fsulaplacian
Rank features for unsupervised learning using Laplacian scores
Description
IDX= fsulaplacian(X)Xusing theLaplacian scores。The function returnsIDX, which contains the indices of features ordered by feature importance. You can useIDX为无监督学习选择重要功能。
Examples
Rank Features by Importance
加载样本数据。
loadionosphere
Rank the features based on importance.
[idx,scores] = fsulaplacian(X);
Create a bar plot of the feature importance scores.
bar(scores(idx)) xlabel(“功能等级”)ylabel(“功能重要性得分”)
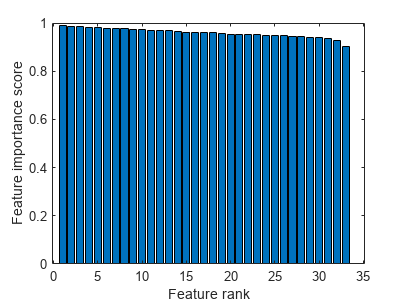
选择the top five most important features. Find the columns of these features inX。
IDX(1:5)
ans =1×515 13 17 21 19
第15列X是个most important feature.
使用指定相似性矩阵的等级功能
计算Fisher的Iris数据集中的相似性矩阵,并使用相似性矩阵对特征进行排名。
Load Fisher's iris data set.
loadfisheriris
Find the distance between each pair of observations inmeasby using thepdist和squareformfunctions with the default Euclidean distance metric.
D = pdist(meas); Z = squareform(D);
Construct the similarity matrix and confirm that it is symmetric.
S = exp(-Z.^2); issymmetric(S)
ans =logical1
排名功能。
idx =fsulaplacian(meas,'Similarity',S)
idx =1×43 4 1 2
Ranking using the similarity matrixS是个same as ranking by specifying'NumNeighbors'as尺寸(MES,1)。
IDX2 = fsulaplacian(meas,'NumNeighbors',尺寸(MES,1))
IDX2 =1×43 4 1 2
Input Arguments
Output Arguments
More About
Algorithms
References
[1] He,X.,D。Cai和P. Niyogi。“特征选择的Laplacian得分。”NIPS Proceedings.2005.
You can also select a web site from the following list:
Americas
- América Latina(Español)
- Canada(English)
- United States(English)
