使用高数组的大数据统计和机器学习
此示例演示如何使用MATLAB®和统计与机器学习工具箱对内存不足的数据执行统计分析和机器学习™.
高数组和表是为处理内存不足的数据而设计的。这种类型的数据由大量的行(观察值)组成,而列(变量)的数量较少。与使用MapReduce编写考虑到巨大数据量的专用代码不同,您可以使用高数组以类似于内存中的MATLAB数组的方式处理大型数据集。根本区别在于,在您请求执行计算之前,高数组通常保持未评估状态。
当您在高数组上执行计算时,MATLAB®使用一个并行池(如果您有parallel Computing Toolbox™,则默认)或本地MATLAB会话。要在使用并行计算工具箱时使用本地MATLAB会话运行示例,请使用地图还原器功能。
地图还原程序(0)
本例使用一台计算机上的数据子集开发线性回归模型,然后将其放大以分析所有数据集。您可以将此分析进一步放大到:
处理无法读入内存的数据
使用MATLABPLASSERD Server™与分布群集群的数据一起使用
与Hadoop®和Spark®等大数据系统集成
塔式阵列机器学习简介
统计学和机器学习工具箱中的一些非监督和监督学习算法可用于使用高数组执行数据挖掘和内存不足的数据预测建模。这些算法适用于内存不足的数据,并可能包含与内存中的算法的轻微差异。功能包括:
k-均值聚类
线性回归
广义线性回归
逻辑回归
判别分析
MATLAB中内存不足数据的机器学习工作流类似于内存数据:
预处理
探索
发展模式
验证模型
扩展到更大的数据
本例在开发航空航班延误预测模型时遵循了类似的结构。这些数据包括从1987年到2008年的航空公司航班信息的大量文件。示例目标是根据许多变量预测起飞延误。
关于高阵列的基本方面的细节包括在这个例子中利用高数组在MATLAB中分析大数据.这个例子扩展了分析,包括使用高数组的机器学习。
创建航空公司数据的高表
数据存储是存放过大而无法放入内存的数据集合的存储库。您可以从许多不同的文件格式创建数据存储,作为从外部数据源创建高数组的第一步。
为示例文件创建数据存储Airlinesmall.csv.. 选择感兴趣的变量,然后进行处理“NA”值作为缺少的数据,并生成数据的预览表。
ds=数据存储(完整文件(matlabroot,“工具箱”,matlab的,“演示”,“airlinesmall.csv”));ds.SelectedVariableNames={“年”,“月”,“月日”,“星期五”,...“DepTime”,“ArrDelay”,“德布雷”,“距离”};ds.TreatAsMissing=“NA”; pre=预览(ds)
pre =8×8表年月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月月-13731987 10283144659633081987 10849283-24471987 1010685911-1954
创建一个由数据存储支持的高表,以方便处理数据。高数组的底层数据类型取决于数据存储的类型。在本例中,数据存储是表格文本并返回一个高表。显示包括数据的预览,并指出大小未知。
tt=高(ds)
tt = Mx8高表年月DayofMonth DayOfWeek DepTime ArrDelay DepDelay距离 ____ _____ __________ _________ _______ ________ ________ ________ 1987 21 308 642 8 12 1987 10 26 1 1021 8 296 1987 10 23 5 2055 21 480 1987 10 23 5 1332 13 12 296 1987 10 22 4 629 1446 1 373 1987 10 28 3 59 63 308 1987 10 928 4 3 2 447 1987 1011 954 859 6 : : : : : : : : : : : : : : : :
预处理数据
这个例子旨在更详细地探讨一天中的时间和一周中的一天。将一周的一天转换为带有标签的分类数据,并从数字出发时间变量确定一天的小时。
tt.DayOfWeek=分类(tt.DayOfWeek,1:7{“太阳”,“妈妈”,“周二”,...“结婚”,“Thu”,“星期五”,“坐”});tt.hr =离散化(tt.deptime,0:100:2400,0:23)
tt = Mx9高表年月DayofMonth DayOfWeek DepTime ArrDelay DepDelay距离人力资源 ____ _____ __________ _________ _______ ________ ________ ________ __ 21个外胎1987 642 8 1021 308 6 1987年10 26太阳8 2055 296 1987 10 23日星期四21 480 296 1987 10 1332年清华23日13 12 13 1987 629 22结婚4 1 373 6 1987 10 28外胎1446 59 63 30814 1987 10 8 Wed 928 3 -2 447 9 1987 10 10 friday 859 11 -1 954 8::::::::::::::::::
仅在2000年后仅包含年份并忽略缺少数据的行。通过逻辑条件识别感兴趣的数据。
idx=tt.年份>=2000&...~任何(ismissing (tt), 2);tt = tt (idx:);
按组浏览数据
对于高数组,可以使用一些探索函数。例如,grpstats函数计算塔式阵列的分组统计信息。通过确定数据的中心性和分布以及按星期几分组的汇总统计信息来探索数据。此外,探索出发延迟和到达延迟之间的相关性。
g=grpstats(tt(:{“ArrDelay”,“德布雷”,“星期五”}),“星期五”,...{“的意思是”,“性病”,“偏斜”,“峰度”})
10.g=Mx11 11.高表表词词组,表表词组,表表词组,表词组,表词组,表词组,表词组,表词组,表词组,表词组,表词组,表词组,表词组,表词组,表词组,表词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组,词组(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? : : : : : : : : : : : : : : : : : : : : : :
C=corr(tt.DepDelay,tt.ArrDelay)
C = MxNx……高大的数组???...???...? ? ? ... : : : : : :
这些命令会产生更大的数组。直到您显式地将结果收集到工作区中,这些命令才会执行。这个聚集命令触发执行,并试图最小化执行计算所需的数据传递次数。聚集要求生成的变量适合内存。
[statsByDay C] =收集(g、C)
using the Local MATLAB Session: - Pass 1 of 1: Completed in 4 sec
平日=7×11表一周一周一周一周一周一周一组标签标签一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周的一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周标签一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一组一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一周一(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题)(小标题))()小标题))(小标题星期五7339 4.1512 32.1 7.082 120.53 7.0857 29.339 8.9387 168.37{'Mon'}Mon 8443 5.2487 32.453 4.5811 37.175 6.8319 28.573 5.6468 50.271{'Sat'}Sat 8045 7.132 33.108 3.6457 22.991 9.1557 29.731 4.5135 31.228{'Sun'}Sun'}Sun'}Sun'}8570 7.7515 36.003 5.7980.9.3324 32.516.214}Thu 8601 10.053 36.18 4.1381 37.051 10.923 34.708 1.1414 138.38{'Tues'}Tues 8381 6.4786 32.322 4.374 38.694 7.6083 28.394 5.2012 46.249{'Wed'}Wed 8489 9.3324 37.406 5.1638 57.479 10 33.426 6 6.4336 85.426
C=0.8966
包含结果的变量现在位于工作区的内存变量中。根据这些计算,数据会发生变化,延迟之间存在相关性,您可以进一步调查。
探索一周中的某一天和一天中的某一小时的影响,并获得额外的统计信息,如平均值的标准误差和平均值的95%置信区间。可以传递整个tall表格并指定要对其执行计算的变量。
byDayHr=grpstats(tt{“人力资源”,“星期五”},...{“的意思是”,扫描电镜的,'vesci'},“数据变量”,“德布雷”);byDayHr=聚集(byDayHr);
使用本地MATLAB会话评估tall表达式:-通过1/1:在6.1秒内完成评估在7.1秒内完成
由于tall数组的数据分区,输出可能是无序的。重新排列内存中的数据,以便进一步探索。
x=取消堆叠(按天数)(:{“人力资源”,“星期五”,“平均延迟”}),...“平均延迟”,“星期五”);x = sortrows (x)
x=24×8表人力资源孙Mon外胎结婚星期四星期五坐 __ _______ ________ ________ _______ _______ _______ _______ 0 38.519 71.914 39.656 34.667 90 25.536 65.579 45.846 27.875 93.6 125.23 52.765 38.091 29.182 - 2南39 102 78.25 - -1.5南南南南南南-7.3333 - -10.5 -377.5 -6.2857 53.5南4 7 7 5南5 -2.2409 -3.7099 -4.0146 -3.9565 -3.5897 -3.5766 -4.14747 6 0.4 -1.8909 -1.9802 -1.8304 -1.3578 0.84161 -2.2537 3.4173 -0.47222 -0.18893 0.71546 0.08 1.069 -1.3221 8 2.5325 2.3759 1.4054 1.6745 2.2345 2.9668 1.6727 0.88213 9 10 1.6805 2.7656 2.683 5.6138 3.4838 2.5011 6.37 5.2868 3.6822 7.5773 5.3372 6.9391 4.9979 11 12 6.9946 4.9165 5.5639 5.5936 7.0435 4.8989 5.2839 5.673 5.1193 - 5.7081 7.9178 - 7.52698.0625 7.4686 13 8.0879 7.1017 5.0857 8.8082 8.2878 8.0675 6.2107 14 9.5164 5.8343 7.416 9.5954 8.6667 6.0677 8.444 15 8.1257 4.8802 7.4726 9.8674 10.235 7.167 8.6219⋮
在高阵列中可视化数据
目前,您可以使用直方图,组织图2,binScatterPlot,ksdensity。可视化都会触发执行,类似于调用聚集功能。
使用binScatterPlot来检验两者的关系人力资源和DepDelay变量。
binScatterPlot (tt.Hr tt.DepDelay,“伽马”, 0.25)
使用本地MATLAB会话评估tall表达式:-通过1次1次:在2.7秒内完成评估在3.8秒内完成使用本地MATLAB会话评估tall表达式:-通过1次1次1次:在2.4秒内完成评估在2.7秒内完成
ylim([0 500])xlabel(“一天中的时间”) ylabel ('延迟(分钟)')
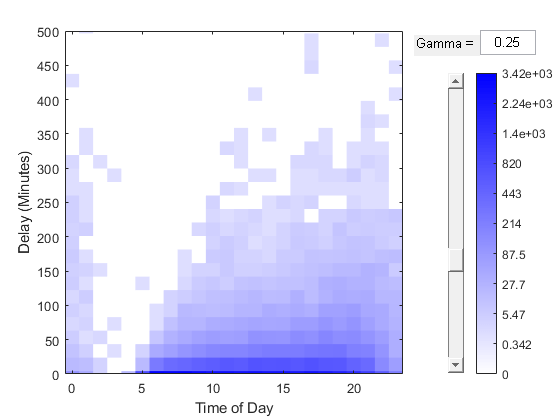
如输出显示中所述,可视化通常通过两次数据传递:一次执行装箱,另一次执行装箱计算并生成可视化。
将数据拆分为培训集和验证集
为了开发机器学习模型,保留一部分数据用于训练和开发模型,保留另一部分数据用于测试模型是很有用的。有许多方法可以将数据分割为训练集和验证集。
使用数据样本获取数据的随机抽样。然后使用CVD分区将数据划分为测试集和训练集。若要获得非批准的分区,请通过将数据样本乘以零来设置统一的分组变量。
为重现性,使用随机数生成器设置种子塔林.结果可能会根据高数组的工作人员数量和执行环境而有所不同。有关详细信息,请参见控制代码运行的位置.
tallrng ('默认') data = datasample(tt,25000,“替换”,假);组=0*data.depday;y=分区(组,“坚持”, 1/3);dataTrain =数据(训练(y):);人数(=数据(测试(y):);
Fit监督学习模型
建立了基于多变量的航班延误预测模型。线性回归模型函数菲特姆行为类似于内存中的函数。但是,使用高数组进行计算会导致紧凑线性模型,这对于大型数据集更有效。模型拟合会触发执行,因为这是一个迭代过程。
模型= fitlm (dataTrain,“ResponseVar”,“德布雷”)
using the Local MATLAB Session: - Pass 1 of 2: Completed in 1.5 sec - Pass 2 of 2: Completed in 5.3 sec
model =紧凑线性回归模型:DepDelay ~[8个预测因子9项线性公式]估计值__________ __________ ________ __________(截距)年-0.01585 0.037853 -0.41872 0.67543月- 0.03009 0.028097 1.0709 0.28421 DayofMonth -0.0094266-0.56082 0.35309 -1.5883 0.11224 DayOfWeek_Thu -0.25295 0.35239 -0.71782 0.47288 DayOfWeek_Fri 0.91768 0.36625 2.5056 0.012234 DayOfWeek_Sat 0.45668 0.35785 0.2762 0.20191 DepTime -0.011551 0.0053851 -2.145 0.031964 ArrDelay 0.8081 0.002875 281.08 0距离0.0012881 0.00016887 7.6281 Hr 1.4058 0.53785 2.6138 0.0089613数量观测值:16667,误差自由度:16653均方根误差:12.4 r平方:0.834,校正r平方:0.833 F-statistic vs. constant model: 6.41e+03, p-value = 0
预测并验证模型
显示显示适合的信息,以及系数和相关的系数统计。
这个模型变量包含有关拟合模型的信息作为属性,可以使用点表示法访问该属性。或者,双击工作区中的变量以交互地探索属性。
模型。Rsquared
ans=带字段的结构:普通:0.8335调整:0.8334
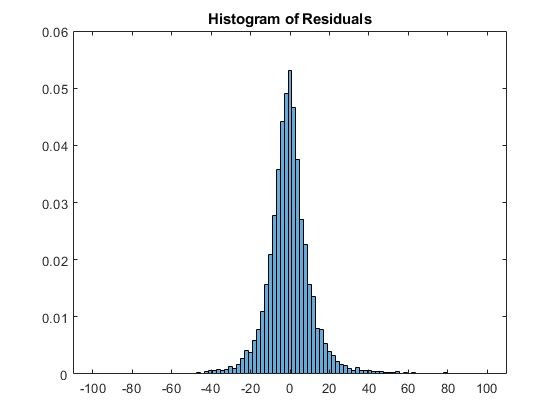
根据模型预测新值,计算残差,并使用直方图进行可视化。这个预测函数预测高数据和内存数据的新值。
pred=predict(模型,数据测试);err=pred-dataTest.DepDelay;图形直方图(err,“BinLimits”(-100 100),“归一化”,“pdf”)
使用本地MATLAB会议评估高表达: - 通过第1项,共2分:3.5秒段 - 通过2的第2条:在1.9秒的评估中完成,在6.5秒内完成
标题('残留的直方图')
评估和调整模型
查看显示器中的输出p值,模型中可能不需要某些变量。您可以通过删除这些变量来降低模型的复杂性。
检验变量的重要性,在模型中更密切地使用方差分析.
a=方差分析(模型)
A =9×5表中国货币基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金基金6012 0.031964 ARRRDELAY 1.2112e+07 1.2112e+07 79004 0距离8920.9 1 8920.9 58.1882.5106e-14 Hr 1047.5 1 1047.5 6.8321 0.0089613错误2.5531e+06 16653 153.31
根据p值,变量年,月,DayOfMonth对该模型不重要,因此您可以删除它们而不会对模型质量产生负面影响。
要进一步探索这些模型参数,请使用诸如的交互式可视化绘图切片,plotInterations,情节效应.例如,使用情节效应检查每个预测变量对发车延误的估计影响。
绘图效果(模型)
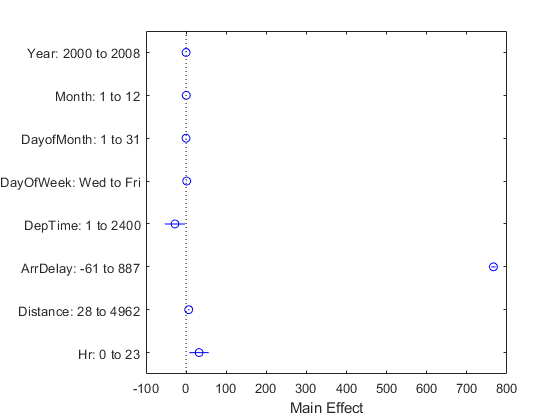
根据这些计算,ArrDelay模型中的主要效应(它与DepDelay).其他影响是可以观察到的,但影响要小得多。此外,人力资源决定于戴普泰姆,因此模型只需要这些变量中的一个。
减少变量的数量以排除所有的数据成分,然后拟合一个新的模型。
模型2=fitlm(数据列车,“DepDelay~DepTime+ArrDelay+Distance”)
使用本地MATLAB会话评估tall表达式:-通过1/1:在2.9秒内完成评估在3.1秒内完成
model2 =紧凑线性回归模型:DepDelay ~ 1 + DepTime + ArrDelay + Distance Estimated Coefficients:Estimate SE tStat pValue _________ __________ _______ __________ (Intercept) -1.4646 0.31696 -4.6207 3.8538e-06 DepTime 0.0025087 0.00020401 12.297 1.3333e-34 ArrDelay 0.80767 0.0028712 281.3 0距离0.0012981 0.00016886 7.6875 1.5838e-14观测数:16667,误差自由度:16663均方根误差:12.4 R-squared:0.833,调整后的R-Squared: 0.833 F-statistic vs. constant model: 2.77e+04, p-value = 0
模型开发
即使使用模型简化,进一步调整变量与特定交互之间的关系也很有用。要尝试进一步,请用较小的高阵列重复此工作流程。对于调整模型时的性能,您可以考虑在缩放到整个高阵列之前的内存数据的小提取。
在这个例子中,您可以使用类似逐步回归的功能,它适合迭代的、内存中的模型开发。在优化模型之后,您可以扩展到使用高数组。
将数据的子集收集到工作区中并使用stepwiselm在内存中迭代地开发模型。
子集=聚集(DataTest);
使用本地MATLAB会话评估tall表达式:-通过1/1:在1.8秒内完成评估在1.9秒内完成
sModel=逐步lm(子集,“ResponseVar”,“德布雷”)
1.加上ArrDelay,FStat=42200.3016,pValue=0.2。加上DepTime,FStat=51.7918,pValue=6.70647e-13。添加DepTime:ArrDelay,FStat=42.4982,pValue=7.48624e-11 4。加上距离,FStat=15.4303,pValue=8.62963e-05 5。添加ArrDelay:Distance,FStat=231.9012,pValue=1.135326e-516。加上星期几,FStat=3.4704,pValue=0.0019917 7。添加星期日:ArrDelay,FStat=26.334,pValue=3.16911e-31 8。添加DayOfWeek:DepTime,FStat=2.1732,pValue=0.042528
sModel=线性回归模型:DEPDLAY ~[四个预测因子中有9项的线性公式]估计系数:估计当前pValue uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(截距)1.4951 0.41109 0.62109 0.62109 0.62338 8 0.41109 0.62338 8 8 0.41109 0.419 0.419 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 1.468 1.4683-4.2868 1.468 8 1.468 8 8 8 8 8 8 8 1.4683-2.4683-2.9 9 9 9 9 9 9 9 9 9 9 9 9 9-2.468-2.468-2.6 8-2.9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9-2.8-2.8-2.9 9 9 9 9 9 9 9-2.9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9-2.9 9 9 9 9 9 9 9 9 9 9 9 9 9-2.9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 10219 0.9186ArrDelay 0.8671 0.013836 62.669 0距离0.0015163 0.00023426.4728 1.0167e-10星期一:DepTime 0.0017633 0.0010106 1.7448 0.081056星期二:DepTime 0.0032578 0.0010331 3.1534 0.0016194星期三:DepTime 0.00097506 0.001044 0.93398 0.35034星期四:DepTime 0.0012517 0.001061.17064星期五:DepTime0.0010711 2.4707 0.013504星期一星期六:DepTime 0.0021477 0.0010646 2.0174 0.043689星期一:抵达延迟-0.11023 0.014744-7.4767 8.399e-14星期二:抵达延迟-0.14589 0.014814-9.8482 9.2943e-23星期三:抵达延迟-0.041878 0.012849-3.2593 0.1215星期五:抵达延迟-0.01393-14星期五:抵达延迟-0.01943-14星期五-0.077713 0.015462-5.0259 5.1147e-07星期六:ArrDelay-0.13669 0.014652-9.329 1.3471e-20 DepTime:ArrDelay 6.4148e-05 7.7372e-06 8.2909 1.3002e-16 ArrDelay:Distance-0.00010512 7.3888e-06-14.2272 2.1138e-45观测次数:8333,误差自由度:8309均方根误差:12 R平方:0.845,调整后的R平方:0.845 F统计与常数模型:1.97e+03,p值=0
逐步拟合得到的模型包括相互作用项。
现在试着用菲特姆使用返回的公式stepwiselm.
Model3 = fitlm(DataTrain,smodel.formula)
using the Local MATLAB Session: - Pass 1 of 1: Completed in 3.5 sec
模型3=紧凑型线性回归模型:DepDelay ~[四个预测因子中有9项的线性公式]估计系数:估计统计值uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu(截距)1.0473-0.4173-0.417-0.417-0.417-0.417-0.417-0.417-0.417-0.316 0.537 7 7 7 7 7.537-0.537 7-0.537-0.537-0.417-0.537-0.417-0.417-0.417-0.417-0.417-0.417-0.417-0.157 0.0.0.157 0.0.157 0.017.017.017.0159597 7 7.157 0.157 0.157 0.015967-0.157 0.015967-0.015967-0.157 0.157 0.015967-0.157 0.015967-0.157 0.157 0.015967.015967-0.157 0.015967 7 7 7 7 7 7 7 7 7 7 7 7.89 0.0059853到达延迟0.72526 0.011907 60.913 0距离0.0014824 0.00017027 8.7059 3.4423e-18星期一:延迟0.00040994 0.00073548 0.55738 0.57728星期二:延迟0.00051826 0.00073645 0.70373 0.48161星期三:延迟0.00058426 0.00073695 0.79281 0.42790.0002959 0.00077194 0.38332 0.70149星期六:DepTime-0.00060921 0.00075776-0.80396 0.42143星期一:ArrDelay-0.034886 0.010435-3.3432 0.00082993星期二:ArrDelay-0.0073661 0.010113-0.72837 0.4664星期三:ArrDelay-0.028158 0.0099004-2.8441 0.00444-1065-0.885星期五星期五:ArrDelay 0.052437 0.010927 4.7987 1.6111e-06星期六:ArrDelay 0.014205.01039 1.3671 0.1716 DepTime:ArrDelay 7.2632e-05 5.3946e-06 13.464 4.196e-41 ArrDelay:距离-2.4743e-05 4.6508e-06-5.3203 1.0496e-07观测次数:16667,误差自由度:16643均方根误差:12.3 R平方:0.837,经调整平方米红色:0.836 F-统计与常数模型:3.7e+03,p-值=0
您可以重复此过程以继续调整线性模型。但是,在这种情况下,您应该探索可能更适合此数据的不同类型的回归。例如,如果您不想包含到达延迟,那么这种类型的线性模型不再适当。看高数组Logistic回归为更多的信息。
缩放到火花
MATLAB和Statistics and Machine Learning Toolbox中的tall数组的一个关键功能是与Hadoop和Spark等平台的连接。您甚至可以使用MATLAB编译器编译代码并在Spark上运行™. 看见使用其他产品扩展高阵列s manbetx 845有关使用这些产品的更多信息:s manbetx 845
数据库工具箱™
并行计算工具箱™
MATLAB®并行服务器™
MATLAB编译器™
相关的话题
你也可以从以下列表中选择一个网站:
