语义分割网络的代码生成
这个例子展示了一个使用深度学习的图像分割应用程序的代码生成。它使用codegen命令生成MEX函数,该函数对用于SegNet[1]的DAG网络对象进行预测,SegNet[1]是一个用于图像分割的深度学习网络。
第三方的先决条件
要求
本例生成CUDA MEX,并具有以下第三方需求。
CUDA®支持NVIDIA®GPU和兼容的驱动程序。
可选
对于非mex构建,如静态、动态库或可执行程序,此示例具有以下附加要求。
英伟达工具包。
NVIDIA cuDNN库。
编译器和库的环境变量。有关更多信息,请参见第三方硬件而且设置必备产品s manbetx 845.
验证GPU环境
使用coder.checkGpuInstall函数来验证运行此示例所需的编译器和库是否已正确设置。
envCfg = code . gpuenvconfig (“主机”);envCfg。DeepLibTarget =“cudnn”;envCfg。DeepCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
分割网络
SegNet[1]是一种用于语义图像分割的卷积神经网络(CNN)。它是一个在CamVid[2]数据集上训练的深度编码器-解码器多类像素分割网络,并导入MATLAB®进行推理。SegNet[1]被训练为属于11类的像素,包括天空,建筑,极点,道路,人行道,树,标志符号,栅栏,汽车,行人和自行车。
有关使用CamVid[2]数据集在MATLAB中训练语义分割网络的信息,请参见基于深度学习的语义分割(计算机视觉工具箱).
的segnet_predict入口点函数
的segnet_predict.m入口点函数接受一个图像输入,并使用保存在SegNet.mat文件。对象加载网络对象SegNet.mat文件到一个持久变量mynet并在后续的预测调用中重用持久变量。
类型(“segnet_predict.m”)
The MathWorks, Inc. persistent mynet;if isempty(mynet) mynet = code . loaddeeplearningnetwork ('SegNet.mat');End %传入输入输出= predict(mynet,in);
获取预训练的SegNet DAG网络对象
net = getSegNet();
DAG网络包含91层,包括卷积、批处理归一化、池化、解池化和像素分类输出层。使用analyzeNetwork(深度学习工具箱)功能显示深度学习网络架构的交互式可视化。
analyzeNetwork(净);
运行MEX代码生成
生成CUDA代码segnet_predict.m入口点函数,为MEX目标创建一个GPU代码配置对象,并将目标语言设置为c++。使用编码器。DeepLearningConfig函数来创建CuDNN的深度学习配置对象,并将其分配给DeepLearningConfig属性的图形处理器代码配置对象。运行codegen指定输入大小为[360,480,3]的命令。的输入层大小对应SegNet.
cfg = code .gpu config (墨西哥人的);cfg。TargetLang =“c++”;cfg。DeepLearningConfig =编码器。DeepLearningConfig (“cudnn”);codegen配置cfgsegnet_predictarg游戏{(360480 3 uint8)}报告
代码生成成功:查看报告
运行生成的MEX
加载并显示输入图像。调用segnet_predict_mex在输入图像上。
我的意思是:“gpucoder_segnet_image.png”);imshow (im);

Predict_scores = segnet_predict_mex(im);
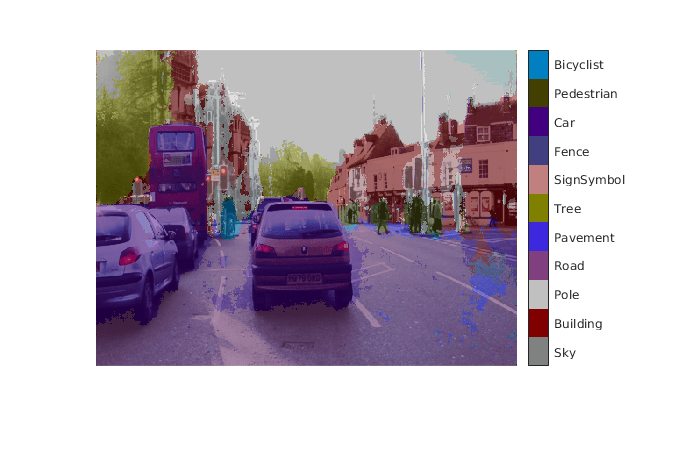
的predict_scoresVariable是一个三维矩阵,它有11个通道,对应于每个类的像素级预测分数。通过使用最大预测分数来计算通道以获得按像素划分的标签。
[~,argmax] = max(predict_scores,[],3);
将分割后的标签覆盖在输入图像上,显示分割后的区域。
Classes = [“天空”“建筑”“极”“路”“路面”“树”“SignSymbol”“篱笆”“汽车”“行人”“自行车”];cmap = camvidColorMap();SegmentedImage = labeloverlay(im,argmax,“ColorMap”,提出);图imshow (SegmentedImage);pixelLabelColorbar(提出、类);
参考文献
Badrinarayanan, Vijay, Alex Kendall和Roberto Cipolla。SegNet:一种用于图像分割的深度卷积编码器-解码器架构。arXiv预打印:1511.00561,2015.
[2]布罗斯托,加布里埃尔·J.,朱利安·福克尔,罗伯托·西波拉。“视频中的语义对象类:一个高清地面真相数据库。”模式识别信2009年第2期第30卷第88-97页。
另请参阅
功能
对象
相关的例子
- 基于深度学习的语义分割(计算机视觉工具箱)
- 基于NVIDIA DRIVE的语义分割(针对NVIDIA Jets万博1manbetxon和NVIDIA DRIVE平台的MATLAB编码器支持包)
- 训练和部署用于语义分割的全卷积网络
- 基于U-net的语义分割网络代码生成
更多关于
- 开始使用深度学习进行语义分割(计算机视觉工具箱)
您也可以从以下列表中选择网站: