토픽모델을사용하여텍스트데이터분석하기
이예제에서는LDA(잠재디리클레할당)토픽모델을사용하여텍스트데이터를분석하는방법을보여줍니다。
LDA(잠재디리클레할당)모델은문서모음에서기저토픽을발견하고토픽내단어확률을추정하는토픽모델입니다。
텍스트데이터불러오기및추출하기
예제데이터를불러옵니다。factoryReports.csv파일에는각이벤트에대한텍스트설명과범주레이블이포함된공장보고서가들어있습니다。
数据=可读数据(“factoryReports.csv”TextType =“字符串”);头(数据)
ans =8×5表类别描述紧急解决成本 _____________________________________________________________________ ____________________ ________ ____________________ _____ " 项目是偶尔陷入扫描仪卷。”“机械故障”“中等”“重新调整机”45“装配活塞发出巨大的嘎嘎声和砰砰声。”“机械故障”“中等”“重新调整机器”“开机时电源有故障。”"电子故障" "高" "完全更换" 16200 "装配器电容器烧坏"“电子故障”“高”“更换部件”“352”“混合器熔断器触发。”"电子故障" "低" "列入观察名单" 55 "爆裂管道中施工剂正在喷洒冷却剂""泄漏" "高" "更换部件" 371 "搅拌机保险丝烧断。"“电子故障”“信号低”“更换部件”“东西继续从传送带上掉下来。”"机械故障" "低" "调整机
描述필드에서텍스트데이터를추출합니다。
textData = data.Description;textData (1:10)
ans =10×1的字符串“物品偶尔会卡在扫描仪线轴上。”“组装活塞发出巨大的嘎嘎声和砰砰声。”“在启动工厂时,电力会被切断。”“组装机里的电容器烧坏了。”“混频器把保险丝弄断了。”"爆裂管道内的施工剂正在喷洒冷却剂"“搅拌机里的保险丝烧断了。”“东西继续从传送带上掉下来。”“传送带上落下的物品。”扫描器卷筒裂开了,很快就会开始弯曲。
분석할텍스트데이터준비하기
분석에사용할수있도록텍스트데이터를토큰화하고전처리하는함수를만듭니다。이 예제의전처리함수섹션에나오는함수preprocessText는다음단계를순서대로수행합니다。
tokenizedDocument를사용하여텍스트를토큰화합니다。normalizeWords를사용하여단어의@ @제어를추출합니다。erasePunctuation을사용하여문장부호를지웁니다。removeStopWords를사용하여불용어목록(예:“and”,“of”,“the”)을제거합니다。removeShortWords를사용하여2자이하로이루어진단어를제거합니다。removeLongWords를사용하여15자이상으로이루어진단어를제거합니다。
preprocessText함수를사용하여분석할텍스트데이터를준비합니다。
documents = preprocessText(textData);文档(1:5)
ans = 5×1 tokenizedDocument: 6令牌:物品偶尔卡住扫描仪线轴7令牌:响亮的咔咔声来装配活塞4令牌:切断电源启动装置3令牌:炸电容器装配3令牌:混合器跳闸保险丝
토큰화된문서에서字袋모델을만듭니다。
bag = bagOfWords(文档)
bag = bagOfWords with properties:计数:[480×338 double]词汇:[1×338 string] NumWords: 338 NumDocuments: 480
총2회이하로나타나는단어를字袋모델에서제거합니다。词汇袋모델에서단어를포함하지않는모든문서를제거합니다。
袋子= removeInfrequentWords(袋子,2);包= removeEmptyDocuments(包)
bag = bagOfWords with properties:计数:[480×158 double]词汇:[1×158 string] NumWords: 158 NumDocuments: 480
Lda모델피팅하기
7개토픽으로lda모델을피팅합니다。토픽수를선택하는방법을보여주는예제는Lda모델의토픽수선택하기항목을참조하십시오。세부정보가출력되지않도록详细的옵션을0으로설정합니다。재현성을위해rng함수를“默认”옵션과함께사용합니다。
rng (“默认”) numTopics = 7;mdl = fitlda(包,numTopics,Verbose=0);
대규모데이터세트가있는경우확률적근사변분베이즈솔버는일반적으로전달되는데이터가적을때양호한모델을피팅할수있으므로더적합합니다。fitlda吉布斯(축소된샘플링)용디폴트솔버는더정확하지만실행시간이오래걸릴수있습니다。확률적근사변분베이즈를사용하려면解算器옵션을“savb”로설정하십시오。Lda솔버비교방법을보여주는예제는比较LDA求解器항목을참조하십시오。
워드클라우드를사용하여토픽시각화하기
워드클라우드를사용하면각토픽에서확률이가장높은단어를볼수있습니다。워드클라우드를사용하여토픽을시각화합니다。
图t = tiledlayout(“流”);标题(t)“LDA的话题”)为i = 1:numTopics nexttile wordcloud(mdl,i);标题(“主题”+ i)结束

문서의토픽혼합보기
앞에서나오지않은문서세트에대해훈련데이터처럼동일하게전처리함수를사용하여토큰화된문서로구성된배열을만듭니다。
STR = [“冷却剂正在组装器下面聚集。”“分拣机在启动时炸断保险丝。”“有一些非常响亮的咔嗒声从组装。”];newDocuments = preprocessText(str);
变换함수를사용하여문서를토픽확률로구성된벡터로변환합니다。매우짧은문서에서는토픽혼합이문서내용을강하게@ @현하지못할수있습니다。
topicmixture = transform(mdl,newDocuments);
첫번째문서의문서토픽확률을막대차트에플로팅합니다。토픽에레이블을지정하기위해해당토픽의상위3개단어를사용합니다。
为i = 1:numTopics top = topkwords(mdl,3,i);topWords(i) = join(top。词,”、“);结束图栏(topicmixture (1,:)) xlabel(“主题”) xticklabels (topWords);ylabel (“概率”)标题(“文档主题概率”)
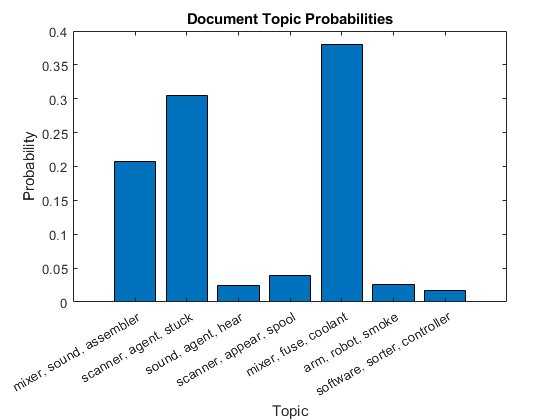
누적형막대차트를사용하여여러토픽혼합을시각화합니다。문서의토픽혼합을시각화합니다。
图barh (topicMixtures,“堆叠”xlim([0 1])“主题混合”)包含(“主题概率”) ylabel (“文档”)传说(topWords...位置=“southoutside”,...NumColumns = 2)

전처리함수
함수preprocessText는다음단계를순서대로수행합니다。
tokenizedDocument를사용하여텍스트를토큰화합니다。normalizeWords를사용하여단어의@ @제어를추출합니다。erasePunctuation을사용하여문장부호를지웁니다。removeStopWords를사용하여불용어목록(예:“and”,“of”,“the”)을제거합니다。removeShortWords를사용하여2자이하로이루어진단어를제거합니다。removeLongWords를사용하여15자이상으로이루어진단어를제거합니다。
函数documents = preprocessText(textData)标记文本。documents = tokenizedDocument(textData);把这些词简化。文档= addPartOfSpeechDetails(文档);文档= normalizeWords(文档,样式=“引理”);删除标点符号。documents = eraspunctuation(文档);删除一个停止词列表。documents = removeStopWords(文档);删除2个或更少字符的单词,以及15个或更多字符的单词%字符。文档= removeShortWords(文档,2);documents = removeLongWords(documents,15);结束
참고 항목
tokenizedDocument|bagOfWords|removeStopWords|fitlda|ldaModel|wordcloud|addPartOfSpeechDetails|removeEmptyDocuments|removeInfrequentWords|变换
관련 항목
您也可以从以下列表中选择一个网站: