磁流变液阻尼器的非线性建模
该算例显示了磁流变液阻尼器动态行为的非线性黑箱模型。它展示了如何通过测量其速度和阻尼力来创建阻尼器的非线性ARX和Hammerstein-Wiener模型。
本例中使用的数据是由Akira Sano博士(日本庆应大学)和王建东博士(中国北京大学)提供的,他们在庆应大学的一个实验室进行了实验。关于实验系统和一些相关研究的详细描述,请参阅下面的参考资料。
王俊杰,佐野a,陈涛,黄斌。无非线性显式参数化的Hammerstein系统的辨识。国际控制杂志,出版,2008。DOI: 10.1080 / 00207170802382376。
实验装置
磁流变液阻尼器是一种半主动控制装置,用于降低各种动力结构的振动。磁流变液的粘度取决于设备的输入电压/电流,它提供可控的阻尼力。
为了研究这些装置的行为,MR阻尼器一端固定在地面上,另一端连接到产生振动的激振台。设置阻尼器电压为1.25 v,每隔0.005 s采样一次阻尼力f(t)。每0.001 s采样一次位移,然后在0.005 s采样周期内用位移估计速度v(t)。
输入输出数据
包含输入和输出测量值的数据集存储在一个名为mrdamper.mat的MAT文件中。输入v(t)为阻尼器的速度[cm/s],输出f(t)为阻尼力[N]。MAT文件包含3499个数据样本,对应0.005 s的采样率。该数据将用于本例中执行的所有估计和验证任务。
让我们从装载和检查数据开始。负载(fullfile (matlabroot“工具箱”,“识别”,“iddemos”,“数据”,“mrdamper.mat”));谁
变量是F Ts V
将加载的变量F(输出力),V(输入速度)和Ts(采样时间)打包到IDDATA对象中。
z = iddata(F, V, t,“名字”,MR阻尼器的,...“InputName”,“v”,“OutputName”,“f”,...“InputUnit”,“cm / s”,“OutputUnit”,“N”);
评估和验证的数据准备
将这个数据集z分成两个子集,第一个2000个样本用于估计(ze),其余的用于结果验证(zv)。
泽= z (1:20 00);%估计数据zv z =(2001:结束);%验证数据
让我们把两组数据放在一起,以直观地验证它们的时间范围:
情节(泽,zv)传说(“泽”,“zv”)

模型顺序选择
估计黑盒模型的第一步是选择模型顺序。订单的定义取决于模型的类型。
对于线性和非线性ARX模型,阶数由三个数字表示:na, nb和nk,它们定义了过去的输出数,过去的输入数和用于预测给定时间的输出值的输入延迟数。由顺序定义的时滞I/O变量集称为“回归器”。要获得创建回归器的更多灵活性,可以使用回归器规范对象(请参阅线性回归器、多项式回归器、customregression)。
对于Hammerstein-Wiener模型,它表示带有静态I/O非线性的线性模型,阶数定义了线性分量的极点和零点的数目以及输入延迟。它们由数字nb(零点数+1)、nf(极点数)和nk(滞后数中的输入延迟)定义。
典型的模型顺序是通过试错来选择的。然而,线性ARX模型的阶数可以使用以下函数自动计算arxstruc和selstruc.由此得到的阶数也提示了非线性模型可能使用的阶数。让我们先试着确定线性ARX模型的最佳顺序。
V = arxstruc(ze,zv,struc(1:5, 1:5,1:5));对于na, nb, nk, % try值在1:5范围内订单= selstruc (V,“另类投资会议”)%根据赤池的信息准则选择订单
1 .单词conduct联想记忆
AIC准则选择Order = [na nb nk] =[2 4 1],即在选定的ARX模型结构中,阻尼力f(t)由6个回归因子f(t-1)、f(t-2)、v(t-1)、v(t-2)、v(t-3)和v(t-4)预测。
有关模型顺序选择的更多信息,请参见题为“模型结构选择:确定模型顺序和输入延迟”的示例。
初步分析:创建线性模型
建议首先尝试线性模型,因为它们更容易创建。如果线性模型不能提供令人满意的结果,这些结果为探索非线性模型提供了基础。
让我们估计由上述SELSTRUC输出建议的订单的线性ARX和输出误差(OE)模型。
LinMod1 = arx(ze, [2 4 1]);% ARX模型Ay = Bu + eLinMod2 = oe(ze, [4 2 1]);% OE模型y = B/F u + e
同样,我们可以创建一个线性状态空间模型,其顺序(=状态数)将自动确定:
LinMod3 = ss(泽);%创建顺序为3的状态空间模型
现在让我们将这些模型的响应与ze中的实测输出数据进行比较:
比较(ze, LinMod1, LinMod2, LinMod3)%与估计数据比较
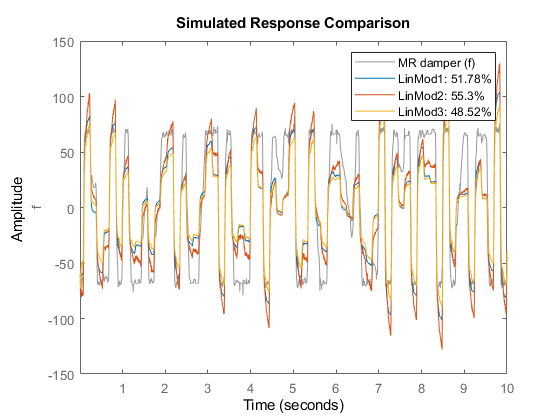
一个更好的模型质量测试是通过一个独立的数据集来验证它。因此,我们比较模型响应与数据集zv。
比较(zv, LinMod1, LinMod2, LinMod3)与验证数据的比较
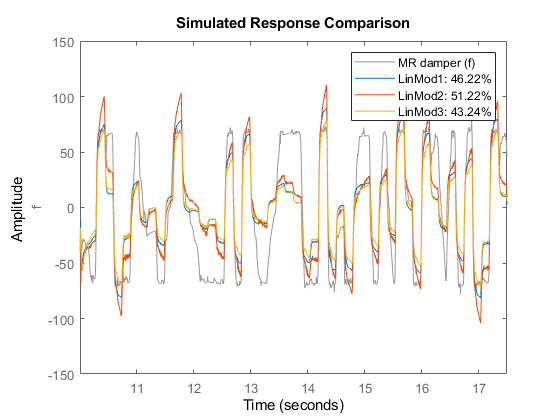
正如所观察到的,这些最好的线性模型对验证数据集的拟合率为51%。
建立非线性ARX模型
线性模型识别表明,ARX模型对验证数据的拟合小于50%。为了取得更好的结果,我们现在探索使用非线性ARX (IDNLARX)模型。该方法还建议对这些数据建立非线性模型建议实用程序,可用于检查数据,以确定使用非线性模型比线性模型的潜在优势。
建议(泽,“非线性”)
数据中有非线性的迹象。一个[4 4 1]阶的非线性ARX模型和idTreePartition函数比对应的同阶ARX模型的输出预测效果更好。考虑使用非线性模型,如IDNLARX或IDNLHW。您也可以使用“isnlarx”命令来测试更多选项的非线性。
非线性ARX模型可以被认为是ARX模型的非线性副本,通过两种方式提供更大的建模灵活性:
回归量可以使用非线性函数而不是ARX模型所采用的加权和进行组合。非线性函数如s形网络、二叉树和小波网络可以被使用。在辨识方面,这些函数称为“非线性映射函数”。
回归器本身可以是I/O变量的任意(可能是非线性)函数,以及ARX模型所采用的时滞变量值。
为非线性ARX模型创建回归器
当具有连续滞后的线性时,回归器最容易使用顺序矩阵[na nb nk]创建,如上所述。在具有任意滞后的最一般的回归量的情况下,或当回归量是基于变量的绝对值时,使用linearRegressor对象提供了更多的灵活性。如果回归器是时滞变量的多项式,则可以使用polynomialRegressor对象。对于使用任意用户指定公式的回归器,customRegressor对象可以被使用。
我们将探索使用各种模型阶数和使用各种非线性映射函数。没有探索多项式或自定义回归器的使用。有关在IDNLARX模型中指定自定义回归器的方法,请参阅标题为“用非线性和自定义回归器构建非线性ARX模型”的示例。
估计一个默认的非线性ARX模型
首先,我们估计一个[2 4 1]阶的IDNLARX模型和一个s形网络作为非线性类型。我们将使用MaxIterations = 50和Levenberg-Marquardt搜索方法作为下面所有估计的估计选项。
选择= nlarxOptions (“SearchMethod”,“lm”);Options.SearchOptions.MaxIterations = 50;Narx1 = nlarx(ze, [2 4 1], idSigmoidNetwork, Options)
Inputs: v Outputs: f regression: variable f, v Linear regression output function: Sigmoid network with 10 units Sample time: 0.005 seconds Status: using NLARX on time domain data“MR damping”拟合估计数据:95.8%(预测焦点)FPE: 6.648, MSE: 6.08
nlarx是用于估计非线性ARX模型的命令。Narx1是一个非线性ARX模型,具有回归量R:= [f(t-1), f(t-2), v(t-1),…v(第四节)]。非线性是一个Sigmoid网络,它使用一个Sigmoid单位函数和线性加权回归量和来计算输出。映射函数存储在OutputFcn模型的属性。
disp (Narx1.OutputFcn)
Sigmoid Network Input: f(t-1), f(t-2), v(t-1), v(t-2), v(t-3), v(t-4) Output: f Nonlinear Function: Sigmoid Network with 10 units Linear Function: initialized to [48.3 -3.38 -3.34 -2.7 -1.38 2.15] Output Offset: initialized to -18.9 Input: '' Output: ' ' LinearFcn:'<线性函数参数>'非线性fcn: ' '偏移:'<偏移参数>'
通过比较模拟输出与估计和验证的数据集ze和zv来检验模型质量:
比较(泽Narx1);%与估计数据比较
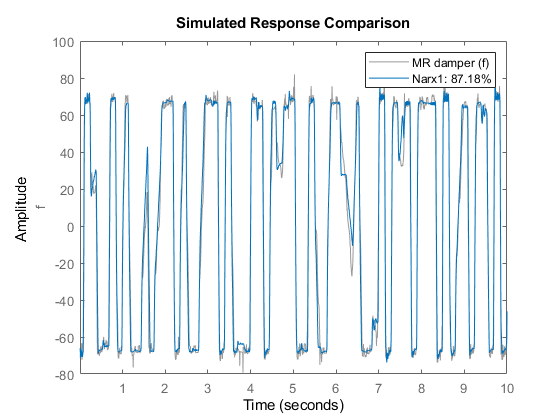
比较(zv Narx1);与验证数据的比较

尝试各种模型订单
与相同阶的线性模型相比,我们看到了更好的拟合。接下来,我们可以尝试SELSTRUC建议的附近的其他订单。
问= idSigmoidNetwork;Narx2{1} = nlarx(ze, [3 4 1], NL, Options);%使用na = 3, nb = 4, nk = 1。Narx2{1}。Name =“Narx2_1”;Narx2{2} = nlarx(ze, [2 5 1], NL, Options);Narx2{2}。Name =“Narx2_2”;Narx2{3} = nlarx(ze, [3 5 1], NL, Options);Narx2{3}。Name =“Narx2_3”;Narx2{4} = nlarx(ze, [1 4 1], NL, Options);Narx2{4}。Name =“Narx2_4”;Narx2{5} = nlarx(ze, [2 3 1], NL, Options);Narx2{5}。Name =“Narx2_5”;Narx2{6} = nlarx(ze, [1 3 1], NL, Options);Narx2{6}。Name =“Narx2_6”;
评估这些模型在估计和验证数据集上的性能:
比较(泽、Narx1 Narx2 {:});%与估计数据比较
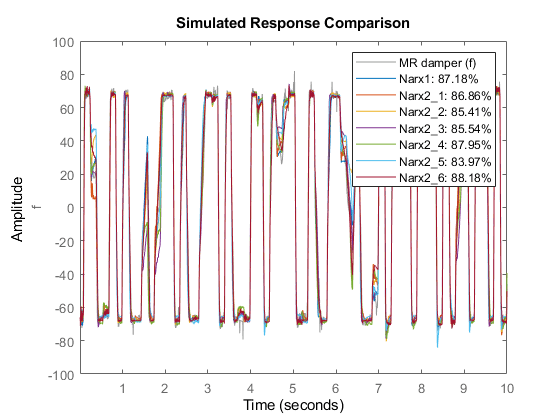
比较(zv、Narx1 Narx2 {:});与验证数据的比较

Narx2{6}模型似乎对估计数据集和验证数据集都提供了良好的拟合,但其阶数小于Narx1。基于此观察,我们将[1 3 1]作为后续试验的顺序,保留Nlarx2{6}进行拟合比较。这个顺序的选择对应于使用[f(t-1), v(t-1), v(t-2), v(t-3)]作为回归器集合。
指定Sigmoid网络函数的单位数
接下来,让我们探讨Sigmoid Network函数的结构。这个估计量最相关的性质是它使用的s形单位数。创建一个使用12个s型单位的。
Sig = idSigmoidNetwork (12);%创建一个使用12个单元的网络Narx3 = nlarx(ze, [1 3 1], Sig, Options);
在估计和验证数据集上,我们将该模型与Narx1和Narx2{6}进行比较:
比较(ze, Narx3, Narx1, Narx2{6});%与估计数据比较
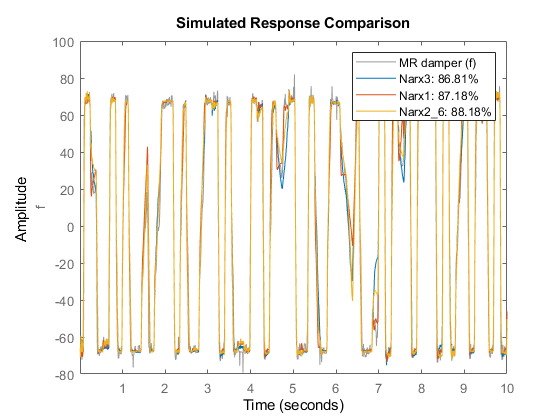
比较(zv, Narx3, Narx1, Narx2{6});与验证数据的比较

新型号Narx3并不比Narx2{6}更适合。因此,我们在随后的试验中保留了10个单元。
非线性映射函数回归子集的选择
一般情况下,非线性函数(s形网络)使用所选阶(此处为[1 3 1])定义的所有回归器。如果回归器的数量很大,这可能会增加模型的复杂性。可以在不修改模型顺序的情况下,选择一个回归器子集供s形网络的组成部分使用。这可以通过称为“RegressorUsage”的属性来实现。它的值是一个表,该表指定哪些组件使用哪些回归器。例如,我们可以只使用由输入变量所贡献的回归量,这些变量将由s型函数的非线性分量所使用。这可以通过以下方式实现:
Sig = idSigmoidNetwork (10);NarxInit = idnlarx(泽。OutputName,泽。InputName, [1 3 1], Sig);NarxInit.RegressorUsage。(“f: NonlinearFcn”) (1) = false;disp(NarxInit. regressorusage) Narx4 = nlarx(ze, NarxInit, Options);
f: LinearFcn f: NonlinearFcn ___________ ______________ f (t - 1)真的假的v (t - 1)真的真的v(2)真的真的v(条t - 3)真的真的
这导致回归量v(t-1), v(t-2)和v(t-3)被s型单位函数使用。没有使用基于回归器的输出变量f(t-1)。注意,idSigmoidNetwork函数还包含一个由所有回归量的加权和表示的线性项。线性项使用完整的回归器集。
创建另一个模型,使用回归器{y1(t-1), u1(t-2), u1(t-3)}作为其非线性成分。
使用= false (4,1);使用([1 3 4])= true;NarxInit。RegressorUsage{: 2} =使用;Narx5 = nlarx(ze, NarxInit, Options);
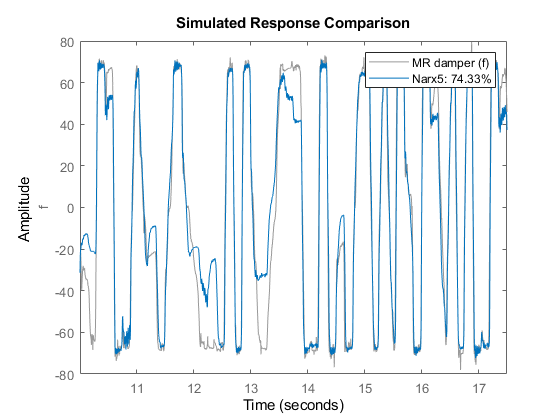
Narx5模型似乎在估计和验证数据集上都表现得很好。
比较(泽Narx5);%与估计数据比较

比较(zv Narx5);与验证数据的比较
尝试各种非线性映射函数
到目前为止,我们已经探索了各种模型的阶数,在Sigmoid网络函数中使用的单元数,以及由Sigmoid网络的非线性分量使用的回归子子集的规格。接下来,我们尝试使用其他类型的非线性函数。
使用具有默认属性的小波网络函数。像s形网络一样,小波网络通过线性分量和非线性分量的和将回归器映射到输出;非线性分量使用小波和。
NarxInit = idnlarx(泽。OutputName,泽。InputName, [1 3 1], idWaveletNetwork);%只对网络的非线性分量使用回归器1和3NarxInit.RegressorUsage。(“f: NonlinearFcn”)([2 4]) = false;Narx6 = nlarx(ze, NarxInit, Options);
使用20个单位的树划分非线性函数:
TreeNet = idTreePartition;TreeNet.NonlinearFcn.NumberOfUnits = 20;NarxInit。OutputFcn= TreeNet; Narx7 = nlarx(ze, NarxInit, Options);
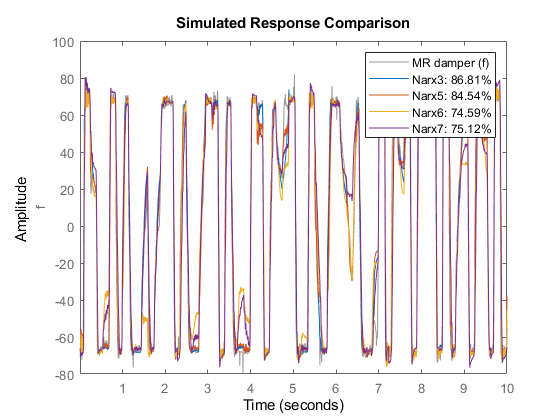
将结果与Narx3和Narx5进行比较
比较(ze, Narx3, Narx5, Narx6, Narx7)%与估计数据比较
比较(zv, Narx3, Narx5, Narx6, Narx7)与验证数据的比较
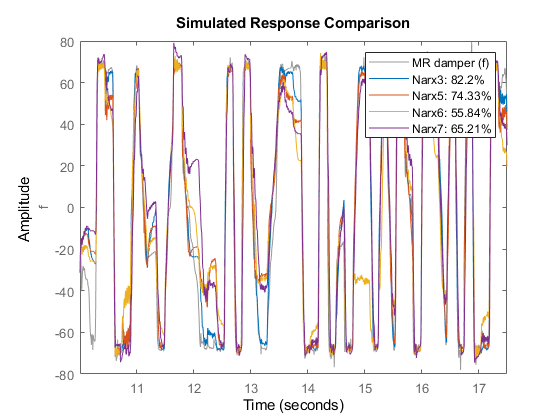
Narx6和Narx7模型的表现似乎比Narx5差,尽管我们还没有探索与它们的估计相关的所有选项(如非线性回归量的选择、单位数量和其他模型阶数)。
分析估计的IDNLARX模型
方法识别和验证模型之后比较命令,我们可以暂时选择一个提供最好的结果,而不会增加太多额外的复杂性。然后,可以使用如下命令对所选模型进行进一步分析情节和渣油.
为了深入了解模型的非线性性质,检查估计模型F(t) = F(F(t-1), F(t-2), v(t-1),…,v(t-4)中非线性函数F()的截面。例如,在模型Narx5中,函数F()是一个s形网络。要探索作为回归器函数的F()输出的形状,请在模型上使用PLOT命令:
情节(Narx5)
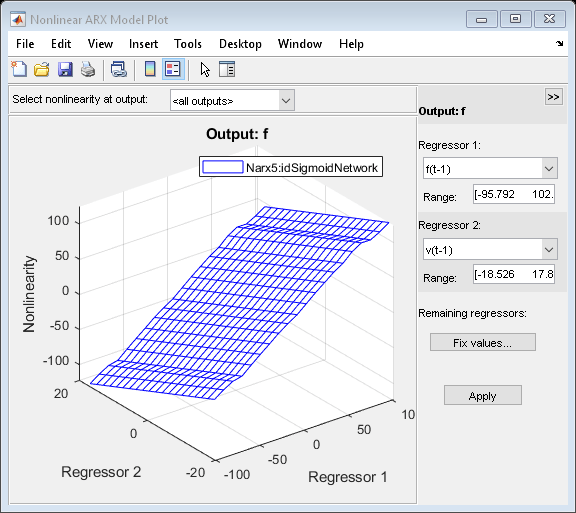
绘图窗口提供了选择横截面回归器及其范围的工具。有关更多信息,请参见“帮助idnlarx/plot”。
残差检验可用于进一步检验模型。这个测试揭示了预测误差是否为白色,是否与输入数据不相关。
集(gcf,“DefaultAxesTitleFontSizeMultiplier”,1,...“DefaultAxesTitleFontWeight”,“正常”,...“位置”,[100 100 780 520]);渣油(zv Narx3 Narx5)
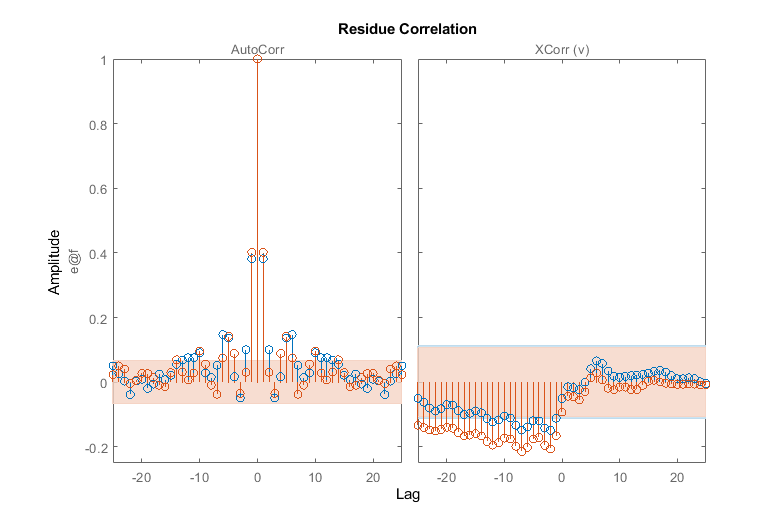
残余测试的失败可能指向模型没有捕捉到的动态。对于Narx3模型,残差似乎大多在99%置信范围内。
创建Hammerstein-Wiener模型
先前估计的非线性模型均为非线性ARX (IDNLARX)型。现在让我们试试Hammerstein-Wiener (IDNLHW)模型。这些模型表示静态非线性元素与线性模型的串联。我们可以把它们看作是线性输出误差(OE)模型的扩展,其中我们将线性模型的输入和输出信号施加于静态非线性,如饱和或死区。
估计一个与线性OE模型相同阶的IDNLHW模型
线性OE模型LinMod2采用nb = 4, nf = 2和nk = 1阶估计。让我们用同样的阶数来估计IDNLHW模型。对于输入非线性和输出非线性,我们将使用s形网络作为非线性。估计是容易的nlhw命令。它类似于oe用于线性OE模型估计的命令。然而,除了模型顺序之外,我们还必须指定I/O非线性的名称或对象。
选择= nlhwOptions (“SearchMethod”,“lm”);多人= idSigmoidNetwork;YNL = idSigmoidNetwork;Nhw1 = nlhw(ze, [4 2 1], UNL, YNL, Opt)
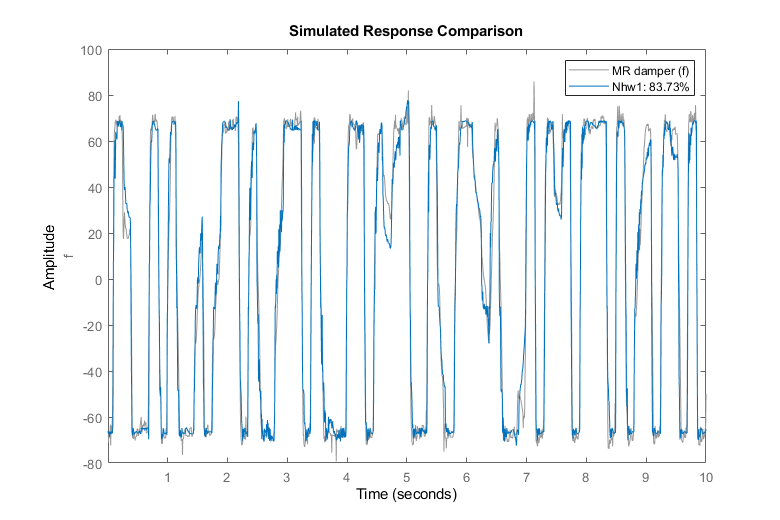
Nhw1 = Hammerstein-Wiener模型1输出和输入的线性传递函数对应订单nb = 4, nf = 2, nk = 1输入非线性:乙状结肠网络10单元输出非线性:乙状结肠网络10单元样品时间:0.005秒状态:估计使用NLHW时域数据“MR阻尼器”。拟合估计数据:83.72% FPE: 97.72, MSE: 91.2
将该模型的响应与估计和验证数据集进行比较:
clf比较(泽Nhw1);%与估计数据比较
比较(zv Nhw1);与验证数据的比较
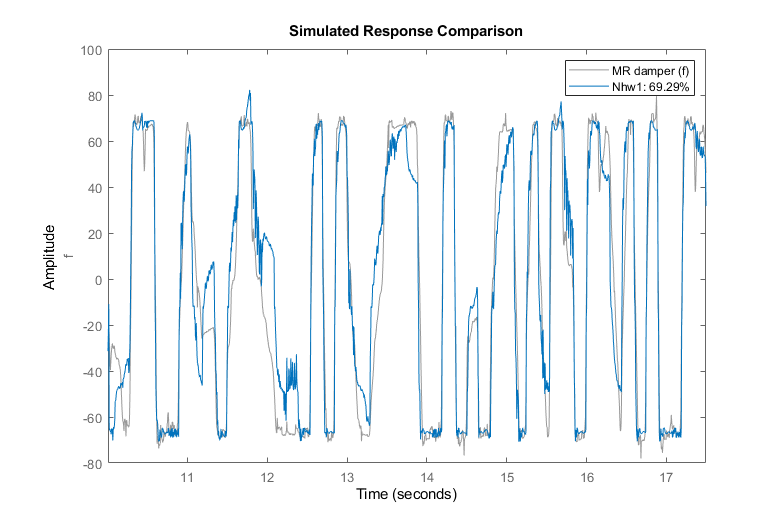
我们观察到约70%的数据符合Nhw1模型的验证数据。
分析估计的IDNLHW模型
对于非线性ARX模型,可以使用PLOT命令检查Hammerstein-Wiener模型的I/O非线性性质和线性组件的行为。要了解更多信息,请在MATLAB命令窗口中输入“help idnlhw/plot”。
情节(Nhw1)
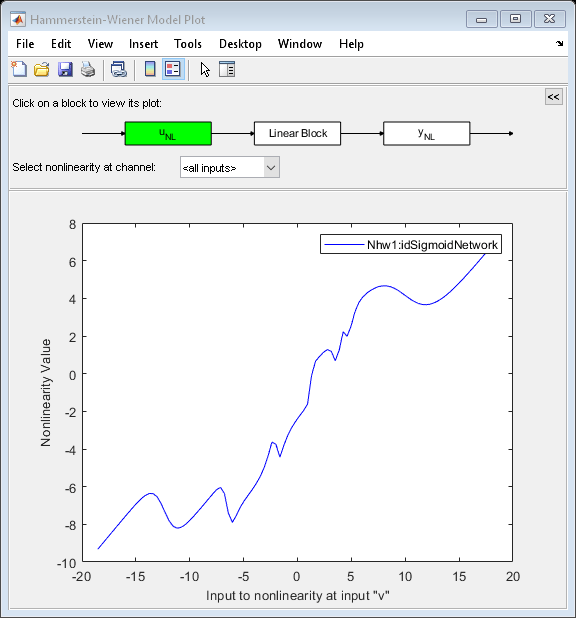
默认情况下,输入非线性被绘制出来,表明它可能是一个简单的饱和函数。
通过单击Y_NL图标,输出非线性看起来像一个分段线性函数。
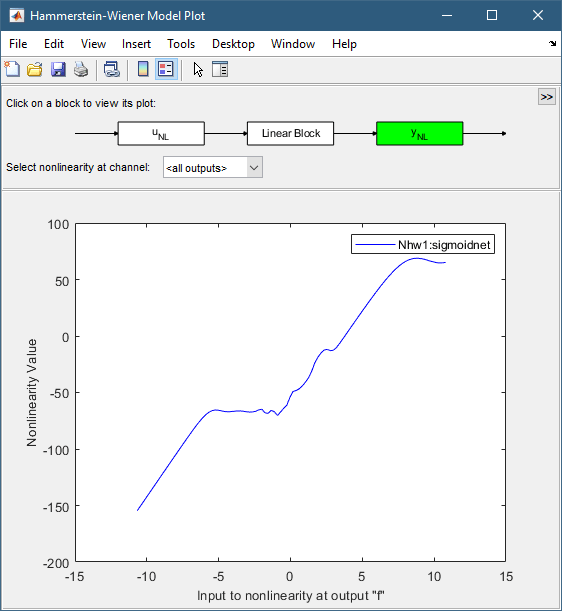
点击Linear Block图标,在下拉菜单中选择pole - zero Map,可以看到一个zero和一个pole非常接近,表示它们可以被移除,从而减少了模型的订单。

我们将使用这些信息来配置模型的结构,如下所示。
尝试各种非线性函数和模型阶数
输入非线性使用饱和,输出非线性使用s形网络,保持线性分量的阶数不变:
Nhw2 = nlhw(ze, [4 2 1], idSaturation, idSigmoidNetwork, Opt);
输出采用分段线性非线性,输入采用s形网络:
Nhw3 = nlhw(ze, [4 2 1], idSigmoidNetwork, idpiecewislinear, Opt);
使用低阶线性模型:
Nhw4 = nlhw(ze, [3 1 1], idSigmoidNetwork, idpiecewislinear, Opt);
我们也可以选择“去除”输入、输出或两者的非线性。例如,为了只使用输入非线性(这种模型称为Hammerstein模型),我们可以指定[]为输出非线性:
Nhw5 = nlhw(ze, [3 1 1],idSigmoidNetwork, [], Opt);
比较所有的模型
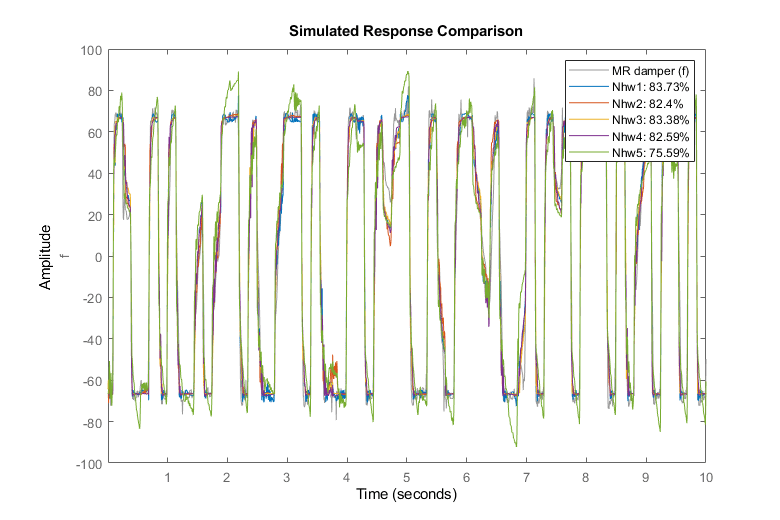
比较(ze, Nhw1, Nhw2, Nhw3, Nhw4, Nhw5)%与估计数据比较
比较(zv, Nhw1, Nhw2, Nhw3, Nhw4, Nhw5)与验证数据的比较
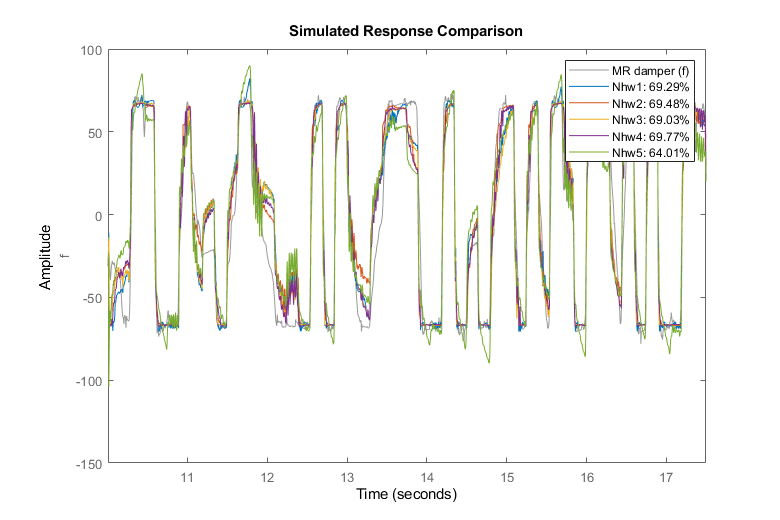
通过与验证数据的比较,Nhw1仍然是所有模型中最好的,但其他模型,除了Nhw5,具有相似的性能。
结论
我们探索了描述电压输入与阻尼力输出之间关系的各种非线性模型。结果表明,在非线性ARX模型中,Narx2{6}和Narx5表现最好,而Hammerstein-Wiener模型中Nhw1表现最好。我们还发现非线性ARX模型为描述磁流变阻尼器的动力学特性提供了最佳选择(最佳拟合)。
Narx5。Name =“Narx5”;Nhw1。Name =“Nhw1”;比较(zv, LinMod2, Narx2{6}, Narx5, Nhw1)
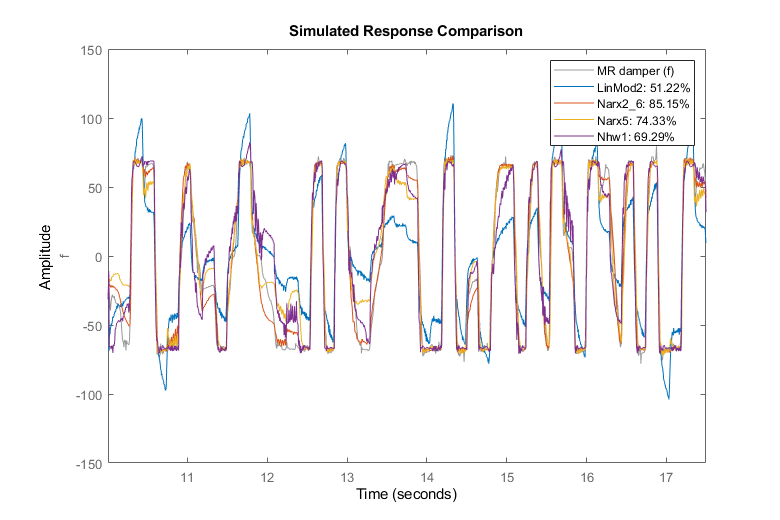
我们发现,每种模型类型都有多种选择,可以对结果的质量进行微调。对于非线性ARX模型,我们不仅可以指定模型的阶数和非线性函数的类型,还可以配置如何使用回归器和调整所选函数的性质。对于Hammerstein-Wiener模型,我们可以选择输入输出非线性函数的类型,以及线性分量的阶数。对于这两种模型类型,我们有许多可供选择的非线性函数可供我们尝试和使用。在缺乏对模型结构或基本动态知识的特殊偏好的情况下,建议尝试各种选择,并分析它们对结果模型质量的影响。
你也可以从以下列表中选择一个网站: