合适的定制单变量分布
这个例子展示了如何使用统计和机器学习工具箱™函数大中型企业适合定制单变量数据的分布。
使用大中型企业,你可以计算极大似然参数估计和估计精度,对许多种类的分布之外的工具箱提供了具体的拟合函数。
要做到这一点,您需要定义分配使用一个或多个功能。在最简单的情况下,您可以编写代码来计算分布的概率密度函数(PDF),你想要健康,和大中型企业会为你做剩下的大部分工作。这个例子中涵盖了这些情况。在审查数据的问题,您必须编写代码来计算累积分布函数(CDF)或生存函数(SF)。在其他一些问题,这可能有利于定义对数似函数(灌)本身。这个例子中,的第二部分合适的定制单变量分布,第2部分,涵盖了这两个病例。
安装自定义分布:Zero-Truncated泊松的例子
计数数据通常使用泊松分布模型,你可以使用统计和机器学习的工具箱函数poissfit适合一个泊松模型。然而,在某些情况下,计数为零不被记载在数据,所以拟合泊松分布并不简单,因为这些“零缺失”。这个示例将展示如何符合泊松分布zero-truncated数据,使用函数大中型企业。
对于这个示例,我们将使用模拟数据从zero-truncated泊松分布。首先,我们生成一些随机泊松数据。
rng (18,“旋风”);n = 75;λ= 1.75;x = poissrnd(λ,n, 1);
接下来,我们把所有的零从模拟的数据截断。
x = x (x > 0);长度(x)
ans = 65
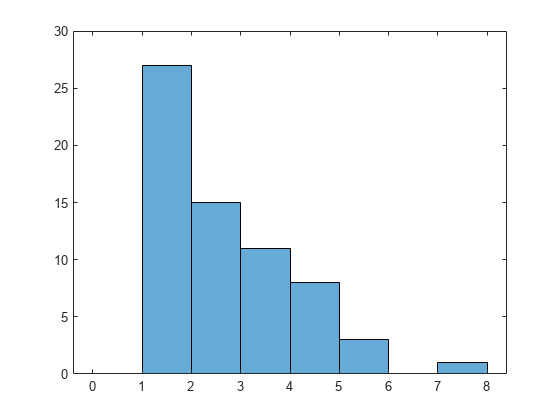
这里有一个这些模拟数据的柱状图。注意,数据看起来像一个泊松分布合理,除了没有零。我们将配合他们一个泊松分布是相同的正整数,但这没有概率为零。通过这种方式,我们可以估算出泊松参数λ,占“零缺失”。
嘘(x,[0:1:马克斯(x) + 1]);
第一步是定义zero-truncated泊松分布的概率函数(PF)。我们将创建一个函数来计算每个点的概率x,给定一个值为泊松分布的参数λ的意思。的PF zero-truncated泊松只是通常的泊松PF,重整,总结。零截断,重正化只是1-Pr {0}。最简单的方法创建一个函数的PF是使用一个匿名函数。
pf_truncpoiss = @ (x,λ)poisspdf (x,λ)。/ (1-poisscdf(0,λ));
为简单起见,我们假设所有的x值给这个函数将正整数,没有检查。错误检查,或更复杂的分布,可能会需要超过一行代码,这一部分的功能应该在一个单独的文件中定义。
下一步是提供一个合理的粗糙的第一个猜测参数λ。在本例中,我们将使用示例的意思。
开始=意味着(x)
开始= 2.2154
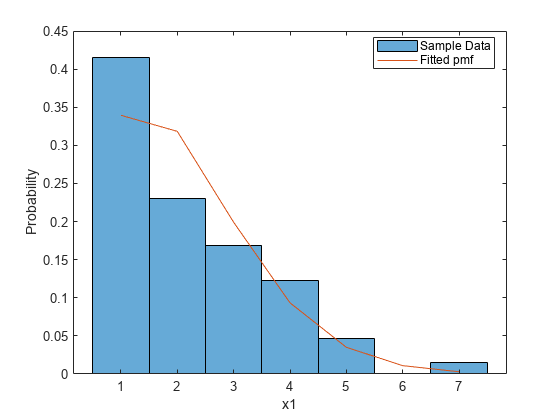
我们提供大中型企业与数据,和匿名函数,使用pdf格式的参数。(泊松是离散的,所以这是一个概率函数,而不是一个PDF)。由于泊松分布的均值参数必须是积极的,我们也为λ指定一个下界。大中型企业返回λ的最大似然估计,可选地,近似95%置信区间参数。
[lambdaHat, lambdaCI] =大中型企业(x,“pdf”pf_truncpoiss,“开始”开始,“低”,0)
lambdaHat = 1.8760
lambdaCI =2×11.4990 - 2.2530
注意,参数估计小于样本均值。就像它应该,因为最大似然估计占失踪的零数据中不存在。
我们也可以计算一个标准误差估计λ,使用返回的大样本方差近似mlecov。
阿瓦尔人= mlecov (lambdaHat x,“pdf”,pf_truncpoiss);stderr =√阿瓦尔人
stderr = 0.1923
提供额外的值分布函数:一个截断正常的例子
它有时也会发生连续的数据截断。例如,观察比某些固定值可能不会记录,因为限制的方式收集数据。这个示例将展示如何截断数据符合正态分布,使用函数大中型企业。
对于本例,我们模拟的数据截断正态分布。首先,我们生成一些随机的正常数据。
n = 75;μ= 1;σ= 3;x = normrnd(μ、σ,n, 1);
接下来,我们删除任何观察,除了截断点,xTrunc。在这个例子中,我们假设xTrunc是已知的,并且不需要估计。
xTrunc = 4;x = x (x < xTrunc);长度(x)
ans = 64
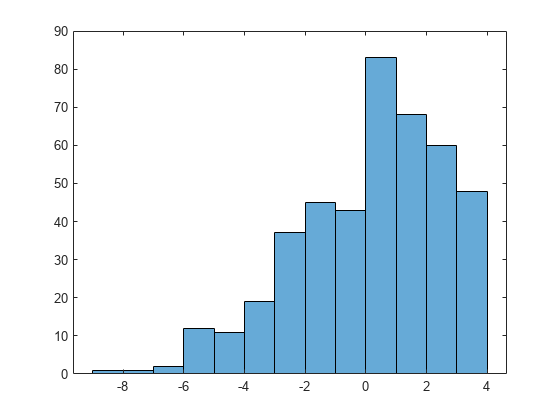
这里有一个这些模拟数据的柱状图。我们将配合他们的分布是相同的正常x < xTrunc,但概率为零xTrunc之上。通过这种方式,我们可以评估正常参数μ、σ虽然占“失踪的尾巴”。
嘘(x, (-10: .5:4));
与前面的示例中,我们将定义截断正态分布的PDF,并创建一个函数来计算每个点的概率密度x,给定的参数μ、σ的值。截断点固定和已知的PDF截断正常只是平时正常的PDF,截断,然后重整,集成了一个。重正化就是在xTrunc CDF实验组的评估。为简单起见,我们假设所有x值小于xTrunc,没有检查。我们将使用一个匿名函数定义PDF。
pdf_truncnorm = @ (x,μ、σ)normpdf (x,μ、σ)。/ normcdf (xTrunc、μ、σ);
xTrunc截断点,没有被估计的,因此它并不在PDF的分布参数函数的输入参数列表。xTrunc也不是数据向量输入参数的一部分。一个匿名函数,我们可以简单地引用变量xTrunc已经在工作区中定义,而不需要担心通过作为一个额外的参数。
我们还需要提供一个粗略的开始猜的参数估计。在这种情况下,由于截断不要太极端,样本均值和标准偏差可能会工作得很好。
开始= [(x),性病(x))
开始=1×20.2735 - 2.2660
我们提供大中型企业与数据,和匿名函数,使用pdf格式的参数。还因为σ必须是积极的,我们指定低参数范围。大中型企业返回μ、σ的最大似然估计为一个向量,以及一个矩阵近似95%置信区间的两个参数。
[paramEsts, paramCIs] =大中型企业(x,“pdf”pdf_truncnorm,“开始”开始,“低”(从0))
paramEsts =1×20.9911 - 2.7800
paramCIs =2×2-0.1605 1.9680 2.1427 3.5921
注意,μ、σ的估计是不少大于样本均值和标准偏差。这是因为模型适合占了“失踪”的上尾分布。
我们可以计算一个近似参数估计使用的协方差矩阵mlecov。在大样本近似通常是合理的,可以近似估计的标准误差对角线的根元素。
acov = mlecov (paramEsts x,“pdf”pdf_truncnorm)
acov =2×20.3452 0.1660 0.1660 0.1717
stderr =√诊断接头(acov))
stderr =2×10.5876 - 0.4143
安装一个更复杂的地理分布:两个法线的混合物
一些数据集展览双峰性、甚至多峰性和拟合标准分发给这些数据通常是不合适的。然而,简单的单峰分布往往模型的混合这些数据很好。事实上,它甚至有可能给出一个解释,每个组件的混合物的来源,根据特定于应用程序的知识。
在这个例子中,我们将配合两个正态分布的混合模拟数据。这种混合物可能与下面的建设性的定义描述生成一个随机的值:
首先,抛硬币有偏见。如果土地的头,随机选择一个值从一个正态分布意味着mu_1和标准差sigma_1。如果硬币土地反面,随机选择一个值从一个正态分布意味着mu_2和标准差sigma_2。
对于这个示例,我们将从学生的t分布的混合生成数据,而不是使用相同的模型拟合。这是那种你会在蒙特卡罗模拟测试是多么健壮的拟合方法偏离模型的假设是合适的。在这里,然而,我们将配合一个模拟数据集。
1 x = [trnd(20日,50)trnd (1100) + 3];嘘(x, -2.25: .5:7.25);
与前面的示例中,我们将定义模型适合通过创建一个函数,计算概率密度。PDF的混合物两法线只是一个加权和的PDF两个正常组件,加权的混合概率。这个PDF创建使用一个匿名函数非常简单。函数需要6输入:一个向量的数据评估PDF,和分布的五个参数。每个组件都有参数的平均值和标准偏差;混合概率使共有五个。
pdf_normmixture = @ (x p、mu1 mu2, sigma1, sigma2)…p * normpdf (x, mu1 sigma1) + (1 - p) * normpdf (x, mu2 sigma2);
我们还需要一个初始猜测参数。越是参数模型,一个合理的起点很重要。对于本例,我们将从一个平等的混合物开始法线(p = 0.5),集中在两个四分位数的数据,以同样的标准偏差。的起始值标准差的公式来自混合的方差的均值和方差的每个组件。
pStart = 5;muStart =分位数(x, [。25。)
muStart =1×20.5970 - 3.2456
sigmaStart =√var (x) - 0。25 * diff (muStart) ^ 2)
sigmaStart = 1.2153
开始= [pStart muStart sigmaStart sigmaStart];
最后,我们需要指定范围0和1的混合概率,标准差和下界为零。其余边界向量的元素设置为+正或负无穷,表示没有限制。
磅=[0负负0 0];乌兰巴托=[1正正正正);paramEsts大中型企业的(x) =“pdf”pdf_normmixture,“开始”开始,…“低”磅,“上”乌兰巴托)
警告:最大似然估计不收敛。迭代超过限制。
paramEsts =1×50.3523 0.0257 3.0489 1.0546 1.0629
默认为自定义分布是200迭代。
statset (“mlecustom”)
ans =结构体字段:显示:‘离开’MaxFunEvals: 400麦克斯特:200 TolBnd: 1.0000 e-06 TolFun: 1.0000 e-06 TolTypeFun: [] TolX: 1.0000 e-06 TolTypeX: [] GradObj:“关闭”雅可比矩阵:[]DerivStep: 6.0555 e-06 FunValCheck:”“健壮:[]RobustWgtFun: [] WgtFun:[]的调子:[]UseParallel: [] UseSubstreams:[]流:{}OutputFcn: []
覆盖默认情况下,使用结构创建一个选项statset函数。也增加了功能评价极限。
选择= statset (“麦克斯特”,300,“MaxFunEvals”,600);paramEsts大中型企业的(x) =“pdf”pdf_normmixture,“开始”开始,…“低”磅,“上”乌兰巴托,“选项”选项)
paramEsts =1×50.3523 0.0257 3.0489 1.0546 1.0629
看来最后的迭代收敛只有在过去几位数的重要结果。尽管如此,它总是一个好主意,以确保收敛。
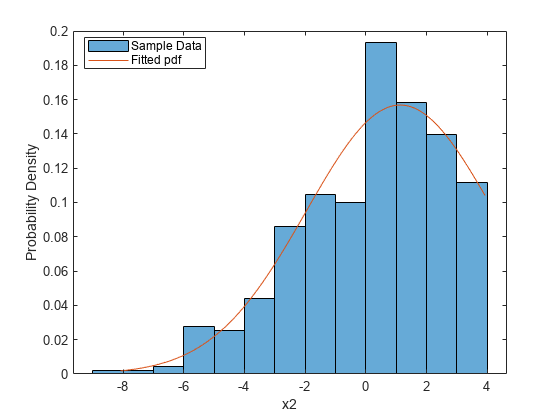
最后,我们可以画出拟合密度对概率直方图的原始数据,检查视力。
垃圾箱= -2.5:.5:7.5;h =酒吧(垃圾箱,histc (x,垃圾箱)/(长度(x) * 5),“histc”);h。FaceColor = [。9。9。9);xgrid = linspace(1.1 *分钟(x), 1.1 *马克斯(x), 200);pdfgrid = pdf_normmixture (xgrid paramEsts (1) paramEsts (2), paramEsts (3), paramEsts (4), paramEsts (5));持有在情节(xgrid pdfgrid,“- - -”)举行从包含(“x”)ylabel (的概率密度)
使用嵌套函数:一个普通的例子与不平等的精度
有时当数据收集,每个观测了不同精度和可靠性。例如,如果几个实验每个独立测量数相同的数量,但每只报告的平均测量,每个报告的可靠性数据点的数量将取决于原始观测进入它。如果最初的原始数据不可用,估计的分布必须考虑可用的数据,平均,每个人都有不同的差异。这个模型有一个明确的解决方案极大似然参数估计。然而,出于演示的目的,我们将使用大中型企业来估计参数。
假设我们有10个数据点,每一个实际上是平均1到8的观察。这些原始观察并不可用,但我们知道有多少有对每个数据点。我们需要估计原始数据的平均值和标准偏差。
x = [0.25 -1.24 1.38 1.39 -1.43 2.79 3.52 - 0.92 1.44 - 1.26);m = [8 2 1 3 8 4 2 5 2 4);
每个数据点的方差的数量成反比的观察,走进它,所以我们将使用1 / m体重中的每个数据点的方差最大似然。
w = 1 / m
w =1×100.1250 0.5000 1.0000 0.3333 0.1250 0.2500 0.5000 0.2000 0.5000 0.2500
模型中我们合适,我们可以定义分布的PDF,但使用日志PDF是更自然,因为正常的PDF表单
c。* exp (-0.5 * z ^ 2)。
和大中型企业必须采取PDF的日志,计算对数似。所以,我们将创建一个函数,这个函数计算日志直接PDF。
日志PDF函数来计算每个点的概率密度的对数x,给定值μ、σ。它还将需要考虑不同的方差的重量。与前面的示例不同,该分布函数是一个小比一行程序复杂,并且是最明显的写作为一个单独的函数在它自己的文件。因为日志PDF功能需要观察计数作为额外的数据,最直接的方式来完成这个适合使用嵌套的函数。
我们已经创建了一个单独的文件中函数调用wgtnormfit.m。这个函数包含初始化数据,一个嵌套函数加权的日志PDF正常模型,和一个调用大中型企业函数实际上符合模型。因为σ必须是积极的,我们必须指定降低参数范围。调用大中型企业返回μ、σ的最大似然估计在一个向量。
类型wgtnormfit.m
函数paramEsts = wgtnormfit % wgtnormfit加权正态分布拟合的例子。% 1984 - 2012版权MathWorks公司x = [0.25 -1.24 1.38 1.39 -1.43 2.79 3.52 0.92 1.44 1.26) ';m = [8 2 1 3 8 4 2 5 2 4) ';函数呆呆的= logpdf_wn (x,μ、σ)v =σ。^ 2。/ m;呆呆的= - (xμ)。^ 2。/ (2。* v) - 5 . *日志(2。*π。* v);结束paramEsts =大中型企业(x, logpdf, @logpdf_wn,‘开始’,(意思是(x)性病(x)],“低”,[负0]);结束
在wgtnormfit.m,我们通过大中型企业处理嵌套函数logpdf_wn,使用“logpdf”参数。嵌套函数是指观察计数,m,计算的加权日志PDF。因为向量m是母公司中定义的函数,logpdf_wn可以访问它,没有必要担心通过m一个显式的输入参数。
我们需要提供一个粗略的第一个猜想的参数估计。在这种情况下,未加权的样本均值和标准偏差应该好了,这就是wgtnormfit.m用途。
开始= [(x),性病(x))
开始=1×21.0280 - 1.5490
适合的模型,我们拟合函数运行。
paramEsts = wgtnormfit
paramEsts =1×20.6244 - 2.8823
注意,估计的μ小于样本均值的三分之二。就像它应该是:估计是影响大多数的最可靠的数据点,即,是基于最大数量的原始观测数据。在这个数据集,这些点会把从未加权的样本均值估计。
使用一个参数变换:正常的例子(继续)
参数的最大似然估计,置信区间通常是计算正常使用大样本近似估计的分布。这通常是一个合理的假设,但小样本大小,有时有利于提高正常近似改变一个或多个参数。在这个例子中,我们有一个位置参数和尺度参数。规模参数往往转化为他们的日志,在这里我们将这样做与σ。首先,我们将创建一个新的日志PDF功能,然后再计算参数的估计使用。
新的日志PDF函数创建一个嵌套函数中的函数wgtnormfit2.m。在第一个健康,该文件包含数据初始化,一个嵌套函数加权的日志PDF正常模型,和一个调用大中型企业函数实际上符合模型。因为σ可以是任何的积极价值,日志(σ)是无界的,我们不再需要指定低或上界。同时,调用大中型企业在这种情况下返回参数估计和置信区间。
类型wgtnormfit2.m
函数[paramEsts paramCIs] = wgtnormfit2 % wgtnormfit2加权正态分布的拟合例子(日志(σ)参数化)。% 1984 - 2012版权MathWorks公司x = [0.25 -1.24 1.38 1.39 -1.43 2.79 3.52 0.92 1.44 1.26) ';m = [8 2 1 3 8 4 2 5 2 4) ';函数呆呆的= logpdf_wn2 (x,μ,logsigma) v = exp (logsigma)。^ 2。/ m;呆呆的= - (xμ)。^ 2。/ (2。* v) - 5 . *日志(2。*π。* v);结束[paramEsts paramCIs] =大中型企业(x, logpdf, @logpdf_wn2,‘开始’,(意思是(x),日志(std (x))));结束
请注意,wgtnormfit2.m使用相同的起点,转化为新的参数化,即。样本标准差,日志。
开始= [(x),日志(std (x)))
开始=1×21.0280 - 0.4376
[paramEsts, paramCIs] = wgtnormfit2
paramEsts =1×20.6244 - 1.0586
paramCIs =2×2-0.2802 0.6203 1.5290 1.4969
由于参数化使用日志(σ),我们将回到原来的规模估计和置信区间为σ。注意,估计为μ、σ是一样的在第一,因为最大似然估计不变的参数化。
muHat = paramEsts (1)
muHat = 0.6244
sigmaHat = exp (paramEsts (2))
sigmaHat = 2.8823
muCI = paramCIs (: 1)
muCI =2×1-0.2802 - 1.5290
sigmaCI = exp (paramCIs (:, 2))
sigmaCI =2×11.8596 - 4.4677
