重采样数据
人工重复采样
bootstrap过程包括从数据集中选择具有替换的随机样本,并以相同的方式分析每个样本。带替换的抽样意味着从原始数据集中随机地分别选择每个观测值。因此,原始数据集中的特定数据点可以在给定的引导示例中出现多次。每个bootstrap样本中的元素数量等于原始数据集中的元素数量。您获得的样本估计的范围使您能够确定您正在估计的数量的不确定性。
这个来自Efron和Tibshirani的例子比较了15所法学院的法学院入学考试(LSAT)分数和随后的法学院平均绩点(GPA)。
负载lawdata情节(考试成绩,'+')lsline
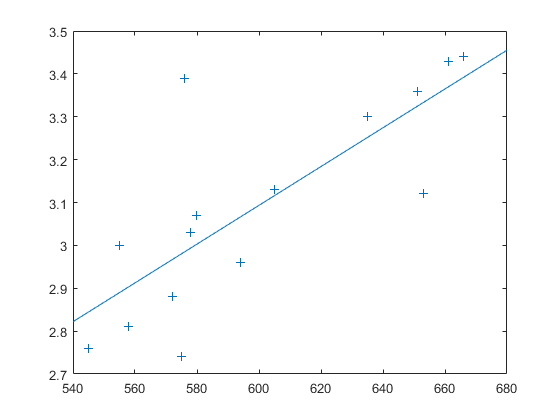
最小二乘拟合线表明LSAT分数越高,法学院的gpa就越高。但是这个结论有多确定呢?图提供了一些直觉,但没有定量。
你可以计算使用变量的相关系数|科尔|功能。
rhohat =科尔(LSAT,GPA)
rhohat = 0.7764
现在你有一个数字描述了LSAT和GPA之间的正相关关系;虽然它可能看起来很大,但您仍然不知道它是否具有统计意义。
使用bootstrp功能,您可以重新取样LSAT和平均绩点向量可以任意多乘,并考虑由此产生的相关系数的变化。
RNG默认的%用于重现rhos1000 = bootstrp(1000,“相关系数”考试,gpa);
此重新采样LSAT和平均绩点向量乘以1000,然后计算科尔对每个样品的功能。然后,您可以绘制在直方图的结果。
直方图(rhos1000,30,“FaceColor”,(。8。8 1])
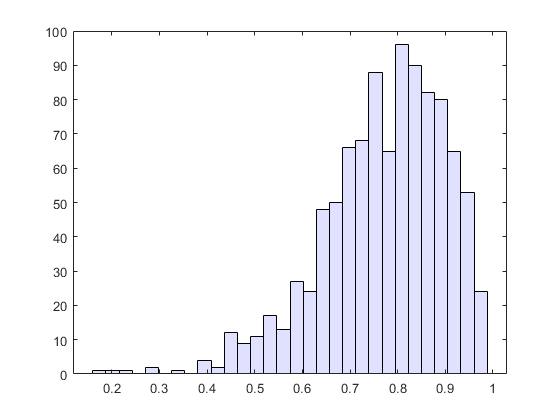
几乎所有的估计趴在区间[0.4 1.0]。
在统计推断中,通常需要为参数估计构造一个置信区间。使用bootci函数,您可以使用bootstrapping来获取一个置信区间LSAT和平均绩点数据。
CI = bootci(5000,@更正件,LSAT,GPA)
ci =2×10.3319 0.9427
因此,LSAT与GPA的相关系数的95%置信区间为[0.33 0.94]。这是LSAT与后续GPA正相关的有力定量证据。此外,这一证据不需要对相关系数的概率分布做任何强有力的假设。
虽然bootci函数计算的偏置校正的和加速的(BCA)的时间间隔为默认类型,也能够计算各种其它类型的自举置信区间,诸如学生化自举置信区间。
刀切重采样
与bootstrap类似的是jackknife,它使用重采样来估计样本统计量的偏差。有时也用来估计样本统计量的标准误差。jackknife是由Statistics and Machine Learning Toolbox函数实现的重叠。
jackknife有系统地重新排序,而不是像bootstrap那样随机地重新排序。作为一个样本n点,刀切法计算的样本统计n大小不同的样品n1。每个样本都是原始数据,省略了一个观察值。
在bootstrap示例中,您测量了在估计相关系数时的不确定性。您可以使用折刀来估计偏差,这是样本相关性高估或低估真实的、未知的相关性的趋势。首先计算数据上的样本相关性。
负载lawdatarhohat =科尔(LSAT,GPA)
rhohat = 0.7764
接下来为计算样本刀切的相关性,并计算它们的平均值。
RNG默认的;%用于重现jackrho =重叠(@corr,考试,gpa);meanrho =意味着(jackrho)
meanrho = 0.7759
现在计算偏差的估计值。
N =长度(LSAT);biasrho =(N-1)*(meanrho-rhohat)
biasrho = -0.0065
样本相关性可能低估了真实相关性大约这个数量。
对重采样方法的并行计算支持万博1manbetx
有关在并行计算重采样的统计信息,请参阅并行计算工具箱™。
