使用深度网络设计器创建代理和使用图像观察训练
本示例演示如何创建一个深度Q学习网络(DQN)代理,该代理可以向上摆动并平衡在MATLAB®中建模的钟摆。在本示例中,您可以使用深度网络设计器。有关DQN代理商的更多信息,请参阅深度Q网络代理。
MATLAB环境下摆锤的图像处理
用于该示例的增强学习环境是一个简单的无摩擦摆锤,其最初悬挂在向下位置。培训目标是使摆锤直立,而不会使用最小的控制工作。

对于这个环境:
向上平衡的摆锤位置是
0.弧度,下悬位置为PI.弧度。从代理到环境的扭矩作用信号为-2到2 N·m。
从环境观测得到的是简化的钟摆灰度图像和钟摆角导数。
奖励 ,每次步骤都提供了
这里:
是垂直位置的位移角。
是位移角的导数。
是上一时间步的控制效果。
有关此模型的更多信息,请参阅通过图像观察训练DDPG药剂摆动和平衡摆锤。
创建环境接口
为摆锤创建预定义的环境界面。
Env = Rlpredefinedenv(“SimplePendulumWithImage离散”);
界面有两个观察。第一次观察,命名为“pendImage”,是一个50乘50的灰度图像。
obsInfo=getObservationInfo(环境);obsInfo(1)
ans=rlNumericSpec,属性:LowerLimit:0上限:1名称:“pendImage”说明:[0x0字符串]维度:[50]数据类型:“double”
第二个观察结果叫做“angularRate”,是摆锤的角速度。
obsinfo(2)
ans=rlNumericSpec,属性:LowerLimit:-Inf上限:Inf名称:“angularRate”说明:[0x0字符串]维度:[1]数据类型:“double”
该接口具有离散动作空间,其中代理可以将五种可能的扭矩值中的一个应用于摆锤:-2,-1,0,1或2 n·m。
Actinfo = GetActionInfo(ENV)
actInfo=rlFiniteSetSpec,属性为:元素:[-2-1 0 1 2]名称:“扭矩”说明:[0x0字符串]维度:[1 1]数据类型:“双”
修复随机生成器种子以获得再现性。
rng(0)
使用深网络设计师构建批评网络
DQN代理使用临界值函数表示法来近似给定观察值和动作的长期奖励。在这种环境下,临界值是一个具有三个输入(两个观察值和一个动作)和一个输出的深度神经网络。有关创建深度神经网络值函数表示法的更多信息,请参阅创建策略和值函数表示。
您可以使用该批读网络深度网络设计器要做到这一点,你首先要为每个观察和动作创建单独的输入路径。这些路径从它们各自的输入中学习较低级别的特性。然后创建一个公共输出路径,该路径将来自输入路径的输出组合起来。
创建图像观察路径
要创建图像观察路径,请先拖动一个图像输入层从图层库窗格到画布。设置层InputSize到50,50,1用于图像观察,并设置正常化到没有一个。

第二,拖动一个convolution2DLayer将这个图层的输入和I的输出连接起来mageinputlayer..使用创建卷积层2过滤器(numfilters.具有高度和宽度的财产10.(过滤财产),并使用大步5.在水平和垂直方向(大步走财产)。

最后,用两组完成图像路径网络reLULayer和全康统计层层。第一和第二的输出尺寸全康统计层层分别为400和300。

创建所有输入路径和输出路径
以类似的方式构造其他输入路径和输出路径。
角速度路径(标量输入):
图像输入层-设置InputSize到1,1和正常化到没有一个。全康统计层-设置输出到400.。reLULayer全康统计层-设置输出到300。
操作路径(标量输入):
图像输入层-设置InputSize到1,1和正常化到没有一个。全康统计层-设置输出到300。
输出路径:
附加学者-将所有输入路径的输出连接到此层的输入。reLULayer全康统计层-设置输出到1对于标量值函数。

从深网络设计师出口网络
要将网络导出到MATLAB工作区,请在深度网络设计器点击出口。深度网络设计器将网络导出为包含网络层的新变量。可以使用此层网络变量创建批评家表示。
或者,要为网络生成等效的MATLAB代码,请单击导出>生成代码。

生成的代码如下。
lgraph=layerGraph();tempLayers=[imageInputLayer([1],“姓名”那“angularRate”那“正常化”那“没有任何”)全连接列(400,“姓名”那“dtheta_fc1”)剥离(“姓名”那“dtheta_relu1”)全连接层(300,“姓名”那“dtheta_fc2”));lgraph = addLayers (lgraph tempLayers);templayer = [imageInputLayer([1 1 1],]),“姓名”那“扭矩”那“正常化”那“没有任何”)全连接层(300,“姓名”那“torque_fc1”)];lgraph=addLayers(lgraph,tempLayers);tempLayers=[imageInputLayer([50 1],“姓名”那“pendImage”那“正常化”那“没有任何”10) convolution2dLayer ([10], 2,“姓名”那“img_conv1”那“填充”那“相同的”那“跨步”,[5])reluLayer(“姓名”那“relu_1”)全连接列(400,“姓名”那“评论家西塔fc1”)剥离(“姓名”那“theta_relu1”)全连接层(300,“姓名”那“评论家西塔fc2”));lgraph = addLayers (lgraph tempLayers);tempLayers =[添加图层(3,“姓名”那“添加”)剥离(“姓名”那“relu_2”)完全连接层(1,“姓名”那“stateValue”)];lgraph=addLayers(lgraph,tempLayers);lgraph=connectLayers(lgraph,“torque_fc1”那“添加/ IN3”);Lgraph = ConnectLayers(LAPHAGE,“评论家西塔fc2”那“加法/ In1”);Lgraph = ConnectLayers(LAPHAGE,“dtheta_fc2”那“加法/ In2”);
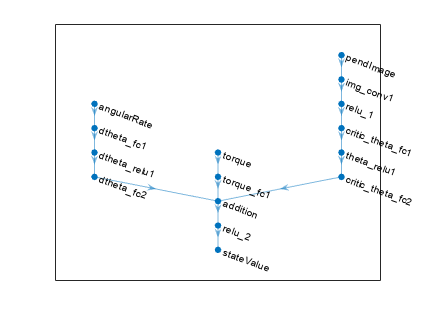
查看批评批评网络配置。
图绘制(lgraph)
指定使用批评者的选项rlrepresentationOptions.。
批评= rlrepresentationOptions('学习',1e-03,'gradientthreshold',1);
使用指定的深度神经网络创建批评家表示lgraph和选择。您还必须指定从环境界面获取的批评者的操作和观察信息。有关更多信息,请参阅rlQValueRepresentation。
评论家= rlqvaluerepresentation(第一个,obsinfo,Actinfo,...“观察”,{“pendImage”那'Angularrate'},“行动”,{“扭矩”},批评);
要创建DQN代理,请首先使用指定DQN代理选项rldqnagentoptions.。
Agentopts = RLDQNAGENTOPTIONS(...'unmorblebledqn',错误的,...'targetupdatemethod'那“平滑”那...'targetsmoothfactor',1e-3,...'经验BufferLength',1e6,...'贴花因子',0.99,...“采样时间”,env.ts,...“MiniBatchSize”,64);agentOpts.epsilongreedexploration.EpsilonDecay=1e-5;
然后,使用指定的批评批准表示和代理选项创建DQN代理。有关更多信息,请参阅rldqnagent.。
代理= rldqnagent(批评者,代理商);
火车代理
要培训代理,首先指定培训选项。
每次训练最多5000集,每次训练最多500个时间步。
在“事件管理器”对话框中显示培训进度(设置
阴谋选项)并禁用命令行显示(设置verb选项错误的)。当代理在默认的连续五次事件的窗口长度上获得大于-1000的平均累积奖励时,停止训练。在这一点上,代理可以快速平衡摆在直立的位置,使用最小的控制努力。
有关更多信息,请参阅rltringOptions.。
训练= rltrainingOptions(...“最大集”,5000,...“MaxStepsPerEpisode”,500,...“冗长”,错误的,...'plots'那“培训进度”那...'stoptrinaincriteria'那“平均向上”那...'stoptriningvalue',-1000);
在训练或模拟过程中,可以使用阴谋功能。
情节(env)
训练代理人使用火车函数。这是一个计算密集型过程,需要几个小时才能完成。要在运行此示例时节省时间,请通过设置用圆形到错误的。训练代理人,套装用圆形到真的。
dotraining = false;如果用圆形%培训代理人。trainingStats=列车(代理人、环境、列车员);别的%为示例加载预训练代理。装载('matlabpendimagedqn.mat'那“代理人”);结尾

模拟DQN代理
要验证培训的代理的性能,请在摆内环境中模拟它。有关代理模拟的更多信息,请参阅rlSimulationOptions和SIM。
simOptions = rlSimulationOptions (“MaxSteps”,500);体验= SIM(ENV,Agent,SimOptions);
totalReward=总和(经验奖励)
TotalReward = -888.9802.
也可以看看
相关话题
您还可以从以下列表中选择一个网站: