고차원데이터를분류하기위해특징선택하기
이예제에서는고차원데이터를분류하기위해특징을선택하는방법을보여줍니다。더구체적으로,이예제에서는순차적특징선택을수행하는방법을보여줍니다。이는가장널리사용되는특징선택알고리즘중하나입니다。또한,홀드아웃검증및교차검증을사용하여선택한특징의성능을평가하는방법도보여줍니다。
통계적학습에서는특징개수(차원수)를줄이는것이중。생물정보학데이터처럼특징의수는많고관측값수는한정된데이터세트의경우,일반적으로특징의상당수가원하는학습결과의생성에유용하지않으며한정된관측값으로인해학습알고리즘이잡음에과적합될수있습니다。특징개수를줄이면저장공간과계산시간을절약하고설명력(可理解性)을늘릴수있습니다。
특징개수를줄이는주특징개수를줄이는주。특징선택알고리즘은원래특징집합에서일부특징을선택하며,특징변환방법은원래의고차원특징공간에서축소된차원의새공간으로데이터를변환합니다。
데이터불러오기
혈청단백체패턴진단은질병에걸린환자와질병에걸리지않은환자의관측값을구별하는데사용될수있습니다。프로파일패턴은SELDI(表面增强激光解吸电离)단백질질량분석을사용하여생성됩니다。이들특징은특정질량/전하값에서의이온강도수준을나타냅니다。
이예제에서는WCX2단백질배열을사용하여생성된고해상도난소암데이터세트를사용합니다。生物信息工具箱™原质谱数据预处理(生物信息学工具箱)예제에서설명한것과비슷한전처리과정을거치면이데이터세트는奥林匹克广播服务公司및grp라는두개의변수를가지게됩니다。奥林匹克广播服务公司변수는4000개특징을갖는216개관측값으로구성됩니다。grp의각의각奥林匹克广播服务公司에서대응하는행이속하는그룹을정의합니다。
负载ovariancancer;谁
名称大小字节类属性grp 216x1 25056 cell obs 216x4000 3456000 single
훈련세트와검정세트로데이터나누기
이예제에서사용하는일부함수는matlab®의난수생성함수를호출합니다。이예제가보여주는결과를정확히재현할수있도록아래명령을실행하여난수생성기를알려진상태로설정하십시오。이렇게하지않으면다른결과가나올수있습니다。
rng (8000“旋风”);
훈련데이터에대한성능(재대입성능)은독립적인검정세트에대한모델의성능을추정하기에좋은척도가아닙니다。재대입성능은일반적으로지나치게낙관적입니다。선택한모델의성능을예측하려면모델생성에사용하지않은다른데이터세트로성능을평가해야합니다。여기서는cvpartition을사용하여크기가160,훈련세트와크기가56,검정세트로데이터를나눕니다。훈련세트와검정세트모두그룹비율이grp와거의동일합니다。훈련데이터를사용하여특징을선택하고검정데이터를사용하여선택한특징의성능을판단합니다。이를대개홀드아웃검이라고합니다。모델평가와선택에널리사용되는또다른간단한방법은교차검입니다。이검법은예제의뒷부분에서설명하겠습니다。
holdoutCVP = cvpartition (grp),“坚持”56)
holdoutCVP = holdout交叉验证分区NumObservations: 216 NumTestSets: 1 TrainSize: 160 TestSize: 56
奥林匹克广播服务公司(dataTrain = holdoutCVP.training:);grpTrain = grp (holdoutCVP.training);
모든특징을사용하여데이터를분류할때발생하는문제
특징의수를먼저줄이지않을경우특징의개수가관측값개수보다훨씬더크기때문에이예제에사용된데이터세트에서일부분류알고리즘이실패할수있습니다。이예제에서는분류알고리즘으로2차판별분석(qda)을사용합니다。다음에표시된것처럼모든특징을사용하여데이터에QDA를적용할경우공분산행렬을추정하기에충분한표본이각그룹에없으므로오류가발생합니다。
试一试yhat = category (obs(test(holdoutCVP),:), dataTrain, grpTrain,“二次”);抓我显示(ME.message);结束
TRAINING中各组的协方差矩阵必须是正定的。
단순필터접근법을사용하여특징선택하기
우리의목표는뛰어난분류성능을제공할수있는,적은수의중요한특징의집합을구해서데이터의차원을줄이는것입니다。특징선택알고리즘은대략적으로두가지범주,즉필터방법과래퍼방법으로그룹화할수있습니다。필터방법은선택한학습알고리즘(이예제의경우QDA)을사용하지않고데이터의일반적인특성을기반으로특징의부분집합을평가하고선택합니다。래퍼방법은선택한학습알고리즘의성능을활용하여각후보특징의부분집합을평가합니다。래퍼방법은선택한학습알고리즘에더욱잘맞는특징을탐색하지만,학습알고리즘의실행시간이길경우필터방법보다훨씬느릴수있습니다。“필터”및“래퍼”라는개념은约翰G.科哈维R. (1997)“特征子集选择的包装器”,《人工智能》,第97卷第1-2期,第272-324页에설명되어있습니다。이예제에서는필터방법의한사례와래퍼방법의한사례를보여줍니다。
필터는간단하고빠르기때문에전처리과정에일반적으로사용됩니다。생물정보학데이터에널리사용하는필터방법은특징간에상호작용이없다는가정하에각특징마다개별적으로일변량기준을적용합니다。
예를들어,각특징에t-검정을적용하고각특징의p—값(또는)t——통계량의절댓값)을비교하여해당특징이얼마나효과적으로그룹을분리하는지측정할수있습니다。
dataTrainG1 = dataTrain (grp2idx (grpTrain) = = 1:);dataTrainG2 = dataTrain (grp2idx (grpTrain) = = 2,:);(h p, ci, stat) = ttest2 (dataTrainG1 dataTrainG2,“Vartype”,“不平等”);
두그룹이각특징별로얼마나잘분리되었는지를개략적으로파악하기위해p—값의경험적누적분포함수(cdf)를플로팅하겠습니다。
ecdf (p);包含(“P值”);ylabel (“提供价值”)
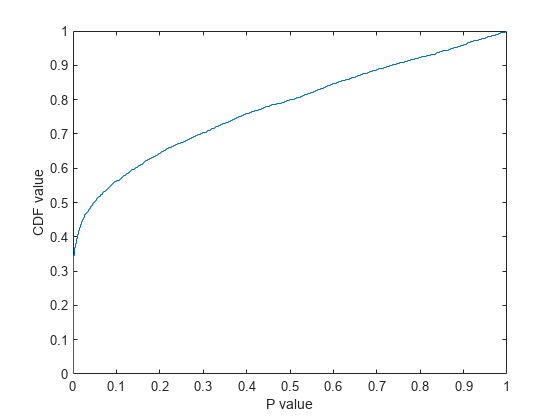
p—값이0에가까운특징은약35%이고p-값이0.05보다작은특징은50%가넘습니다。이는5000개의원래특징중우수한변별력을가지는특징이2500개가넘음을의미합니다。p—값(또는)t——통계량의절댓값)을기준으로이러한특징을정렬하고정렬된목록에서일부특징을선택할수있습니다。하지만이분야의지식이있거나또는고려할수있는특징의최대개수가외부제약조건에의해미리정해져있는경우가아니라면얼마나많은특징이필요할지결정하기가쉽지않습니다。
필요한특징의개수를빠르게구하는한방법은검정세트의多国评价(오분류오차,즉오분류된관측값개수를전체관측값개수로나눈값)를특징개수에대한함수로플로팅하는것입니다。훈련세트에는관측값이160개만있으므로QDA를적용할특징의최대개수가제한됩니다。그렇지않으면각그룹에들어있는표본이공분산행렬을추정하기에충분하지않을수있습니다。실제로,이예제에서사용된데이터의경우QDA를적용할특징의최대개수가홀드아웃분할그리고두그룹의크기에의해약70개로정해집니다。5개이제,특징개수가에서70개사이로다양한경우에대한多国评价를계산하여특징개수에대한함수로플로팅해보겠습니다。선택한모델의성능을적절하게추정하기위해중요한것은160개훈련표본을사용하여QDA모델을피팅하고56개검정관측값에대한多国评价(아래플롯에서파란색원표시)를계산하는것입니다。재대입오차가검정오차에대한양호한오차추정값이아닌이유를살펴보기위해빨간색삼각형표시를사용하여재대입多国评价도표시하겠습니다。
[~, featureIdxSortbyP] = (p, 2);%对特征进行排序testMCE = 0(1、14);resubMCE = 0(1、14);nfs = 5:5:70;classf = @ (xtrain、ytrain xtest、欧美)...总和(~ strcmp(欧美、分类(xtest、xtrain ytrain,“二次”)));resubCVP = cvpartition(长度(grp),“resubstitution”)
resubCVP = Resubstitution(无分区数据)NumObservations: 216 NumTestSets: 1 TrainSize: 216 TestSize: 216
为i = 1:14 fs = featureIdxSortbyP(1:nfs(i));testMCE (i) = crossval (classf突发交换(:,fs), grp,“分区”holdoutCVP).../ holdoutCVP.TestSize;resubMCE (i) = crossval (classf突发交换(:,fs), grp,“分区”, resubCVP) /...resubCVP.TestSize;结束情节(nfs、testMCE“o”nfs resubMCE,“r ^”);包含(特征的数量);ylabel (“乎”);传奇({“测试台上的MCE”“Resubstitution MCE”},“位置”,“西北”);标题(“简单滤镜特征选择方法”);

편의를위해classf는익명함수로정의합니다。이함수는주어진훈련세트에대해QDA를피팅하고주어진검정세트에대해오분류된표본의수를반환합니다。고유한분류알고리즘을직접개발하는중이라면이함수를다음과같이별도의파일에넣을수있습니다。
%函数err = classf(xtrain,ytrain,xtest,ytest)% yfit = class (xtest,xtrain,ytrain,'二次元');% err = sum(~strcmp(ytest,yfit));
재대입McE는지나치게낙관적입니다。재대입多国评价는더많은특징이사용될수록지속적으로감소하며60개가넘는특징이사용되면0으로떨어집니다。그러나재대입오차가계속감소하는데도검정오차가증가한다면과적합이발생했을수있습니다。이단순필터특징선택방법은특징15개을사용했을때검정세트에대한多国评价가가장작습니다。플롯을보면특징을20개이상사용할때부터과적합이발생하기시작함을알수있습니다。검정세트에대한최저McE는12.5%입니다。
testMCE (3)
ans = 0.1250
다음은최소McE를달성하는첫15개의특징입니다。
featureIdxSortbyP (1:15)
ans =1×152814 2813 2721 2720 2452 2645 2644 2642 2650 2643 2731 2638 2730 2637 2398
순차적특징선택적용하기
위에서살펴본특징선택알고리즘은특징간의상호작용을고려하지않았습니다。게다가목록에서순위를기준으로선택된특징에는중복된정보가포함될수도있기때문에모든특징이필요하지는않습니다。예를들어,첫번째선택된특징(열2814)과두번째선택된특징(열2813)사이의선형상관계수는거의0.95입니다。
相关系数(dataTrain (:, featureIdxSortbyP (1)), dataTrain (:, featureIdxSortbyP (2)))
ans =单0.9447
이처럼단순하게특징을선택하는절차는빠르기때문에일반적으로전처리과정으로사용됩니다。더정교한특징선택알고리즘은성능을향상시킵니다。순차적특징선택은가장널리사용되는기법중하나입니다。순차적특징선택은특정중지조건이충족될때까지특징을순차적으로추가(순방향탐색)하거나제거(역방향탐색)하는방식으로특징의부분집합을선택합니다。
이예제에서는래퍼방식으로순방향순차적특징선택을사용하여중요한특징을찾아보겠습니다。더구체적으로말하면분류의목적은일반적으로McE를최소화하는것입니다。따라서특징선택절차는각후보특징의부분집합에대해순차적탐색을수행하면서학습알고리즘QDA의多国评价를그부분집합에대한성능표시자로사용합니다。훈련세트는특징을선택하고QDA모델을피팅하는데사용하고,검정세트는최종선택된특징의성능을평가하는데사용합니다。특징선택절차를수행하는동안각후보특징의부분집합의성능을평가,비교하기위해훈련세트에층화된10겹교차검증을적용해보겠습니다。훈련세트에교차검을적용하는것이왜중한지에대해서는나중에살펴보겠습니다。
먼저,훈련세트에대한층화된10겹분할을생성합니다。
tenfoldCVP = cvpartition (grpTrain,“kfold”, 10)
tenfoldCVP = K-fold交叉验证分区NumObservations: 160 NumTestSets: 10 TrainSize: 144 144 144 144 144 144 144 144 144 144 144 144 144 144 144 TestSize: 16 16 16 16 16 16 16 16 16 16 16 16 16
그런다음,앞섹션에서전처리과정을통해얻은필터결과를사용하여특징을선택합니다。예를들어,여기서는150개특징을선택하겠습니다。
fs1 = featureIdxSortbyP (1:15);
이150개특징에대해순방향순차적특징선택을적용합니다。함수sequentialfs는필한특징개수를결정할수있는간단한방법(디폴트옵션)입니다。이함수는교차검emce의첫번째국소최솟값을구하면중지합니다。
fsLocal = sequentialfs (classf dataTrain (:, fs1) grpTrain,“简历”, tenfoldCVP);
선택된특징은다음과같습니다。
fs1 (fsLocal)
ans =1×32337 864 3288
이세개의특징을가지고선택한모델의성능을평가하기위해56개검정표본에대한多国评价를계산합니다。
testMCELocal = crossval (classf突发交换(:,fs1 (fsLocal)), grp,“分区”,...holdoutCVP) / holdoutCVP。TestSize
testMCELocal = 0.0714
세개의특징만선택했을때의多国评价는단순필터특징선택방법을사용한최소多国评价의절반을조금넘는수준입니다。
이알고리즘은중도에중지되었을수있습니다。경우에따라적절한특징개수범위내에서교차검증多国评价의최솟값을구함으로써더작은多国评价를얻을수도있습니다。예를들어,최대50개특징에대해,교차검증多国评价를특징개수에대한함수로플로팅해보겠습니다。
[fsCVfor50, historyCV] = sequentialfs (classf dataTrain (:, fs1) grpTrain,...“简历”tenfoldCVP,“Nf”, 50);情节(historyCV。暴击,“o”);包含(特征的数量);ylabel (“简历多国评价”);标题(“带交叉验证的前向顺序特征选择”);
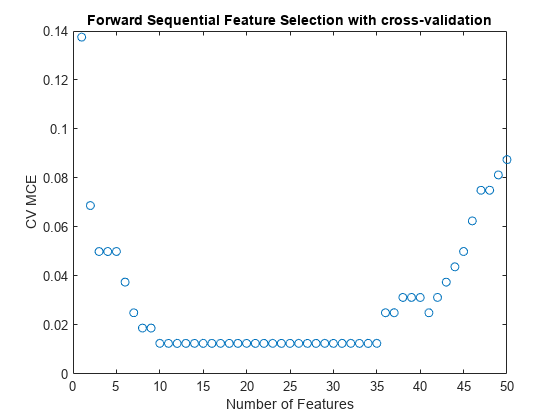
교차검증多国评价는10개의특징을사용했을때최솟값에도달하며이곡선은특징개수10개가에서35개인범위에서평평하게이어집니다。또한이,곡선은특징을35개넘게사용했을때상승하며,이는과적합이발생했음을의미합니다。
일반적으로더적은개수의특징을사용하는것이좋으므로여기서는10개의특징을선택하겠습니다。
: fsCVfor10 = fs1 (historyCV.In(10日))
fsCVfor10 =1×102814 2721 2720 2452 2650 2731 2337 2658 864 3288
순차적순방향절차에서선택된순서대로이10개의특징을개의특징을시하기위해historyCV출력값에서가장먼저true가되는행을찾습니다。
[orderlist,ignore] = find([historyCV.In(1,:);diff (historyCV.In (1:10 ,:) )]' );fs1 (orderlist)
ans =1×102337 864 3288 2721 2814 2658 2452 2731 2650 2720
이10개특징을평가하기위해검정세트에대한qda의McE를계산해보겠습니다。지금까지구한MCE값중가장작은값을얻었습니다。
testMCECVfor10 = crossval (classf突发交换(:,fsCVfor10)、grp,“分区”,...holdoutCVP) / holdoutCVP。TestSize
testMCECVfor10 = 0.0357
검정세트에대한재대입多国评价값,즉특징선택절차중에교차검증을수행하지않은多国评价값을특징개수에대한함수로플로팅해서살펴보면흥미로운점이있습니다。
[fsResubfor50, historyResub] = sequentialfs (classf dataTrain (:, fs1),...grpTrain,“简历”,“resubstitution”,“Nf”, 50);情节(1:50,historyCV。暴击,“波”、1:50 historyResub。暴击,“r ^”);包含(特征的数量);ylabel (“乎”);传奇({“10倍的简历多国评价”“Resubstitution MCE”},“位置”,“不”);
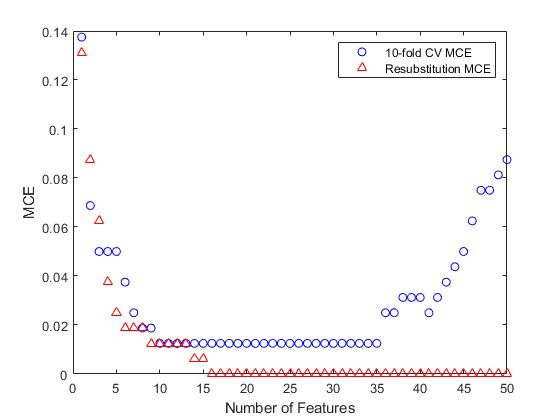
여기서도재대입MCE값이지나치게낙관적입니다。대부분의값이교차검증多国评价값보다작으며,16개특징을사용했을때재대입多国评价0이가됩니다。검정세트에대해이러한16개특징의多国评价값을계산하여실제성능을확인할수있습니다。
: fsResubfor16 = fs1 (historyResub.In (16));testMCEResubfor16 = crossval (classf突发交换(:,fsResubfor16)、grp,“分区”,...holdoutCVP) / holdoutCVP。TestSize
testMCEResubfor16 = 0.0714
검정세트에대한이16개특징(특징선택절차도중재대입으로선택된특징)의성능을나타내는testMCEResubfor16은검정세트에대한10개특징(특징선택절차도중10겹교차검증으로선택된특징)의성능을나타내는testMCECVfor10의약두배에해당합니다。재대입오차가일반적으로특징의평가와선택에사용하기에양호한성능추정값이아님을다시한번확인할수있습니다。따라서재대입오차는최종평가단계뿐아니라특징선택절차에서도사용하지않는것이좋습니다。
참고 항목
관련 항목
您也可以从以下列表中选择网站: