trainWordEmbedding
训练词嵌入
描述
例子
从文件中训练词嵌入
使用示例文本文件训练一个维度为100的单词嵌入sonnetsPreprocessed.txt.这个文件包含了莎士比亚十四行诗的预处理版本,每行有一首十四行诗,单词之间用一个空格隔开。
文件名=“sonnetsPreprocessed.txt”;emb = trainwordem寝料(文件名)
训练:100%损失:3.26708剩余时间:0小时0分钟。
词汇:["你的" "你" "爱" "你" "做"…]
查看文本散点图中嵌入的单词tsne.
单词= emb.词汇;V = word2vec(emb,words);XY = tsne(V);textscatter (XY,话说)
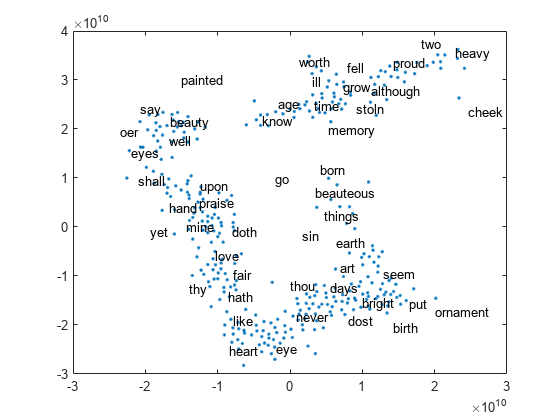
训练文档中的词嵌入
使用示例数据训练单词嵌入sonnetsPreprocessed.txt.这个文件包含莎士比亚十四行诗的预处理版本。该文件每行包含一首十四行诗,用空格分隔单词。从中提取文本sonnetsPreprocessed.txt,以换行符将文本分割为文档,然后对文档进行标记。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData = split(str,换行符);documents = tokenizedDocument(textData);
训练单词嵌入使用trainWordEmbedding.
emb = trainWordEmbedding(文档)
训练:100%损失:3.15383剩余时间:0小时0分钟。
词汇:["你的" "你" "爱" "你" "做"…]
可视化单词嵌入文本散点图使用tsne.
单词= emb.词汇;V = word2vec(emb,words);XY = tsne(V);textscatter (XY,话说)
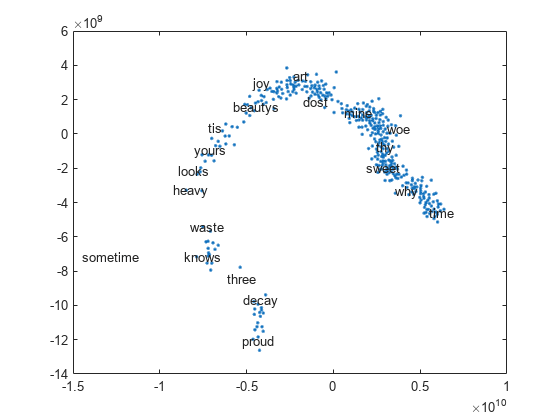
指定单词嵌入选项
加载示例数据。该文件sonnetsPreprocessed.txt包含莎士比亚十四行诗的预处理版本。该文件每行包含一首十四行诗,用空格分隔单词。从中提取文本sonnetsPreprocessed.txt,以换行符将文本分割为文档,然后对文档进行标记。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData = split(str,换行符);documents = tokenizedDocument(textData);
指定单词嵌入维数为50。若要减少模型丢弃的单词数,请设置“MinCount”为3。若要训练更长的时间,请将epoch的数量设置为10。
emb = trainwordem寝料(文档,...“维度”, 50岁,...“MinCount”3,...“NumEpochs”, 10)
训练:100%损失:2.75878剩余时间:0小时0分钟。
词汇["你的" "你" "爱" "你" "做"…]
查看文本散点图中嵌入的单词tsne.
单词= emb.词汇;V = word2vec(emb, words);XY = tsne(V);textscatter (XY,话说)
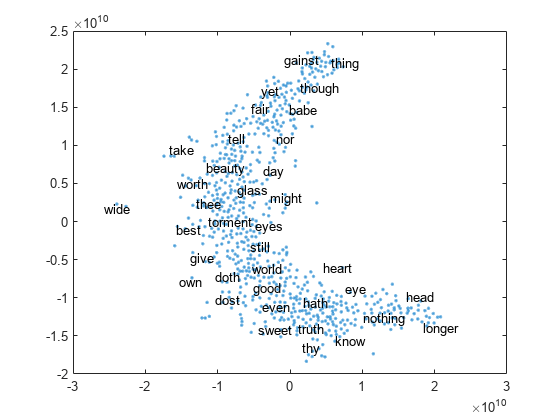
输入参数
输出参数
更多关于
提示
训练算法使用函数给出的线程数maxNumCompThreads.学习如何改变MATLAB使用的线程数®,请参阅maxNumCompThreads.
版本历史
在R2017b中引入
您也可以从以下列表中选择一个网站: