欢迎来到这个网络研讨会和SimBiology在药物开发的建模与仿真。我的名字叫Sietse Braakman。我是一个高级应用工程师MathWorks计算生物学。我在北美工作,帮助我们的客户在学术界和制药行业使用SimBiology。
在今天的网络研讨会,我想给你一个概述SimBiology用于建模和药物开发,然后转移到一个案例研究中,我们调查是否SGLT2抑制可能是一种可行的疗法治疗2型糖尿病。这将包括建筑区划的机械模型,模拟“如果”的情景调查SGLT2抑制是否会是一个很好的治疗,然后执行参数扫描。最后,我们也会估算参数校准我们的模型数据。
在那之后我将简要介绍如何共享模型和模拟与SGLT2抑制模型的使用Web应用程序。和Web应用程序在MATLAB和SimBiology基本上是应用程序,您可以通过Web浏览器与同事分享。最后,我们将结束还有问答时间。
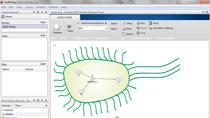
所以我第一次想给你简要概述SimBiology和如何使用SimBiology刺激你的食欲。我们看看SimBiology模型构建器应用程序,我们有一个图,代表了一个数学模型。这个图由不同的部分组成。所以在左上角这里SGLT2抑制剂的药物代谢动力学。在顶部,在右边,你可以看到葡萄糖吸收机制。中间你看到等离子体和葡萄糖的监管。和底部可以看到胰岛素调节。左边,然后我们有一些记账。
背后的想法是,实际上这个特殊的模型——SimBiology创建的一组微分方程从图。所以在这里你可以看到来自图和所有的方程我们给SimBiology的信息。这允许SimBiology创建一组微分方程和代数方程。
现在,当我实现了这个模型,我还可以运动模型。所以我可以运行模拟,得到这样的结果。所以我只是模拟该模型都有或没有SGLT2抑制剂在参考虚拟病人2型糖尿病——一个虚拟病人。你可以看到,如果没有治疗,你可以看到PK是平的。如果SGLT2抑制管理,每天都可以看到抑制剂管理。
然后你可以看到虚线,你比较的虚线,这样SGLT2抑制剂实线没有抑制剂。你可以看到是显著增加葡萄糖通过尿液排出。然而,没有一个非常显著的影响。它降低了血浆葡萄糖浓度,但一般不低于可接受的正常水平。这是你如何快速调查,是否可以在这种情况下,SGLT2抑制剂是一种可行的疗法治疗2型糖尿病糖尿病。现在,还有很多,我们将进入详细的案例研究。
所以SimBiology用于药物开发,我认为重要的是要了解如何使用不同的建模方法在药物开发和药物开发的里程碑是一致的。所以,一般来说,我们可以考虑有三个主要的里程碑。发现阶段,确定药物的目标。一旦我们已经确定了一个目标,我们进入临床前研究,试图了解药物达到一个目标,我们可以找到一个合适的剂量,剂量首次在人类的研究。所以,当我们在我们的临床研究评估药物的安全性和有效性并定义目标人群。
和这些不同阶段,不同类型的模型。这么早你可以用一种机械的系统生物学模型来确定药物靶点。一旦你进入临床前和临床研究,使用药代动力学、药效学模型和/或有着生理基础的药代动力学模型。然后,最后,有定量系统药理学的桥梁从发现早期临床研究。和我们的想法是定量系统药理学,机械的模型,包括治疗以及病理生理学。
考虑到这是竞技场药物开发的建模与仿真。SimBiology背后的想法是基本上允许用户使用SimBiology对于所有这些里程碑和所有这些建模方法,对建模仿真等其他先进的工作流参数估计,灵敏度分析,等等。这就是SimBiology背后的想法。现在,您可能想知道,我的意思是,我简要向您展示了SimBiology是什么样子,但也许我们可以解释更好SimBiology是什么。
所以SimBiology提供应用程序。所以这两个应用程序模型构建器和分析器模型应用,我之前给你们的,以及编程工具。所以您可以通过编程方式使用SimBiology,如果你的愿望。这允许您构建您的模型图,所以您可以构建它就像画出来。一旦你实现了你的模型,可以模拟。校准可以通过估计参数。你可以做进一步的分析,如蒙特卡罗模拟或敏感性分析。
SimBiology是基于MATLAB的顶部,你会知道MATLAB编程语言。和这种语言形式的基础上的所有产品MathWorks,包括SimBiology。s manbetx 845我们确保与MATLAB是所有的产品包括MATLAB——包括SimBiology经过严格测试,维护,每半年更新一次s manbetx 845,以确保一切工作在一起。
现在,当你听到的MATLAB,你也可能会想,好吧,其实我没有任何编程经验,我需要了解MATLAB为了使用SimBiology吗?答案是否定的。你不需要任何编程经验在MATLAB因为SimBiology图形用户界面意味着你不必编写任何代码。所以你只需要做的,如果你想。
现在,SimBiology坐落在MATLAB和是一个工具箱,它允许您有这些app-based以及程序化的工作流程。这些内建的分析工具。然后,模拟也加速了编译c代码。然后在SimBiology,项目。所以SimBiology项目包含一定的模型已经开发出治疗你,例如,发展。然后任何数据集,您可能使用参数估计——抱歉,参数估计的校准模型,然后和你的计划和分析这些数据集和模型。
和这些项目的优势是单个文件,您可以在SimBiology开放。你可以将它传递给一个同事也可以在SimBiology打开它。和它促进连续性和结果的再现性以及图形化模型表示,之前我给你们。图形化模型表示是真的帮助你表达你的模型两个合作者。
现在。SimBiology使用整个行业和学术界,下面是一些例子,用户如何使用SimBiology——为自己的药物开发。所以,首先,从基因泰克公司就是一个例子。这里的小组想要更好地理解药物myelosuppression,这常常会导致药品消耗和癌症治疗。威尔逊等人在基因泰克开发这QSP造血作用的体外模型。并使用细胞动力学,该模型校准数据,如果不治疗,并验证发表药物反应。它被用来预测myelosuppression的大小引起的这些新的化合物。
另一个例子是在AbbVie Klausnitzer等人的模型,发表一个综合模型背后的分子机制阿尔茨海默病与特定关注胆固醇和鞘脂类的失调。这个模型捕捉一些生物标记的调制阿尔茨海默氏症患者和药理反应发表在文学。它被用来评估针对S1P受体5以及小说治疗阿尔茨海默氏症。
最后,然而等人在葛兰素史克SimBiology建立模型的能力以编程方式使用自动化装配大两,大二端口PPK模型,参数化的使用一个扩展的组织分布时间进程数据集。模型的自动化组装帮助他们极大地减少模型建立的时间减少。
所以我希望给你一些想法SimBiology是什么,它在哪里被使用。现在,我想继续这个案例研究中,我们调查SGLT2抑制治疗2型糖尿病。
所以考虑这个假设情况。我们在过去几年当SGLT2的治疗方法还没有被批准,我的制药公司正在调查2型糖尿病治疗的新目标。和SGLT2的疗法之一,其中一个途径可能是有前途的。
SGLT2抑制背后的想法是,在正常情况下你的等离子体是通过肾肾小球过滤。然后这个滤液在肾脏重吸收回等离子体,所以这包括葡萄糖。和葡萄糖重吸收回等离子体通过SGLT2通路等途径。如果我们在SGLT2可以抑制,那么也许减少葡萄糖重吸收,更多的是通过肾脏排泄,所以通过尿液排出,这实际上会降低血糖浓度,因此,可以在一定程度上缓解效果和并发症观察2型糖尿病患者。
现在,这里的研究问题是SGLT2抑制导致有意义的减少血浆葡萄糖水平?在这个假设的情况下,作为modeler中,我给四个星期调查SGLT2目标的可行性。我没有初步数据,我必须做出假设的PK概要治疗。然而,我可以建立在现有模型glucose-insulin监管。再次,我必须指出,这个模型是对内部决策和不支持监管意见书。万博1manbetx所以它只是调查应该在SGLT2抑制我的公司继续工作。
所以这里我将使用的模型是一个模型由Dalla人,卡米尔,和Cobelli机械模型描述glucose-insulin监管。这里的SGLT2疗法被添加到这个glucose-insulin监管由我们的合作伙伴成立罗莎和co .) QSP咨询公司。和目标是一个说明性的例子。因此,正如我所说,这是一个假设的情况,当然,这只是说明你可以使用SimBiology创建QSP模型和回答特定的问题。
所以罗莎和co .)他们包括SGLT2影响尿葡萄糖排泄。他们包括PK。描述模型和其他参数的PK IC50。这些值,当然,被认为因为没有特定的PK,至少不是在假设情况。然后他们也为我们提供了两个参考虚拟病人,一个健康的和一个2型糖尿病病人。这里的想法是,罗莎和co .)合格的这两个虚拟病人对观察到的临床资料,以确保这些病人确实是代表健康的主题和2型糖尿病患者。
现在,有一些假设和局限性。首先,Dalla人等充分代表glucose-insulin规定,但只是短期调控的天,所以没有任何长期影响,你会看到与糖化血红蛋白。这是不包括在这个模型。所以我们可以使用这个短期——调查短期效应。
我们搬到SimBiology开始使用这个模型。为了开始在MATLAB SimBiology可以开始。这里你看到MATLAB,我们有家选项卡,然后还有应用程序选项卡,和SimBiology,模型构建器,和一个模型分析仪应用程序可以在应用程序选项卡中找到。
如果我打开SimBiology模型分析器,你看到我给你的模型。但是今天我要使用——基本上Dalla男人纸是——没有SGLT2疗法。所以我要做的是要包括SGLT2治疗然后链接,肾排泄率。这是我的下一个步骤。
现在,最简单的方法,我们可以把这个PK部分——在这种情况下,PK的部分将是一室模型。和最简单的方法将通过使用从SimBiology PK库。所以你可以从PK加载模型库,您可以看到有一个,两个,three-compartment模型与不同类型的剂量和消除。,在这种情况下,我们要用一个单区划模型,我们假设口服治疗,所以它是一阶剂量,然后我们有线性消除速率和体积。所以我选择这个,然后单击OK,这将给我单舱模型。现在我可以调查这个模型。
举个例子,如果我点击中央,单室中央,我可以看到,用1升舱有一个值。和对我们的治疗,必须6升。我们要设置6升。我也可以看看吸收率。所以正在吸收剂量药物中央ka速度和我可以给一个值。所以,在这种情况下,它是0.03,单位是1 /分钟。然后我可以做同样的消除速率,所以柯是0.003,这是在1分钟。
现在我们已经定义了这个单舱模型,我可以很快看一下方程。所以剂量中央,中央= -中央吸收剂量的变化。药物中心积极的变化,吸收,和消极,消除。所以你可以看到蓝色的物种。那些代表这里的蓝色长方形的形状和左边的微分方程。然后在橙色这里反应或通量。这里你看到通量。这些反应,这些代表任期——条款在右边的微分方程。
现在我可以做的是我可以复制。有一件事你必须确保,如果你去复制选项,设置当复制——所有这些设置为true,基本上,这将确保整个副本。所以我要选择所有的这些零件,我要打副本。然后我搬到另一个模型我要粘贴。这里我可以说粘贴,现在我有我的模型——我单舱模型添加到我的Dalla人模型。你可以看到,它还包括参数ka和柯。
所以一切都很好,我有我现在的药物动力学包括在内,但这个模型尚未与血糖调节。我要做链接,基本上,肾排泄率的药物浓度。所以如果我再次点击这个反应的反应是决定血浆葡萄糖的右手边。
这个血糖是一个物种。如果我点击肾排泄,你可以看到反应速率。这个反应速率是如何定义的,基本上,如果血糖高于一定的基底肾阈值,然后将有葡萄糖排泄。和葡萄糖排泄=肾小球滤过率乘以在血浆葡萄糖之间的浓度梯度,基底肾阈值。
和我在这里添加药物效应。这种药的效果目前只有1。所以我要做的就是我要定义,药物作用依赖于药物药物中央,这样我可以联系中心我的肾排泄。
所以在SimBiology是你使用的方式重复,重复的任务。和重复作业基本上是代数方程。所以在这里你看到的表重复作业。我可以简单地编写一个新的药物作用重复作业。
所以我要说= 1 - Imax *(药物的效果呢?central.drugcentral。?),在这种情况下,希尔系数是2。然后除以IC50平方-中央(?点。?),然后你也可以看到我在这里点击选项卡按钮然后我可以自动完成。再次,我们需要广场。然后我完成了。
现在,我已经做过的,这里有Imax是红色,我得到一个红色指示器。这是SimBiology告诉我,嘿,有点不对劲。我可以在这里模型评估工具,我可以验证模型。当我确认,我们发现一个错误,这个错误是Imax不参考任何物种参数或隔间,所以基本上Imax没有定义。
所以我还需要做什么。我可以去这里的参数表和广告Imax。所以我就照我说的做Imax是一个参数,该值为0.65,和无量纲单位。现在如果我验证我的模型,在模型中没有错误或警告。
所以我现在联系与PD的PK,但是有点——图中是不可见的。这是一件事我仍想做的事。这里我有药物作用,我现在可以做的是我可以去我的肾排泄反应,我可以说显示表情纹,然后你会得到一个破折号虚线,药物的效果。然后我可以做同样的事情重复赋值并显示反应。所以现在我可以看到这种药物效应联系在一起毒品中央集中的真正的排泄。
这样总结了模型建立这个案例研究的一部分。我们现在可以看一下方程。再一次,我们可以选择嵌入通量,但在这里你很好地看到每个通量都有一个不同的名称。有研磨、清空、胰岛素分泌,等等。然后你可以看看常微分方程,可以看到所有的通量,例如,对于血浆葡萄糖。
有两个其他的事情,我还没有显示你在SimBiology以后会很有帮助。第一个是剂量。所以在SimBiology可以定义剂量。在这种情况下,我们定义了剂量吃饭,早餐,午餐,和晚餐,以及SGLT2抑制剂。
所以SGLT2抑制剂,我们剂量300毫克,开始时间,1小时。然后间隔是1440,有一天,我们重复七次。所以SimBiology剂量可以混合和匹配。可以有多个应用同时,它们允许您快速探索不同剂量政权。
的另一件事是有趣的,我们称之为——所以我们称之为一个修饰词的剂量,它修改你的仿真结果。其他修饰符是变体。和变异的想法是你的模型结构和微分方程可能是相同的,但是模型可以描述不同类型的,例如,不同的表型,不同种类,不同药物的效果,所以你可以抓住的一个变种。因为变异是不同的参数化模型。
所以,在这种情况下,2型糖尿病患者肾小球滤过率(GFR)可能有不同的比一个健康的病人因为2型糖尿病肾功能下降。这是认为这两个虚拟参考咨询的病人都保存在一个变量中,我们可以应用这些模型,这些值模型来模拟和代表健康的病人或2型糖尿病患者,一个健康的人或2型糖尿病患者。
这是我们现在正在使用的变量,当我们模拟模型。到目前为止,我们已经在SimBiology模型构建器工作,现在我要搬到另一个应用程序,模型分析,模拟。
这里我们看到的模拟。我要创建自己的模拟和我——一个模拟称为程序。有多种类型的程序和仿真是这些项目之一。
所以这个项目我可以重命名。我能说这是一个单一的模拟。现在我可以通过这一步一步,看看它是什么,我想——我想模拟。所以我想模拟的模型是Physiopedia平台?网络研讨会?][?空的。?)这是我们刚刚在模型建造者,是的,Physiopedia [?网络研讨会?][?空的。?]
然后我可以应用变体。在这种情况下,我将2型糖尿病患者和剂量。所以,在这种情况下,我将申请餐,但尚未抑制剂,就看到一个基线2型糖尿病病人反应的样子。
我还可以定义模型的状态,所以我想哪些物种日志。在这种情况下,我只是想记录这四个物种。我想停止仿真后10080分钟,这是7天。让我们运行这个模拟和我们有阴谋。
所以我们看到了四个反应。他们每个人都有不同的颜色,这是因为他们切片的颜色。切,有反应。现在,因为黄色的值响应的血浆葡萄糖浓度,AUC是如此之高,以至于我看不到。所以我能做的是我可以把它们,而不是在一个网格。
如果我这样做,我可以看到每个响应分别在自己的图。然后我可以看一看尿葡萄糖排泄的基准是什么。所以你可以看到,在基线——所以没有SGLT2抑制似乎有一些合理的AUC——葡萄糖通过肾脏排泄。我们可以看到,血浆葡萄糖浓度被认为是高的。超过180——我认为,一般来说,180毫克每分升被认为是高葡萄糖水平。这病人肯定显示高葡萄糖水平。
底部,在这里你看到中央药物浓度,也就是平的。目前还没有药物被管理。但现在我能做的就是我可以添加药物,可以让模拟的结果没有毒品,然后我可以比较两个。让我们这样做。我们添加药物,然后再次运行仿真。
现在我们可以看到的是,一旦我们包括SGLT2抑制剂,红色的,你看糖尿病虚拟病人抑制剂,在蓝色的,你看到它没有抑制剂。你看到有显著增加,约一倍的尿葡萄糖排泄,和一个,不是很大,但是一个小降低血糖水平。当然,你也可以看到SGLT2抑制剂目前正在实施。
现在,我们看到的是,有一个小的效果,但是,当然,有些因素影响大小的抑制剂,抑制的影响,其中之一是肾小球滤过率(GFR)。
如果我们回到图,我们可以看一看——肾排泄的药物,如果我们看看肾排泄,然后你可以看到,肾小球滤过率(GFR)基本上限制了药物的总效应。那将是有趣的,看看会发生什么如果我们增加肾小球滤过率(GFR)。然后我们看到一个更大的效果?所以我们可以回到模型分析,我们可以探讨肾小球滤过率(GFR)的价值。
这是肾小球滤过率(GFR)。我可以为肾小球滤过率(GFR)创建一个滑块,看看会发生什么,例如,如果我改变,价值0.01而不是[?0.0——?][?或?][?05。?]现在我又能模拟模型与肾小球滤过率(GFR)的新值。然后你会发现药物的影响将进一步增加肾小球滤过率(GFR)比没有价值。
现在,当然,肾小球滤过率(GFR)不是你可以工程师。这是病人的财产。但重要的是要理解,如果病人有一个非常可怜的肾小球滤过率(GFR),那么也许这个疗法不会工作得那么好。
另一件事,我们可以,我们有一个影响诸如IC50,药物的消除速率和药物的吸收。因此,或许我们能做的是我们现在可以探索这些因素。我们这样做,我们可以扫描这些参数,看看效果的最大数量的葡萄糖被排出。
所以我可以为我的项目添加这个程序的副本,我们叫它探索IC50和柯。这是同一个程序,但现在你看到这里有一个+,+模拟程序允许您添加步骤。其中一个步骤是生成示例步骤和它的作用生成样本参数值或初始条件和刺激你的模型与备用值——这些采样值。
我感兴趣的是IC50,柯所以我可以拖IC50组件和相同的我可以帮客。所以,在这种情况下,我扫描——生成样本数量,但它也可以是一个,我想探索剂量或变体。所以说我想模拟模型与每个不同的变异,我有,我可以这样做。
现在,我将使用用户定义的值,但你也可以从一个分布样本值就像一个正态分布的随机抽样,例如。我将使用一系列的值是线性空间10至190年和我取5个样品。柯,我要做类似的事情,一个线性抽样在0.001和0.01之间,也在五个样品。
现在我要做的就是我要做一个笛卡尔参数组合。我要我要模拟模型结合每个值的每个值,所以我要有25种不同的样品。
这些步骤背后的理念是,你可以单独运行它们,您可以显示任何情节或[?不——?)我不会显示情节,但我要生成样本——这一个步骤的输出形式下一个步骤的输入。所以我可以运行这个模拟现在我已经生成的样本。现在是要模拟的模型为每个25样品和我忽略故事情节。
但我选择的是这些可观测的,可见是构建SimBiology,允许你计算仿真之后做点什么。作为一个全球测量你的目标结果。所以,在这种情况下,我把尿AUC的最大价值,就是输出,我想比较每一个样本。
这是我的计划,我可以看看最后的运行结果。所以这些样品,我们生成的。这些,当生成样本,这些是我的样品。但后来我也可以看看标量。和标量是这个——这是马克斯尿AUC你在这里看到的,因为这将导致一个值为每个模拟和我可以想象那些情节矩阵。
所以我选择标量,选择图矩阵,然后我让我的结果。这里你看到这些点基本上代表了不同的样品,我们带你看max尿AUC看到所有的25样品。所以,在这种情况下,很明显,如果我们有一个较低的IC50和低客,我们会看到最高的我们的治疗效果,因为在这种情况下,这种药物的效果最高以及药物AUC是最高的,如果我们有一个低的客。
但在你的情况中,你可能会看着一个联合治疗或治疗没有,可能有一种甜点和执行这些扫描就能真正帮助减肥。所以说我的公司有点感兴趣进一步探索这种疗法,并开始开发一个化合物,和我们现在有一些数据。所以我现在可以做的是我能说什么,嗯,一年之后,我仍然有这个模型,我们有数据,看看我们可以校准数据的模型。
在这种情况下,我可以从文件加载数据,所以它是一个Excel表,只PK的数据,所以你看浓度和剂量。我没有任何PD在这一点上的数据。当然,我也可以PD数据。现在我们的想法是,我们最终定义什么是依赖和独立变量。如果我想,我可以添加单位。
和SimBiology,再次,可以确保你的模型和数据之间的单位是一致的,你不做任何数量级的错误。我们有我们的数据,但是,当然,我们仍然不知道这些数据是否代表单舱模型——单舱模型是否适合这些数据。
所以我们先可视化数据。如果我点击这里在校准数据和选择一个时间曲线图,得到一块数据。如果我们绘制semilogy范围你可以看到,有一个清晰的线性消除和一些吸收阶段。所以它适合适合单舱模型数据。
这正是我们现在要做的。我们将创建一个名为适合数据的程序符合我们的模型数据。所以我选择数据集,然后我也选择我的模型。我要用这个单舱模型。
然后下一步我们需要做的就是我们需要映射的列在我们的数据集。记住,这是四个列名在我们的数据集的部分在我们的模型中。所以ID列代表小组。有九个科目在我们的数据集。你可以在这里看到。
浓度和时间是自变量,然后是我们的因变量。和代表?central.drugcentral。?]中央。和剂量表示目标,所以去剂量中央因为这是口服剂量。这将允许SimBiology为您创建目标函数,然后我们唯一需要做的就是我们需要定义参数估计和我们要用什么样的估计算法。
现在,在这个例子中,我将使用非线性回归,所以固定效果,但是您可以使用混合效应和混合效应和随机解算器。这两个,你需要统计和机器学习工具。然后我要做一个池符合比例误差模型。
我将使用lsqnonlin,优化工具箱的一部分。lsqnonlin在当地最小二乘优化算法。我也可以使用全局动力学,全局优化算法,如分散搜索或粒子群,但这个问题很简单,没必要这样做。所以我们就用lsqnonlin。
最后,再一次,在这里你看到加,我也可以添加其他步骤,这些步骤之一是置信区间。所以我要计算这个——参数置信区间估计,我所做的,同时也为预测预测。
所以我要运行这个。你看到这里有一个按钮平行。例如,如果你做置信区间与引导,这是对很好。或者如果你做全局优化,还可以并行化。所以很容易加速这些流程与点击的按钮在您的机器上。
现在,这里你看到的是我们进步的情节进展通过迭代优化。我们做了七个迭代和你看到日志可能性的价值,我们想最大化,一阶最优性,我们想最小化,你看到的每一个参数的值var,改变他们最初的估计,我们给他们最后的估计。现在我们有了一组参数诊断的情节。
我们可以看看合适的情节,我们看到,显然,这是一个适合那就只有一种模拟需要适合通过所有的点,这似乎是一个合理的健康。我可以看看观察和预测,我们理想的想,如果我们的模型是完美的,所有这些点会沿着线——团结躺在这里,但这看起来已经相当不错了。残差与时间,我们只是想确保残差都分布在这0,因为否则,你可能——我们也许早在我们可能低估了——或者,是的,低估了真正的价值。
我们可以看看残差——残差的分布,这基本上红线代表一个正态分布。如果点躺沿着这条线,那么你可以假设你的观点,你的残差近似正态分布。然后我们还可以看看置信区间,所以这是一个关于每个不同的参数的置信区间。这些是高斯置信区间,所以事后。这不是一个引导或概要可能性置信区间。但仍然看起来我们有一个合理的信心,每一个参数。
同样的我们可以做预测。你可以看到这里的预测——这基本上是有95%的信心。鉴于这种数据和这个模型,模型的响应将在蓝色区域内。
正如我所说的,目前我们只有我们只估计PK参数。但是,当然,如果你有一个PD反应在你的数据集,也可以估计PD模型中部分参数。这个案例研究总结。让我们回到幻灯片就包起来。
所以这里的模型支持SGLT2抑制的可万博1manbetx行性。这不是淘汰赛疗法。显然似乎工作只是为了更高的肾小球滤过率(GFR)的值。这是一些你可能需要考虑患者人群。我们可以设计复合以这样一种方式,我们有最影响的化合物。
现在,这里的限制是,人口模型不捕获完整的响应或长期体内平衡。,因此,它是真的,只告知那些早期的开发决策。所以我希望这个例子是给你一个想法如何实现模型的SimBiology以及如何然后使用该模型来回答问题和校准你的模型数据。
现在移动到下一个部分,说,你想分享你的模型和仿真能力——与你的同事。和同事可能non-modelers,他们可能是生物学家,但他们想玩玩你的模型。你怎么做呢?嗯,你可以使用web应用程序的。
和最简单的方式向大家展示什么是web应用程序向你展示一个web应用程序。这是一个web应用程序,所以你可以看到我在我的浏览器,这个地址是在MathWorks的VPN服务器。所以只有在互联网上,这是MathWorks以外的任何人都无法访问。
和服务器,我通过VPN连接,服务器位于慕尼黑。,我唯一需要的是一个链接,我可以登录,然后我可以玩玩这个模型。所以我可以看到的效果是增加Imax或的效果是减少IC50,增加肾小球滤过率。
所以这样,我可以系统地探索这个模型,我可以领略到什么是重要的参数,而你作为一个模型你可以决定,当然,滑块的你想要包括什么,你想要包含什么阴谋,和所有的。这是一个很好的方法与你的团队分享你的模型和结果。
短暂,所以你将创建这些应用程序的人,然后传达——你分享那些应用程序与用户模型。和你使用的想法是,在MATLAB中,您使用应用程序设计师,所以你需要有点熟悉编写代码。然后您可以创建这些应用程序,包,把它们放在一个服务器,然后你会得到一个链接基本上,你可以与你的同事分享。
现在,有很多。我们可以更详细地讨论,但是,不用说,这可以让你保持在更大的环境中,很容易与你的同事分享你的结果。你需要MATLAB编译器,当您看到,创建这些包和——和分享这些应用程序作为web应用程序。
让我们结束。现在,有一些事情我没有我没有谈论的机会。其中一个是局部和全局灵敏度分析。我们可以使用敏感性分析来发现潜在的药物靶点,寻找某些重要参数模型的结果,您应该确定哪些参数估计和参数你可以使用它来解决,因为模型不敏感。
所以SimBiology既支万博1manbetx持局部灵敏度分析和全局灵敏度分析。和全局灵敏度分析我们支持两种方法目前,全球Sobol敏感性分析以及multiparam万博1manbetxetric全局灵敏度分析。有一个关于这个主题的研讨会,你可以在我们的网站找到,进入细节关于这个主题。
我提到的另一件事是在一个应用程序,您可以使用SimBiology以及编程,所以我们可以有一个短暂的看。所以说,一个典型的模拟程序,我们可以等效为程序代码。
所以我们可以加载我们的项目和从我们的项目选择模型,然后从这个模型发现的剂量——找到一个叫做“50 nanomole日报”然后将停止时间设为三天,然后用这些设置模拟模型和剂量。最后,我们把仿真数据,我们得到一个这样的情节。这是说,您可以通过编程方式使用任何东西,你可以做任何你可以做的用户界面。
最后,我们有一个活跃的社区SimBiology用户。这里的一个例子是集团在Genentech gQSPSim开发,这是一个SimBiology-based图形用户界面应用程序的标准化QSP模型开发应用程序。它旨在提供透明的方法,可再生的,和便携式QSP SimBiology建模通过扩展功能,特别是交互式可视化和虚拟对象的统计校正。
所以如果你想知道更多关于这个,你可以看看网上gQSPSim手稿。这个程序是免费下载。当然,这取决于你拥有SimBiology。
其他例子使用的SimBiology建模框架是百时美施贵宝公司的QSP工具箱,这——这是为了规范QSP工作流的关键方面,包括数据集成、校准,和可变性的探索,以及校准虚拟人群。
发达VQMtools有利。和有利的是另一个咨询公司——VQMtools关注虚拟人口为基础的创建和评估——基于参考对象和模型约束的定义。
最后,从亚历山大Popel约翰霍普金斯大学已经开发出一种SimBiology-based immuno-oncology QSP建模平台,允许建设QSP模型在IO不同程度的复杂性根据手头的研究问题。
这给我们带来了我们的社区。我们有一个社区页面。如果你只是寻找SimBiology社区,你就会找到它。它包含链接到那些我刚刚谈到的贡献。它包含一个答案——问答部分以及教程,教程视频链接SimBiology如何构建模型,如何模拟,如何做参数估计,等等,和non-compartmental分析。这是一个有用的资源,你也可以,你可以问问题,我们将尽快回答。
所以总结一下,SimBiology是什么?SimBiology提供应用程序以及编程画图工具来构建一个模型,来模拟模型,并研究“如果”场景,来估计参数,模型校准数据,或者你可能有多个数据集,并执行分析这样的全局敏感性分析或蒙特卡洛模拟。所以,我将结束,我想谢谢你的关注。