이번역페이지는최신내용을담고있지않습니다。최신내용을문으로보려면여기를클릭하십시오。
fitcsvm
단일클래스및이진분류를위한서포트벡터머신(svm)분류기훈련
구문
설명
fitcsvm은저차원이나중간차원의예측변수데이터세트에대한단일클래스및2 -클래스(이진)분류에대해서포트벡터머신(SVM)모델을훈련시키거나교차검증합니다。fitcsvm은커널함수를사용하여예측변수데이터를매핑하는것을지원하고,순차적최소규모최적화(SMO)반복단일데이터알고리즘(ISDA)도지원하며,목적함수최소화를위한차2계획법을사용하는L1소프트마진(软边缘)최소화를지원합니다。
고차원데이터세트,즉많은예측변수를포함하는데이터세트에대한이진분류를수행할선형SVM모델을훈련시키려면fitclinear를대신사용하십시오。
이진SVM모델을결합하는다중클래스학습에대해서는오류수정출력코드(ECOC)를사용하십시오。자세한내용은fitcecoc를참조하십시오。
支持向量机회귀모델을훈련시키려면저차원및중간차원의예측변수데이터세트의경우fitrsvm을참조하고고차원데이터세트의경우fitrlinear를참조하십시오。
Mdl= fitcsvm (资源描述,ResponseVarName)资源描述에포함된@ @본데이터를사용하여훈련된서포트벡터머신(svm)분류기Mdl을반환합니다。ResponseVarName은资源描述에서단일클래스또는2 -클래스분류에대한클래스레이블을포함하는변수의이름입니다。
예제
支持向量机분류기훈련시키기
피셔(费雪)의붓꽃데이터세트를불러옵니다。꽃받침길이와너비,그리고관측된모든부채붓꽃(濑濑虹膜)을제거합니다。
负载fisheririsInds = ~strcmp(种,“setosa”);X = meas(inds,3:4);Y = species(inds);
처리된데이터세트를사용하여支持向量机분류기를훈련시킵니다。
svm模型= fitcsvm(X,y)
SVMModel = ClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'versicolor' 'virginica'} ScoreTransform: 'none' NumObservations: 100 Alpha: [24x1 double] Bias: -14.4149 KernelParameters: [1x1 struct] BoxConstraints: [100x1 double] ConvergenceInfo: [1x1 struct] Is万博1manbetxSupportVector: [100x1 logical] Solver: 'SMO' Properties, Methods
SVMModel은 훈련된ClassificationSVM분류기입니다。SVMModel의속성을@ @시합니다。예를들어,클래스순서를확하려면점기법을사용하십시오。
classOrder = SVMModel。一会
classOrder =2 x1细胞{'versicolor'} {'virginica'}
첫번째클래스(“多色的”)는음성클래스이고,두번째클래스(“virginica”)는양성클래스입니다。“类名”이름-값쌍의通讯录수를사용하여훈련중에클래스순서를변경할수있습니다。
데이터의산점도도식을플로팅하고서포트벡터를원으로@ @시합니다。
sv = SVMModel.万博1manbetxSupportVectors;图gscatter(X(:,1),X(:,2),y)保持在情节(sv (: 1), sv (:, 2),“柯”,“MarkerSize”10)传说(“多色的”,“virginica”,“万博1manbetx支持向量”)举行从

서포트벡터는추정된클래스경계또는그너머에있는관측값입니다。
“BoxConstraint”이름——값쌍의인수를사용하여훈련중에상자제약조건을설정하여경계(즉,서포트벡터개수)를조정할수있습니다。
支持向量机분류기를훈련시키고교차검하기
电离层데이터세트를불러옵니다。
负载电离层rng (1);%用于再现性
방사기저커널을사용하여支持向量机분류기를훈련시킵니다。소프트웨어가커널함수의스케일값을구하도록합니다。예측변수를@ @준화합니다。
SVMModel = fitcsvm(X,Y,“标准化”,真的,“KernelFunction”,“RBF”,...“KernelScale”,“汽车”);
SVMModel은 훈련된ClassificationSVM분류기입니다。
支持向量机분류기를교차검합니다。기본적으로,소프트웨어는10겹교차검을사용합니다。
CVSVMModel = crossval(SVMModel);
CVSVMModel은ClassificationPartitionedModel교차검된분류기입니다。
본외오분류율을추정합니다。
classLoss = kfoldLoss(CVSVMModel)
classLoss = 0.0484
일반화율은약5%입니다。
支持向量机과단일클래스학습을사용하여이상값감지하기
모든붓꽃을동일한클래스에할당하여피셔(费舍尔)의붓꽃데이터세트를수정합니다。수정된데이터세트에서이상값을감지하고관측값중이상값비율이예상대로인지확인합니다。
피셔(费雪)의붓꽃데이터세트를불러옵니다。꽃잎길이와너비를제거합니다。모든붓꽃을같은클래스에서온것으로처리합니다。
负载fisheririsX = meas(:,1:2);y = ones(size(X,1),1);
수정된데이터세트를사용하여支持向量机분류기를훈련시킵니다。관측값의5%가이상값이라고가정합니다。예측변수를@ @준화합니다。
rng (1);SVMModel = fitcsvm(X,y,“KernelScale”,“汽车”,“标准化”,真的,...“OutlierFraction”, 0.05);
SVMModel은 훈련된ClassificationSVM분류기입니다。기본적으로,소프트웨어는단일클래스학습에가우스커널을사용합니다。
관측값과결정경계를플로팅합니다。서포트벡터와잠재적이상값에플래그를지정합니다。
svInd = SVMModel.Is万博1manbetxSupportVector;H = 0.02;%网格步长[X1,X2] = meshgrid(min(X(:,1)):h:max(X(:,1)),,...min (X (:, 2)): h:马克斯(X (:, 2)));[~,score] = predict(SVMModel,[X1(:),X2(:)]);scoreGrid =重塑(分数,大小(X1,1),大小(X2,2));图绘制(X (: 1), (:, 2),“k”。)举行在情节(X (svInd, 1), X (svInd, 2),“罗”,“MarkerSize”,10)轮廓(X1,X2,scoreGrid)色条;标题(“{\bf基于一类支持向量机的虹膜离群值检测}”)包含(“萼片长度(厘米)”) ylabel (“萼片宽度(厘米)”)传说(“观察”,“万博1manbetx支持向量”)举行从
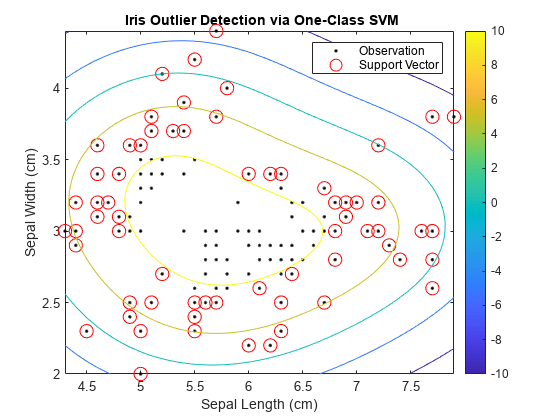
이상값을나머지데이터와분리하는경계는등고선값이0위치에서나타납니다。
교차검된데이터에서음의점수를갖는관측값의비율이5%에가까운지확합니다。
CVSVMModel = crossval(SVMModel);[~,scorePred] = kfoldPredict(CVSVMModel);outlierRate = mean(scorePred<0)
outlierRate = 0.0467
이진svm을사용하여여러클래스경계찾기
fisheriris데이터세트에대한산점도플롯을생성합니다。플롯내그리드좌표를데이터세트분포의새관측값으로처리하고데이터세트의좌표값을세클래스중하나에할당하여클래스경계를찾습니다。
피셔(费雪)의붓꽃데이터세트를불러옵니다。꽃잎길이와너비를예측변수로사용합니다。
负载fisheririsX = meas(:,3:4);Y =物种;
데이터에대한산점도플롯을검토합니다。
图gscatter (X (: 1), (:, 2), Y);H = gca;Lims = [h;XLim h.YLim];提取x轴和y轴限制标题(“{\bf虹膜测量散点图}”);包含(“花瓣长度(厘米)”);ylabel (“花瓣宽度(厘米)”);传奇(“位置”,“西北”);
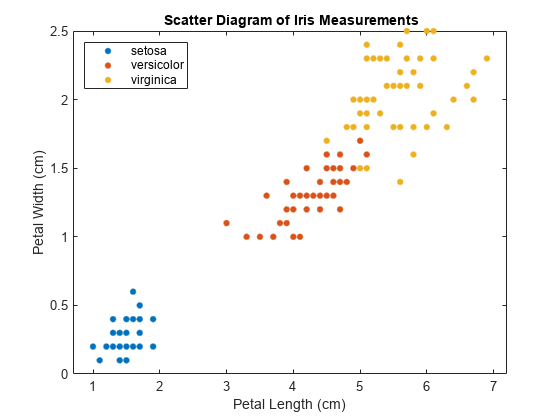
데이터에는세개의클래스가있는데,이중한클래스는나머지두클래스로부터선형분리될수있습니다。
각클래스에대해다음작업을수행합니다。
관측값이그클래스의멤버marketing지여부를나타내는논리형벡터(
indx)를생성합니다。예측변수데이터와
indx를사용하여支持向量机분류기를훈련시킵니다。셀형배열의셀로분류기를저장합니다。
클래스순서를정의합니다。
svm模型= cell(3,1);类=唯一的(Y);rng (1);%用于再现性为j = 1: number (classes) index = strcmp(Y,classes(j));为每个分类器创建二进制类SVMModels{j} = fitcsvm(X,indx,“类名”(虚假的真实),“标准化”,真的,...“KernelFunction”,“rbf”,“BoxConstraint”1);结束
SVMModels는 각 셀이ClassificationSVM분류기를포함하는3×1셀형배열입니다。각셀에대해양성클래스는각각setosa,杂色的,virginica입니다。
플롯내에조밀한그리드를정의하고,좌표를훈련데이터의분포에서새관측값으로처리합니다。각분류기를사용하여새관측값의점수를추정합니다。
D = 0.02;[x1Grid, x2Grid] = meshgrid (min (X (: 1)): d:马克斯(X (: 1))...min (X (:, 2)): d:马克斯(X (:, 2)));xGrid = [x1Grid(:),x2Grid(:)];N = size(xGrid,1);分数=零(N,数字(类));为j = 1: number (classes) [~,score] = predict(SVMModels{j},xGrid);分数(:,j) =分数(:,2);第二列包含积极的班级分数结束
分数의각행에는3개의점수가있습니다。최대점수를갖는요소의인덱스는새클래스관측값이속할가능성이가장높은클래스의인덱스입니다。
각각의새관측값을최대점수를내는분류기와연결합니다。
[~,maxScore] = max(Scores,[],2);
대응되는새관측값이속하는클래스를기준으로플롯의역을색으로구분합니다。
图h(1:3) = gscatter(xGrid(:,1),xGrid(:,2),maxScore,...[0.1 0.5 0.5;0.5 0.1 0.5;0.5 0.5 0.1]);持有在h(4:6) = gscatter(X(:,1),X(:,2),Y);标题(“{\bf虹膜分类区域}”);包含(“花瓣长度(厘米)”);ylabel (“花瓣宽度(厘米)”);传奇(h, {“setosa地区”,“杂色的地区”,“virginica地区”,...“观察setosa”,的观察到的多色的,“观察virginica”},...“位置”,“西北”);轴紧持有从

支持向量机분류기최적화하기
fitcsvm을사용하여하이퍼파라미터를자동으로최적화합니다。
电离层데이터세트를불러옵니다。
负载电离层
자동하이퍼파라미터최적화를사용하여5겹교차검증손실을최소화하는하이퍼파라미터를구합니다。재현이가능하도록난수시드값을설정하고“expected-improvement-plus”수집함수를사용합니다。
rng默认的Mdl = fitcsvm(X,Y,“OptimizeHyperparameters”,“汽车”,...“HyperparameterOptimizationOptions”结构(“AcquisitionFunctionName”,...“expected-improvement-plus”))
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| |运行时| | (estim(观察) .) | | | |=====================================================================================================| | 最好1 | | 0.21652 | 17.039 | 0.21652 | 0.21652 | 64.836 | 0.0015729 |
| 2 |接受| 0.35897 | 0.07617 | 0.21652 | 0.22539 | 0.036335 | 5.5755 |
| 3 |最佳| 0.13105 | 6.632 | 0.13105 | 0.14152 | 0.0022147 | 0.0023957 |
| 4 |接受| 0.35897 | 0.074778 | 0.13105 | 0.13108 | 5.1259 | 98.62 |
| 5 |接受| 0.1339 | 13.599 | 0.13105 | 0.13111 | 0.0011599 | 0.0010098 |
| 6 |接受| 0.13105 | 3.171 | 0.13105 | 0.13106 | 0.0010151 | 0.0045756 |
| 7 |最佳| 0.12821 | 8.4294 | 0.12821 | 0.12819 | 0.0010563 | 0.0022307 |
| 8 |接受| 0.1339 | 10.901 | 0.12821 | 0.13013 | 0.0010113 | 0.0026572 |
| 9 |接受| 0.12821 | 6.1095 | 0.12821 | 0.12976 | 0.0010934 | 0.0022461 |
| 10 |接受| 0.12821 | 3.646 | 0.12821 | 0.12933 | 0.0010315 | 0.0023551 |
| 11 |接受| 0.1396 | 16.231 | 0.12821 | 0.12954 | 994.04 | 0.20756 |
| 12 |接受| 0.13105 | 15.216 | 0.12821 | 0.12945 | 20.145 | 0.044584 |
| 13 |接受| 0.21368 | 17.538 | 0.12821 | 0.12787 | 903.79 | 0.056122 |
| 14 |接受| 0.1339 | 0.25382 | 0.12821 | 0.12939 | 0.018688 | 0.038639 |
| 15 |接受| 0.12821 | 2.712 | 0.12821 | 0.1295 | 5.6464 | 0.15938 |
| 16 |接受| 0.13675 | 9.392 | 0.12821 | 0.12798 | 0.5485 | 0.020716 |
| 17 |接受| 0.12821 | 6.1911 | 0.12821 | 0.12955 | 1.2899 | 0.063233 |
| 18 |接受| 0.1339 | 9.0842 | 0.12821 | 0.12957 | 869.51 | 0.94889 |
| 19 |接受| 0.13675 | 9.2152 | 0.12821 | 0.12957 | 112.89 | 0.31231 |
| 20 |接受| 0.13105 | 0.09432 | 0.12821 | 0.12958 | 0.0010803 | 0.03695 |
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| |运行时| | (estim(观察) .) | | | |=====================================================================================================| | 21日|接受| 0.13675 | 9.1747 | 0.12821 | 0.1299 | 7.7299 | 0.076169 |
| 22 |最佳| 0.12536 | 0.14985 | 0.12536 | 0.13007 | 0.0010485 | 0.013248 |
| 23 |接受| 0.20228 | 16.954 | 0.12536 | 0.12548 | 0.060212 | 0.0010323 |
| 24 |接受| 0.1339 | 0.21183 | 0.12536 | 0.12556 | 0.30698 | 0.16097 |
| 25 |接受| 0.1339 | 14.522 | 0.12536 | 0.12923 | 963.05 | 0.5183 |
| 26 |接受| 0.13675 | 0.24834 | 0.12536 | 0.12888 | 0.0039748 | 0.015475 |
| 27 |接受| 0.1339 | 1.4307 | 0.12536 | 0.12889 | 0.33582 | 0.066787 |
| 28 |接受| 0.1339 | 14.534 | 0.12536 | 0.12884 | 4.2069 | 0.032774 |
| 29 |最佳| 0.12536 | 0.11308 | 0.12536 | 0.12658 | 0.0010233 | 0.017839 |
| 30 |接受| 0.12536 | 0.12514 | 0.12536 | 0.12579 | 0.0010316 | 0.019592 |
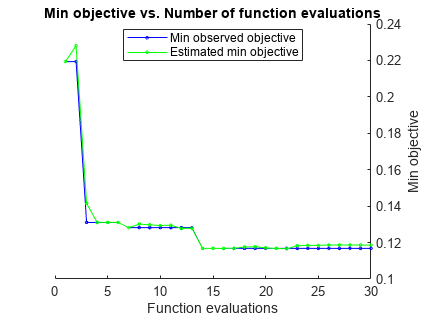
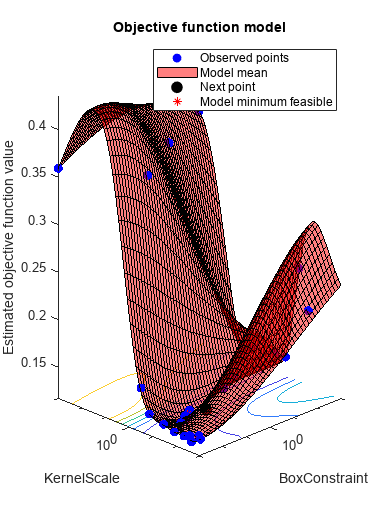
__________________________________________________________ 优化完成。最大目标达到30个。总函数计算:30总运行时间:234.177秒。总目标函数评估时间:213.0698最佳观测可行点:BoxConstraint KernelScale _____________ ___________ 0.0010233 0.017839观测目标函数值= 0.12536估计目标函数值= 0.12579函数评估时间= 0.11308最佳估计可行点(根据模型):BoxConstraint KernelScale _____________ ___________ 0.0010233 0.017839估计目标函数值= 0.12579估计函数评估时间= 0.13623
Mdl = ClassificationSVM ResponseName: 'Y' CategoricalPredictors: [] ClassNames: {'b' 'g'} ScoreTransform: 'none' NumObservations: 351 HyperparameterOptimizationResults: [1×1 BayesianOptimization] Alpha: [91×1 double] Bias: -5.6976 KernelParameters: [1×1 struct] BoxConstraints: [351×1 double] ConvergenceInfo: [1×1 struct] Is万博1manbetxSupportVector: [351×1 logical] Solver: 'SMO' Properties, Methods
입력marketing수
출력marketing수
제한 사항
fitcsvm은단일클래스학습응용사례와2 -클래스학습응용사례에대해SVM분류기를훈련시킵니다。세개이상의클래스를갖는데이터를사용하여支持向量机분류기를훈련시키려면fitcecoc를사용하십시오。fitcsvm은저차원및중간차원의데이터세트를지원합니다。고차원데이터세트에대해서는fitclinear를대신사용하십시오。
세부 정보
팁
데이터세트가크지않다면항상예측변수를指导书준화하도록하십시오(
标准化참조)。@ @ @ @ @ @ @ @。KFold이름-값쌍의수를사용하여교차검을수행하는것이좋습니다。교차검결과를통해SVM분류기가얼마나잘일반화되는지확할수있습니다。단일클래스학습의경우:
서포트벡터의희소성은SVM분류기에있어서는이상적속성입니다。서포트벡터의개수를줄이려면
BoxConstraint를큰값으로설정하십시오。단,이동작을수행하면훈련시간이가합니다。최적의훈련시간을위해
CacheSize를컴퓨터의메모리제한이허용하는한최대한높게설정하십시오。훈련세트에서서포트벡터의개수가관측값보다훨씬적을거라예상되는경우,이름——값쌍의인수
“ShrinkagePeriod”를사용하여활성세트를축소함으로써수렴되는속도를상당히높일수있습니다。“ShrinkagePeriod”,1000年을지정하는것이좋습니다。결정경계에서멀리떨어진중복된관측값은수렴에향을미치지않습니다。그러나,결정경계가까이에있는중복된관측값은몇개만있더라도수렴되는속도가상당히느려질수있습니다。다음과같은경우
“RemoveDuplicates”,真的를지정하여수렴되는속도를높이십시오。데이터세트에중복된관측값이많이있는경우。
몇개의중복된관측값이결정경계가까이에있다고의심되는경우。
훈련중에원래데이터세트를유지하기위해
fitcsvm은원래데이터세트와중복된관측값을제거한두개의데이터세트를일시적으로별도로저장해야합니다。따라서,몇몇중복된관측값을포함하는데이터세트에대해真正的를지정할경우fitcsvm은원래데이터메모리의두배에가까운메모리를사용합니다。모델을훈련시킨후에는새데이터에대한레이블을예측하는C / c++코드를생성할수있습니다。C/ c++코드를생성하려면MATLAB编码器™가필합니다。자세한내용은代码生成简介항목을참조하십시오。
알고리즘
支持向量机이진분류알고리즘의수학적공식은이진분류를위한서포트벡터머신항목과서포트벡터머신이해하기항목을참조하십시오。
南,<定义>,빈문자형벡터(”),빈字符串형(""),< >失踪값은결측값을나타냅니다。fitcsvm은결측응답변수에대응되는데이터의전체행을제거합니다。총가중치를계산할때(다음글머리기호항목참조),fitcsvm은최소한개의결측예측변수를갖는관측값에대응되는가중치를모두무시합니다。이동작은균형클래스문제에서불균형사전확률을초래할수있습니다。따라서,관측값상자제약조건은BoxConstraint와일치하지않을수있습니다。fitcsvm은가중치또는사전확률이0 rm관측값을제거합니다。2-클래스학습의경우,비용행렬 (
成本참조)를지정하면소프트웨어가 에설명되어있는벌점을적용하는방식으로클래스사전확률p(之前참조)를pc로업데이트합니다。구체적으로,
fitcsvm은다음단계를완료합니다。를계산합니다。
업데이트된사전확률의합이1이되도록pc*를정규화합니다。
K는클래스개수입니다。
비용행렬을다음과같이디폴트값으로재설정합니다。
훈련데이터에서사전확률이0 rm클래스에대응되는관측값을제거합니다。
2-클래스학습의경우,
fitcsvm은모든관측값가중치(权重참조)의합이1이되도록정규화합니다。그런다음,정규화된가중치를합이관측값이속하는클래스의업데이트된사전확률이되도록다시정규화합니다。즉,k클래스의관측값j에대한총가중치는다음과같습니다。wj는관측값j에대한정규화된가중치이고,pc k는k클래스의업데이트된사전확률입니다(앞에나와있는글머리기호항목참조)。
2-클래스학습의경우,
fitcsvm은상자제약조건을훈련데이터의각관측값에할당합니다。관측값j의상자제약조건에대한공식은다음과같습니다。n은훈련` ` ` `본크기이고0은초기상자제약조건이며(
“BoxConstraint”이름-값쌍의수참조), 는관측값j의총가중치입니다(앞에나와있는글머리기호목록참조)。“标准化”,真的를설정하고“成本”,“之前”또는“重量”이름-값쌍의通讯录수를설정하면fitcsvm이대응되는가중평균과가중` ` `준편차를사용하여예측변수를` ` ` `준화합니다。즉,fitcsvm은다음을사용하여예측변수j(xj)를@준화합니다。xjk는예측변수j(열)의관측값k(행)입니다。
p가훈련데이터에서사용자가예상하는이상값비율이고OutlierFraction, p를설정한다고가정합니다。단일클래스학습의경우,소프트웨어가훈련데이터에포함된관측값의100
p가음의점수를가지도록편향항을훈련시킵니다。2-클래스학습의경우소프트웨어가로버스트학습을구현합니다。다시말해,최적화알고리즘이수렴될때소프트웨어가관측값의100
p를제거한다는의미입니다。제거되는관측값은크기가큰기울기에해당합니다。
예측변수데이터에범주형변수가포함된경우소프트웨어가일반적으로이러한변수에대해전체가변수인코딩을사용합니다。소프트웨어는각범주형변수의각수준마다하나의가변수를생성합니다。
PredictorNames속성은원래예측변수이름마다하나의소를저장합니다。예를들어,세개의예측변수가있고,그중하나가세개수준을갖는범주형변수라고가정해보겠습니다。그러면PredictorNames는예측변수의원래이름을포함하는문자형벡터로구성된1×3셀형배열이됩니다。ExpandedPredictorNames속성은가변수를포함하여예측변수마다하나의소를저장합니다。예를들어,세개의예측변수가있고,그중하나가세개수준을갖는범주형변수라고가정해보겠습니다。그러면ExpandedPredictorNames는예측변수이름및새가변수의이름을포함하는문자형벡터로구성된1×5셀형배열이됩니다。마찬가지로,
β속성은가변수를포함하여예측변수마다하나의베타계수를저장합니다。万博1manbetxSupportVectors속성은가변수를포함하여서포트벡터에대한예측변수값을저장합니다。예를들어,m개의서포트벡터와세개의예측변수가있고,그중하나가세개의수준을갖는범주형변수라고가정해보겠습니다。그러면万博1manbetxSupportVectors는n×5행렬이됩니다。X속성은훈련데이터를원래입력된대로저장하고가변수는포함하지않습니다。입력값이테이블marketing경우,X는예측변수로사용된열만포함합니다。
테이블에지정된예측변수에대해변수중하나가순서가지정된(순서형)범주를포함하는경우소프트웨어는이러한변수에대해순서형인코딩(顺序编码)을사용합니다。
순서가지정된k개의수준을갖는변수에대해소프트웨어는K - 1개의가변수를생성합니다。J번째가변수는수준이J일때까지는1이되고,수준이J + 1과k사이경우+1이됩니다。
ExpandedPredictorNames속성에저장된가변수의이름은값+1을갖는첫번째수준을나타냅니다。소프트웨어는수준2,3,…,k의이름을 포함하여 가변수에 대해K - 1개의추가예측변수이름을저장합니다。
모든솔버는L1소프트마진(Soft-Margin)최소화를구현합니다。
단일클래스학습의경우,소프트웨어는다음을만족하는라그랑주승수α1,…,αn을추정합니다。
참고 문헌
[1]克里斯汀尼,N.和J. C.肖-泰勒。支持向量机和其他基于核的学习方法简介。万博1manbetx英国剑桥:剑桥大学出版社,2000年。
[2]范,r.e。,林志信。陈和c - j。林。“使用二阶信息训练支持向量机的工作集选择。”万博1manbetx机器学习研究,Vol. 6, 2005, pp. 1889-1918。
哈斯蒂、T.、R.蒂布谢拉尼和J.弗里德曼。统计学习的要素,第二版。纽约:施普林格,2008。
[4]凯克曼V. -M。黄和M.沃格特。从庞大数据集训练核心机器的迭代单数据算法:理论和性能。万博1manbetx支持向量机:理论与应用。王立波编辑,255-274。柏林:斯普林格出版社,2005年。
[5]肖科普夫,B. J. C.普拉特,J. C.肖-泰勒,A. J.斯莫拉和R. C.威廉姆森。“估算高维分布的支持度”万博1manbetx神经第一版。,Vol. 13, Number 7, 2001, pp. 1443–1471.
[6]肖科普夫,B.和A.斯莫拉。核学习:支持向量机,正则化,优化及超越,自适应万博1manbetx计算和机器学习。马萨诸塞州剑桥:麻省理工学院出版社,2002年。
확장 기능
참고 항목
ClassificationPartitionedModel|ClassificationSVM|CompactClassificationSVM|fitcecoc|fitclinear|fitSVMPosterior|预测|rng|quadprog(优化工具箱)
您也可以从以下列表中选择一个网站:
