前突深神经红
Se puede效用una red de clasificación de imágenes preentrenada que ya haya aprendido a extrer características potentes e informativas a partir de imágenes自然和效用como punto de partida para aprender una tarea nueva。La mayoría de redes preentrenadas se entrenan con un subconjunto de La base de datos ImageNet[1]ImageNet大规模视觉识别挑战赛(ILSVRC)[2].Estas redes se han entrenado con más de un millón de imágenes y pueden clasificarlas en 1000 categorías de objectos (por ejemplo, teclado, taza de café, lápiz y muchos animales)。用那红色的前前后后的转场,用那红的转场,用那红的转场,用那红的转场,用那红的转场,用那红的转场。
在此之前,在此之前,在此之前,在此之前:
| Finalidad | Descripcion |
|---|---|
| Clasificacion | 一个问题clasificación。对新意象的分类,运用 |
| Extracción de características | 实用的una红preentrenada como un提取de características实用的las activaciones de las capas como características。Puede utilizar estas activaciones como características para entrar otro modelo de机器学习,como una máquina de向量de soporte (SVM)。Para obtener más información, consulteExtracción de características.Para ver un ejemplo, consulte利用预训练网络提取图像特征. |
| Transferencia del prendizaje | 在大的数据上,在大的数据上,在新的数据上,在大的数据上,在新的数据上。Para obtener más información, consulteTransferencia del prendizaje.Para ver un ejemplo senciillo, consulteIntroducción这是上天的恩赐.Para probar más redes preentrenadas, consulteEntrenar redes de深度学习para classification nuevas imágenes. |
比较当前的情况
我们之间的关系是不同的características我们之间的关系是不一样的。Las características más importantes son la precisión, la velocidad y el tamaño de la red。我们的挽歌,为我们的生活着想características。利用la siguiente gráfica para compare la precisión de validación de ImageNet con el timemo必要时间para hacer una predicción中间la red。
Sugerencia
Para comenzar con la transferencia del arendizaje, pruebe a selecciciar una de las redes más rápidas, como SqueezeNet o GoogLeNet。A continuación, puede iterar rápidamente y probar不同的配置,como pasos de preesesamian de datos和las opciones de entrenamian。我们的想法cuál我们的家园configuración,我们的家园más,我们的家园,我们的家园。

背板
La gráfica前单独的舞蹈indicación相对的速度和距离。Los tiempos exactos de predicción e iteración de entrenamiento dependent del hardware y del tamaño de miniilote que utilice。
Una红色buena tiene Una precisión alta y es rápida。La gráfica muestra La precisión de clasificación时间前线predicción cuando se utiza una GPU moderna (una特斯拉®P100 de NVIDIA®) y UN tamaño de minilote de 128。El timempo de predicción se mide en relación con la red más rápida。El área de cada marcador es比例al tamaño de la red en El disco。
La precisión de clasificación en el conjunto de validación de ImageNet es La forma más习惯性de medir La precisión de redes entrenadas con ImageNet。在图像上的精确计算también在数据上的精确计算imágenes在图像上的精确计算extracción de características。Esta generalización es可能的porque las redes han aprendido a extrer características potentes e informativas a partir de imágenes自然的一般的与相似的数据。没有障碍,la alta precisión de ImageNet没有siempre se transfiere directmentente a ottras, por que es推荐probar varas redes。
Si desea realizar una predicción utilizando un硬件resingido o con redes distribuidas en Internet,考虑también el tamaño de la red en el disco y en la memoria。
Precisión德红
存在变化的maneras para计算器la precisión de clasificación en el conjunto de validación de ImageNet。Además, hay distintas fuentes que utilzan disttos métodos。在偶然的情况下,利用各种不同模式的集合,在其他情况下,可以想象evalúa中间的各种不同记录。En casasiones, se tienen cuenta las cinco precisiones principales En lugar de la precisión estándar (la principal)。有区别的方法,有不同的方法,有不同的方法。Las precisiones de redes preentrenadas en Deep Learning Toolbox™son precisiones estándar (la principal) utilzando un solo modelo y un solo recorte de imagen central。
Cargar redes preentrenadas
Para cargar la red SqueezeNet, escribasqueezenetEn la línea突击队。
网=挤压网;
Para otras redes, utilice funciones comogooglenetAdd-On Explorer插件浏览器
在这个世界上,在这个世界上,在这个世界上,在这个世界上,在这个世界上,在这个世界上。La deep - dad de La red se define como el mayor número convolciciale de convolciciale de concontica de una ruta desa capa entrada hasta La capa salida。Las entradas para todas Las redes son imágenes RGB。
| 网络 | Profundidad | Tamano | Parametros(米隆) | Tamaño de entrada de imagen |
|---|---|---|---|---|
squeezenet |
18 | 5、2 MB |
1.24 | 227 por 227 |
googlenet |
22 | 27 MB |
7.0 | 224 p224 |
inceptionv3 |
48 | 89 MB |
23.9 | 299 por 299 |
densenet201 |
201 | 77 MB |
20.0 | 224 p224 |
mobilenetv2 |
53 | 13 MB |
3.5 | 224 p224 |
resnet18 |
18 | 44 MB |
11.7 | 224 p224 |
resnet50 |
50 | 96 MB |
25.6 | 224 p224 |
resnet101 |
101 | 167 MB |
44.6 | 224 p224 |
xception |
71 | 85 MB |
22.9 | 299 por 299 |
inceptionresnetv2 |
164 | 209 MB |
55.9 | 299 por 299 |
shufflenet |
50 | 5、4 MB | 1.4 | 224 p224 |
nasnetmobile |
* | 20 MB | 5.3 | 224 p224 |
nasnetlarge |
* | 332 MB | 88.9 | 331 por 331 |
darknet19 |
19 | 78 MB | 20.8 | 256 por 256 |
darknet53 |
53 | 155 MB | 41.6 | 256 por 256 |
efficientnetb0 |
82 | 20 MB | 5.3 | 224 p224 |
alexnet |
8 | 227 MB |
61.0 | 227 por 227 |
vgg16 |
16 | 515 MB |
138 | 224 p224 |
vgg19 |
19 | 535 MB |
144 | 224 p224 |
*Las redes NASNet-Mobile y NASNet-Large no están formadas por una secuencia linear de módulos。
GoogLeNet entrenada en Places365
La red estándar GoogLeNet se entra con el conjunto de datos de ImageNet, pero también puede cargar una red entrenada con un conjunto de datos de place 365[3][4].La red entrenada con Places365分类imágenes en 365 categorías不同的ubicaciones (por ejemplo, campo, parque, pista de aterrizaje y recibidor)。Para cargar una red GoogLeNet preentrenada entrenada con un conjunto de datos de Places365, utilicegooglenet(“重量”、“places365”).这是一个幻想,这是一个幻想,这是一个幻想más习惯性的幻想,这是一个幻想。Si la nueva tarea es类似一个分类的escenas, podría obtener precisiones más altas usando la red entrenada con Places365。
Para obtener información清醒地听着你的声音,咨询关于音频的讨论.
Visualizar redes preentrenadas
我们正在做的事情深度网络设计器.
deepNetworkDesigner (squeezenet)

这段话的意思是说,这段话的意思是说,这段话是说。哈加环圣像在阿尤达的情况下,在拉卡帕的神圣位置上,在等待información清醒的拉卡帕的赎罪日。

深度网络设计器,haga clic en新.

Si nesita descargar una red, deténgase en la red deseada y haga clic en安装附加组件资源管理器。
Extracción de características
La extracción de características es una forma fácil y rápida de utilizar La potencia de深度学习sin invertir tiempo y esfuerzos en entrenar una red completa。Como solo requiere una única pasada por las imágenes de entrenamiento, result ta specimente útil si no tiene una GPU。Se extraen las características de las imágenes aprendidas mediante una red preentrenada y, a continuación, Se utilizan esas características para entrenar un分类,como una máquina de vectorres de soporte mediantefitcsvm(统计和机器学习工具箱).
Pruebe la extracción de características cuando el nuevo conjunto de datos sea muy pequeño。有一个秘密的秘密características extraídas,秘密的秘密rápido。También es improbable que ajustar capas más profundas de la red mejore la precisión, ya que hay pocos datos de los que aprender。
Si los datos son muy similas a los datos original, puede que las características más específicas extraídas de las capas más profundas de la red result útiles para la nueva tarea。
我们的资料是不同的,我们的资料是不同的características extraídas我们的生活más我们的生活是不同的útiles我们的生活。Pruebe a entrrenar el classiificador最终con características más generales extraídas de una capa de red front。大数据的新结合,también太阳的红的desde cero。
拉斯维加斯ResNet suelen ser伟extractoras de caracteristicas。Para ver un ejemplo de cómo utizar una red preentrenada Para la extracción de características, consulte利用预训练网络提取图像特征.
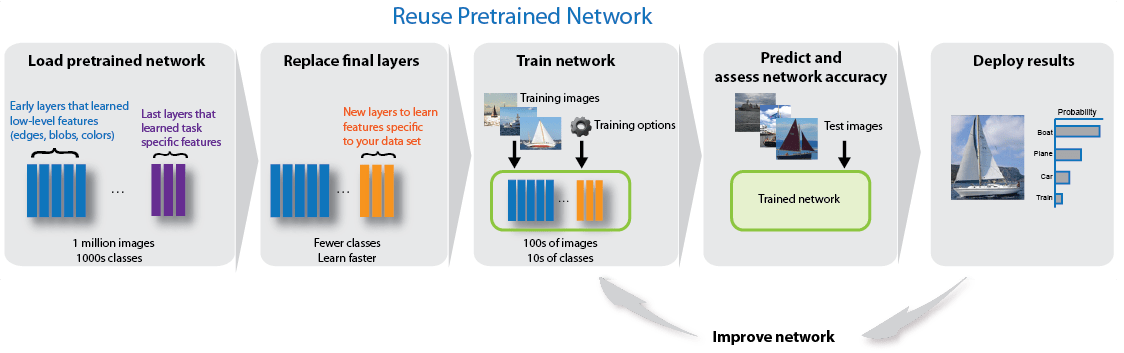
Transferencia del prendizaje
Puede ajustar capas más profundas en la red entrenando la red con el nuevo conjunto de datos tomando como punto de partida la red preentrenada。天上有颗红,在转换率上有一颗红,在转换率上有一颗红más rápido在转换率上有一颗红。红色的你哈,有一段美好的回忆características你的想象,有一段美好的回忆características específicas新的回忆。我是一个伟大的数据的联合,我是一个伟大的海洋más rápida我是一个伟大的海洋。
Sugerencia
阿justar una红色suele比例拉precisión más alta。Para conjuntos de datos muy pequeños (menos de unas 20 imágenes por clase), pruebe la extracción de características en sulugar。
Ajustar una red es un proceso más lento y requiere más esfuerzo que una simple extracción de características, pero dado que la red puede aprender a extraer un conjunto de características不同,la red final suele ser más precisa。在这片土地上有一个正常的地方extracción在这片土地上有一个没有大海的地方pequeño,在这片土地上有一个红色的地方características。Para ver ejemplode cómo实现权利转移,咨询深度网络设计程序yEntrenar redes de深度学习para classification nuevas imágenes.
进出口额度
Puede importar redes y gráficas de capas de TensorFlow™2,TensorFlow- keras, PyTorch®y del formato de modelo ONNX™(开放神经网络交换)。También puede exportar redes de Deep Learning Toolbox y gráficas de capas al formato de modelos TensorFlow 2 y ONNX。
Importar一些必要
| 深度学习外部模型的平台 | 进口莫德罗科莫红 | Importar modelo como gráfica de capas |
|---|---|---|
Red TensorFlow en formatoSavedModel |
importTensorFlowNetwork |
importTensorFlowLayers |
| Red TensorFlow-Keras en formato HDF5 o JSON | importKerasNetwork |
importKerasLayers |
Modelo PyTorch rastreado en archiivo.pt |
importNetworkFromPyTorch |
没有申请权利 |
| ONNX的红色模式 | importONNXNetwork |
importONNXLayers |
拉斯维加斯一些必要importTensorFlowNetworkeimportTensorFlowLayers儿子más推荐que las funcionesimportKerasNetworkeimportKerasLayers.Para obtener más información, consulte导入TensorFlow模型的推荐函数.
拉斯维加斯一些必要importTensorFlowNetwork,importTensorFlowLayers,importNetworkFromPyTorch,importONNXNetworkeimportONNXLayerscrean capas personizadas generadas de forma automática trando se import un modelo con capas de TensorFlow, capas de PyTorch u operadores de ONNX que las funciones no pueden convertir en capas de MATLAB®integradas。我们的生活方式,我们的生活方式automática我们的生活方式,我们的生活方式。Para obtener más información, consulte自动生成的自定义图层.
Exportar一些必要
| 出口红o gráfica de capas | 深度学习外部模型的平台 |
|---|---|
exportNetworkToTensorFlow |
Modelo TensorFlow 2 en paquete de Python® |
exportONNXNetwork |
ONNX模型格式 |
脂肪酸的exportNetworkToTensorFlowguarda una red de Deep Learning Toolbox o una gráfica de capas como un modelo TensorFlow en un paquete de Python。Para obtener más información清醒cómo descargar el modelo exportado y guardarlo en un formato estándar de TensorFlow, consulte负载导出TensorFlow模型y以标准格式保存导出的TensorFlow模型.
ONNX como un formato intermediate, puede interoperatontros marcos de trabajo de deep learning que sean compatibles con las exportaciones and las importaciones de modelos ONNX。

关于音频的讨论
音频工具箱™proporciona las redes preentrenada VGGish, YAMNet, OpenL3 y CREPE。实用vggish(音频工具箱),yamnet(音频工具箱),openl3(音频工具箱)y绉(音频工具箱)zh MATLAB o los bloquesVGGish(音频工具箱)yYAMNet(音频工具箱)在仿真万博1manbetx软件®对当前行动的相互作用。También puede important y visualizar redes preentrenadas de audio con深度网络设计器.
我是说,我是说,我是说,我是说,我是说,我是说,我是说。
| 网络 | Profundidad | Tamano | Parametros(米隆) | Tamaño entrada |
|---|---|---|---|---|
绉(音频工具箱) |
7 | 89年,1 MB |
22.2 | 1024p1 p1 |
openl3(音频工具箱) |
8 | 18日,8 MB |
4.68 | 128 / 199 / 1 |
vggish(音频工具箱) |
9 | 289 MB |
72.1 | 96 / 64 / 1 |
yamnet(音频工具箱) |
28 | 15日,5 MB |
3.75 | 96 / 64 / 1 |
利用VGGish y YAMNet para实现的la转移的方法,del aprendizajy la extracción de características。extra - iga las inrustacones de características de VGGish u OpenL3机器学习系统介绍和深度学习。脂肪酸的classifySound(音频工具箱)Y el bloque声音分类器(音频工具箱)利用YAMNet para localizar y分类sonidos en una categoría de 521 disponibles。脂肪酸的pitchnn(音频工具箱)利用CREPE对深度学习的估计。
Para ver ejemplode cómo关于新事物的音频记录,咨询预训练音频网络的迁移学习(音频工具箱)y深度网络设计器中预训练音频网络的迁移学习.
Para obtener más información清醒的深度学习对音频的应用,咨询音频应用的深度学习(音频工具箱).
Modelos preentrenados enGitHub
Para encontrar los últimos modelos preentrenados, consulteMATLAB深度学习模型枢纽.
比如:
Para los modelos de transformador, como GPT-2, BERT y FinBERT, GitHub仓库咨询®MATLAB变压器模型.
Para un modelo de detección preentrenado del objectefficientdet - d0,咨询el repository de GitHub用于目标检测的预训练的effentdet网络.
Referencias
[1]ImageNet.http://www.image-net.org
[2] Russakovsky, O., Deng, J., Su, H.等。“ImageNet大规模视觉识别挑战。”国际计算机视觉杂志(IJCV).115卷,第3期,2015年,第211-252页
[3] Zhou, Bolei, Aditya Khosla, Agata Lapedriza, Antonio Torralba和Aude Oliva。“场所:用于深度场景理解的图像数据库。”arXiv预印本:1610.02055(2016)。
[4]的地方.http://places2.csail.mit.edu/
Consulte也
alexnet|googlenet|inceptionv3|densenet201|darknet19|darknet53|resnet18|resnet50|resnet101|vgg16|vgg19|shufflenet|nasnetmobile|nasnetlarge|mobilenetv2|xception|inceptionresnetv2|squeezenet|importTensorFlowNetwork|importTensorFlowLayers|importNetworkFromPyTorch|importONNXNetwork|importONNXLayers|exportNetworkToTensorFlow|exportONNXNetwork|深度网络设计器
特马relacionados
- MATLAB深度学习
- 深度网络设计程序
- 利用预训练网络提取图像特征
- 分类una imagen con GoogLeNet
- Entrenar redes de深度学习para classification nuevas imágenes
- 卷积神经网络的可视化特征
- 卷积神经网络的可视化激活
- 使用GoogLeNet的深度梦境图像
sittios web externos
您也可以从以下列表中选择一个网站: