nsharedco方差= %s'SCtextσ{我},{j}),“字形大小”8)传说(h1, {' 1 ',' 2 ',“3”})举行从Count = Count + 1;结束结束
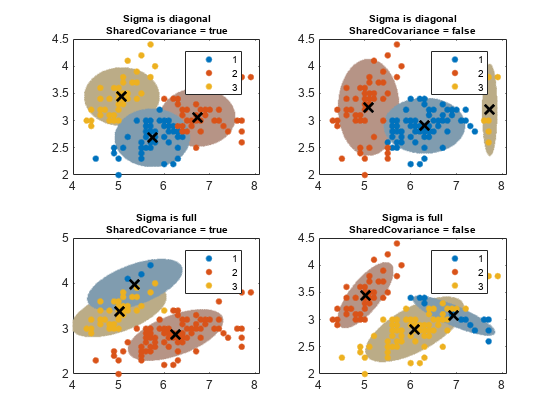
신뢰영역에대한확률분계점은주축과보조축의길이를결정하고,공분산유형은좌표축의방향을결정합니다。공분산행렬옵션과관련해다음사항을유의합니다。
대각공분산행렬은예측변수간에상관관계가없다는것을나타냅니다。타원의주축과보조축은x축과y축에대해평행이거나수직입니다。이렇게지정하면각성분에대해예측변수의개수 만큼모수의총개수가가하지만,완전공분산행렬을지정하는것보다더욱간결합니다。
완전공분산행렬에는x축및y축에대한타원방향의제한없이상관관계가있는예측변수가허용됩니다。각 성분은 만큼모수의총개수를가시키지만예측변수간상관관계구조를포착합니다。이렇게지정될경우과적합이발생할수있습니다。
공유공분산행렬은모든성분이동일한공분산행렬을가진다는것을나타냅니다。모든타원은크기가동일하며동일한방향을갖습니다。이렇게지정될경우오직하나의성분에대한공분산모수의개수만큼모수의총개수가증가하므로비공유행렬을지정하는것보다더욱간결합니다。
비공유공분산행렬은성분이각각고유한공분산행렬을가진다는것을나타냅니다。타원의크기와방향은서로다를수있습니다。이렇게지정되면한성분에대해공분산모수개수의k배만큼모수개수가가하지만성분간공분산차이를포착할수있습니다。
또한,이그림에서는集群가군집순서를유지하지않을수도있음을보여줍니다。여러개의피팅된gmdistribution모델을군집화하는경우集群는유사한성분에다른군집레이블을할당할수있습니다。
다양한초기조건지정하기
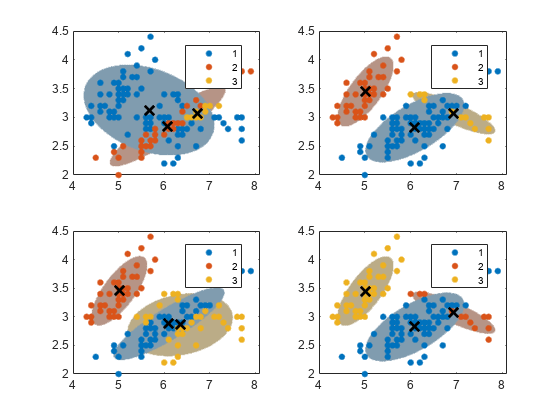
Gmm을데이터에피팅하는알고리즘은초기조건에민감할수있습니다。이러한민감도를살펴보기위해다음과같이서로다른4개의gmm을피팅합니다。
첫번째gmm에서는대부분의데이터점을첫번째군집에할당합니다。
두번째gmm에서는데이터점을임의로군집에할당합니다。
세번째gmm에서는데이터점을군집에임의로한번더할당합니다。
네번째gmm에서는k-평균++를사용하여초기군집중심을구합니다。
initialCond1 = [ones(n-8,1);[2;2;2;2);[3;3;3;3]];%用于第一个GMMinitialCond2 = randsample(1:k,n,true);%用于第二个GMMinitialCond3 = randsample(1:k,n,true);%用于第三个GMMinitialCond4 =“+”;%用于第四个GMMcluster0 = {initialCond1;initialCond2;initialCond3;initialCond4};
모든경우에대해3개성분(k= 3),비공유공분산행렬과완전공분산행렬,동일한초기혼합비율,동일한초기공분산행렬을사용합니다。여러초기값세트를사용할때정성을높이려면em알고리즘반복횟수를늘리십시오。또한,군집에타원체모양을띠는신뢰역을그립니다。
收敛= nan(4,1);为j = 1:4 gmfit = fitgmdist(X,k,“CovarianceType”,“全部”,...“SharedCovariance”假的,“开始”, cluster0 {j},...“选项”、选择);clusterX = cluster(gmfit,X);%聚类指数mahalDist = mahal(gmfit,X0);%从每个格点到每个GMM组件的距离在每个GMM组件上绘制椭球并显示聚类结果。次要情节(2,2,j);h1 = gscatter(X(:,1),X(:,2),clusterX);%从每个格点到每个GMM组件的距离持有在;nK =编号(唯一的(clusterX));为m = 1:nK idx = mahalDist(:,m)<=阈值;颜色= h1(m).颜色*0.75 + -0.5*(h1(m)。颜色- 1);h2 = plot(X0(idx,1),X0(idx,2),“。”,“颜色”、颜色、“MarkerSize”1);uistack (h2,“底”);结束情节(gmfit.mu (: 1) gmfit.mu (:, 2),“kx”,“线宽”,2,“MarkerSize”10)传说(h1, {' 1 ',' 2 ',“3”});持有从收敛(j) = gmfit.收敛;收敛指标结束
总和(聚合)
Ans = 4
모든알고리즘이수렴되었습니다。데이터점에대해각각다르게할당된시작군집조건마다각각다르게피팅된군집할당이구현됩니다。이름-값쌍의通讯录수复制에양의정수를지정할수있으며,여기에지정된횟수만큼알고리즘이실행됩니다。그러면,fitgmdist는가장큰가능도를생성하는피팅을선택합니다。
정규화가필한경우
EM알고리즘반복중에피팅된공분산행렬이종종조건이나쁜상태,즉가능도가무한대가되는상태가될수있습니다。이문제는다음조건중하나이상에해당하는경우발생할수있습니다。
데이터점보다예측변수가더많은경우。
너무많은성분에대해피팅하도록지정한경우。
변수가밀접한상관관계를가질경우。
이러한문제를해결하려면“RegularizationValue”이름-값쌍의通讯录수를사용하여작은양수를지정하십시오。fitgmdist는이값을전체공분산행렬의대각선요소에추가하여모든행렬이양의정부호행렬이되도록합니다。정규화를수행하면최대가능도값을줄일수있습니다。
모델피팅통계량
대부분의경우,성분개수k와적합한공분산구조Σ는알수없습니다。Gmm을조정할수있는한가지방법은정보기준을비교하는것입니다。많이사용되는두가지정보기준은아카이케정보기준(AIC: Akaike信息准则)과베이즈정보기준(BIC:贝叶斯信息准则)입니다。
AIC와BIC모두최적화된음의로그가능도를취한후모델에포함된모수개수로벌점을적용합니다(모델복잡도)。그러나bic가aic에비해더엄격하게복잡도에대해벌점을적용합니다。따라서、AIC는과적합될수있는더복잡한모델을선택하는경향이있고BIC는과소적합될수있는더단순한모델을선택하는경향이있습니다。그러므로모델을평가할때두기준을모두검토하는것이좋습니다。Aic값이나bic값이낮을수록더나은피팅모델임을나타냅니다。또한k에대해선택한값과공분산행렬구조가현재응용사례에적합한지도확해야합니다。fitgmdist는 피팅된gmdistribution모델객체의aic와bic를속성另类投资会议와BIC에저장합니다。점@ @기법을사용하여이러한속성에액세스할수있습니다。적합한모수를선택하는방법을보여주는예제는调整高斯混合模型항목을참조하십시오。
참고 항목
관련 항목
您也可以从以下列表中选择一个网站: