生成拟随机数字
拟随机序列
拟随机数字生成器(QRNGs)产生高度均匀的单位超立方体样本。QRNGs最小化差异生成点的分布与超立方体的均匀划分的每个子立方体中点比例相等的分布之间的分布。因此,QRNGs系统地填补了生成的拟随机序列的任何初始段中的“空穴”。
与中描述的伪随机序列不同常见的伪随机数产生方法,准随机序列失败的随机性许多统计检验。逼近真实的随机性,但是,是不是他们的目标。准随机序列谋求均匀地填充空间,并且以这样的方式,初始段近似这种行为最多的特定密度这样做。
QRNG应用程序包括:
准蒙特卡洛(QMC)积分。蒙特卡洛技术经常使用没有封闭形式解来评价困难,多维积分。QMC采用准随机序列,以提高这些技术的收敛性。
空间实验的设计。在许多实验设置中,在每个因素设置中进行测量是昂贵的或不可行的。拟随机序列提供了设计空间的有效的、均匀的采样。
全局优化。优化算法通常在一个初值的邻域内找到一个局部最优值。利用拟随机的初值序列,对所有局部极小值的吸引域进行均匀采样,寻找全局最优值。
例子:使用争夺,跳跃,跳跃
假设有一个简单的1- d序列,它产生从1到10的整数。这是基本的顺序,前三个点是(1、2、3):
![]()
现在看看如何争夺,跳过,飞跃协同工作:
争夺- 扰洗牌中的几种不同的方式一个点。在这个例子中,假定加扰接通序列插入1、3、5、7、9,2,4,6,8,10。前三点是现在(1、3、5):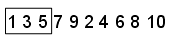
跳过——一个跳过值指定要忽略的初始点的数目。在本例中,设置跳过值为2。序列是5、7、9、2、4、6、8、10前三点是(5、7、9):
飞跃——一个飞跃值指定的点数为忽略你把每一个。继续与该示例跳过设为2,如果设置飞跃到1,序列使用了每一个点。在本例中,序列是now5、9、4、8前三点是[5 9 4]: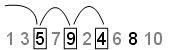

拟随机点集
统计和机器学习工具箱™函数支持以下准随机序列:万博1manbetx
拟随机序列是从正整数到单位超立方体的函数。为了在应用中有用,首字母点集必须生成一个序列。点集是有大小的矩阵n——- - - - - -d,在那里n点数是多少d是被采样的超立方体的维数。的函数haltonset和sobolset构造点集与指定的准随机序列的性能。所述点集的初始段通过将所生成的净的方法haltonset和sobolset类,但是点可以使用括号索引更普遍地生成和访问。
由于拟随机序列产生的方式,它们可能包含不希望看到的相关性,特别是在它们的初始片段中,特别是在高维空间中。为了解决这个问题,拟随机点集经常出现跳过,飞跃结束了,或争夺序列中的值。的haltonset和sobolset函数允许您同时指定a跳过和飞跃拟随机序列的性质,以及争夺的方法haltonset和sobolset类允许您应用各种打乱技术。置乱减少了相关性,同时提高了均匀性。
生成一个拟随机点集
这个例子展示了如何使用haltonset构造一个二维霍尔顿拟随机点集。
创建一个haltonset对象p,跳过序列的前1000个值,然后保留每101个点。
rng默认的%的再现性p = haltonset (2'跳跃'1 e3,“飞跃”1 e2)
p = 2维设置的霍尔顿点(89180190640991点)属性:跳跃:1000跳跃:100超码方法:无
的对象p封装指定的准随机序列的属性。点集是有限的,其长度由跳过和飞跃属性和对点集索引大小的限制。
使用争夺应用逆基数置乱。
(p, p =争夺“RR2”)
属性:跳跃:1000 Leap: 100 ScrambleMethod: RR2
使用净生成前500点。
X0 =净(P,500);
这就等于
X0 = p (1:50 0:);
点集的值X0是否生成并存储在内存中,直到您访问p使用净或括号索引。
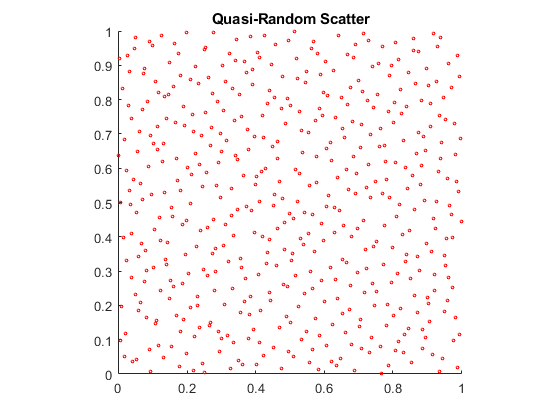
为感谢准随机数的性质,建立在两个维度的散点图X0。
散射(X0 (: 1), X0 (:, 2), 5,“r”)轴广场标题(“{\ bf拟随机散射}”)
比较这与均匀伪随机数产生的散点兰德函数。
X =兰德(500 2);散射(X (: 1) X (:, 2), 5,“b”)轴广场标题('{\bf均匀随机散射' ')

准随机散射出现更均匀,避免了在伪随机分散的结块。
在统计意义上,拟随机数过于均匀,无法通过传统的随机性检验。例如,由。执行的Kolmogorov-Smirnov测试键糟,用于评估一个点集是否具有均匀随机分布。在均匀伪随机样本上重复执行时,如由兰德,则检验结果为的均匀分布p值。
nTests = 1 e5;sampSize = 50;PVALS = 0 (nTests, 1);为nTests x = rand(sampSize,1);[h, pval] =键糟(x (x, x));PVALS(测试)= pval;结束直方图(PVALS,100) h = findobj(gca,“类型”,“补丁”);包含(“{\ p}值”)ylabel(测试的数量)

在均匀拟随机样本上重复进行检验,结果有较大差异。
p = haltonset (1,'跳跃'1 e3,“飞跃”1 e2);(p, p =争夺“RR2”);nTests = 1 e5;sampSize = 50;PVALS = 0 (nTests, 1);为x = p(test:test+(sampSize-1),:);[h, pval] =键糟(x (x, x));PVALS(测试)= pval;结束直方图(PVALS 100)包含(“{\ p}值”)ylabel(测试的数量)
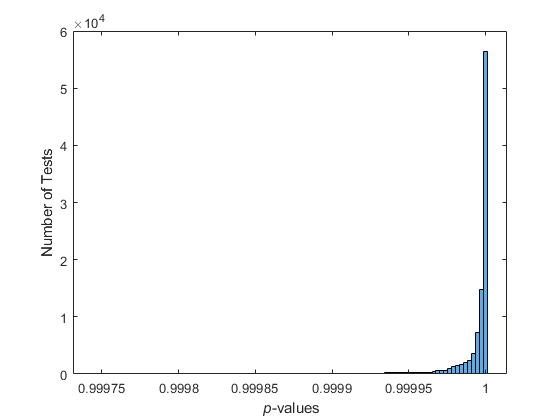
小p-值对数据均匀分布的原假设提出了质疑。如果假设是正确的,大约5%p-数值预计会降到0.05以下。结果非常一致,他们未能挑战这一假设。
拟随机流
拟随机流,由qrandstream函数,用于生成序列拟随机输出,而不是特定大小的点集。流可以像伪流一样使用兰德当客户端应用程序需要一个准随机数源时,该源的大小不确定,可以间断地访问。准随机流的属性,如它的类型(Halton或Sobol)、维数、跳跃、跳跃和攀登,都是在流构造时设置的。
在实现中,准随机流本质上是非常大的准随机点集,尽管它们的访问方式不同。的状态拟随机流的标量索引是从该流取的下一个点。使用qrand的方法qrandstream类从流中生成点,从当前状态开始。使用重置方法将状态重置为1。不像点集,流不支持括号索引。万博1manbetx
生成准随机流
这个例子展示了如何从一个准随机点集生成样本。
使用haltonset来创建一个拟随机点集p,然后重复将索引增加到点集测试生成不同的样本。
p = haltonset (1,'跳跃'1 e3,“飞跃”1 e2);(p, p =争夺“RR2”);nTests = 1 e5;sampSize = 50;PVALS = 0 (nTests, 1);为x = p(test:test+(sampSize-1),:);[h, pval] =键糟(x (x, x));PVALS(测试)= pval;结束
相同的结果,通过使用获得的qrandstream构造一个准随机流问基于点集p并让流处理索引的增量。
p = haltonset (1,'跳跃'1 e3,“飞跃”1 e2);(p, p =争夺“RR2”);q = qrandstream (p);nTests = 1 e5;sampSize = 50;PVALS = 0 (nTests, 1);为1:nTests X = qrand(q,sampSize);[h, pval] =键糟(X (X, X));PVALS(测试)= pval;结束
相关话题
您也可以从以下列表中选择一个网站:
