编辑注意:该文件被选为MATLAB Central本周精选
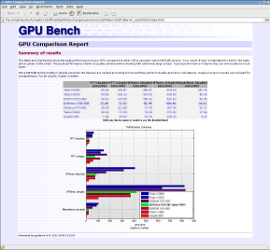
GPUBHANCH时间不同的MATLAB GPU任务,并估算GPU在每秒浮点操作中的GPU的峰值性能(FLOP / S)。它生成详细的HTML报告,展示了GPU的性能如何与一系列其他GPU的预先存储的性能相比。
注意,这个工具是为比较GPU硬件而设计的。它没有比较不同MATLAB版本的GPU性能。
要求MATLAB R2013b或以上,GPU与CUDA计算能力2.0或更高。
引用作为
MathWorks并行计算工具箱团队(2020)。GPUBench(//www.tianjin-qmedu.com/matlabcentral/fileexchange/34080-gpubench), MATLAB中央文件交换。检索。
评论和评级(98)
更新
| 1.11.0.0. | 更新报告的风格。 |
|
| 1.10.0.0 | 更新R2017B数据文件 |
|
| 1.10.0.0 | 为R2017a添加数据文件 |
|
| 1.9.0.0 | *使用R2014b、…、R2016a的数据更新gpuBench |
|
| 1.10.0.0 | 在R2014B运行应用程序时修复数据位置的问题 |
|
| 1.9.0.0 | *提高与MATLAB R2014b的兼容性 |
|
| 1.8.0.0 | 修正了使用MATLAB应用程序版本时的递归问题。 |
|
| 1.7.0.0 | *为R2013B添加数据文件 |
|
| 1.6.0.0 | *为R2013A添加结果(包括K20!) |
|
| 1.5.0.0. | *被忽略的结果警告被抑制 |
|
| 1.4.0.0. | *添加一个“app”版本,用于R2012b及以上版本 |
|
| 1.2.0.0 | 尝试防止超时触及碰巧驱动显示器的非常慢的GPU。 |
|
| 1.1.0.0 | 为C2075添加数据 |
gpubench_v1.11.
Gpubench_v1.11 / + gpubench
你也可以从以下列表中选择一个网站:
为了完整起见,这是对M.G.的回答的问题张贴在MATLAB的回答:
//www.tianjin-qmedu.com/matlabcentral/answers/474879-gpu-recommendation-for-deep-learning-and-ai.
(请参阅评论部分)
我需要决定哪个GPU购买(为深度学习),我希望能够答复以下问题,以确定我应该购买的GPU。
MATLAB是否使用默认(特别是加强学习工具箱)的深度学习进行单精度计算?
我知道Matlab一般使用双精度计算,我注意到大多数图形卡(例如RTX 2000和3000系列)单精度计算速度高,双精度计算速度却相当慢(1:32)。只有超级昂贵的gpu(如V100和A100)才能维持双精度(1:2)的高速计算。因此,如果Matlab默认为单精度,我可以只买一个相对便宜的卡片,并在强化学习工具箱获得良好的性能。否则,我将不得不购买一个更昂贵的卡,以获得高速双精度。
我真的很欣赏这里的一些帮助:D
英特尔(R) Core(TM) i5-5200U CPU @ 2.20GHz | 8GB RAM | GT 940M
==========================================.
双精度
mtimes |反斜杠|FFT.
GPU:24.56 |18.30 |10.73
CPU:49.55 |42.80 |4.93
==========================================.
单精度
mtimes |反斜杠|FFT.
GPU:518.49 |153.81 |24.93
CPU:107.68 |83.30 |8.62
Intel i9-9750H CPU @2.60GHz 6核,NVidia RTX 2080 Qmax
============================================
双精度
mtimes |反斜杠|FFT.
GPU:331.17201.42146.93
Cpu: 151.21 112.27 14.00
==========================================.
单精度
mtimes |反斜杠|FFT.
图形处理器:8361.31 1076.59 612.33
Cpu: 317.02 243.40 29.39
==========================================.
Intel(R) Core(TM) i7-9700K CPU @ 3.60GHz | 32GB RAM 2666 MHz | Nvidia RTX 2080 SUPER
============================================
双精度
mtimes |反斜杠|FFT.
GPU:355.97 |183.51 |149.37
CPU:314.63 |156.11 |16.13
==========================================.
单精度
mtimes |反斜杠|FFT.
Gpu: 10683.54 | 1196.45 | 647.30
Cpu: 622.69 | 386.47 | 40.32
==========================================.
非常好!谢谢
英特尔Xeon W-3265 | 192GB ECC RAM | Nvidia Titan RTX
============================================
双精度
mtimes |反斜杠|FFT.
Gpu: 494.31 | 390.03 | 217.41
Cpu: 1307.66 | 323.78 | 26.30
==========================================.
单精度
mtimes |反斜杠|FFT.
Gpu: 15374.46 | 3683.54 | 1093.00
CPU:2436.82 | 639.88 | 44.70
==========================================.
英特尔(R)Xeon(R)金6230 CPU @ 2.10GHz |96GB RAM |Quadro rtx 6000.
==========================================.
双精度
mtimes |反斜杠|FFT.
GPU:545.57 |517.06 |240.11
Cpu: 1647.39 | 324.92 | 21.03
==========================================.
单精度
mtimes |反斜杠|FFT.
Gpu: 14720.67 | 2960.43 | 985.47
Cpu: 3126.55 | 610.91 | 35.15
==========================================.
英特尔(R)核心(TM)I7-5820K CPU @ 3.30GHz |Quadro M5000.
================================================
双精度
mtimes |反斜杠|FFT.
Gpu: 120.01 | 94.90 | 66.92
Cpu: 207.12 | 136.36 | 7.92
==========================================.
单精度
mtimes |反斜杠|FFT.
Gpu: 3885.49 | 1329.31 | 296.31
CPU:415.55 |261.23 |12.72
==========================================.
完成运行后,不会跳出任何HTML报告。有浏览器设置的任何东西吗?
英特尔Xeon W-2125 | 64GB RAM |
================================================
双精度
mtimes |反斜杠|FFT.
GPU:501.40 |238.15 |226.72
Cpu: 318.83 | 138.90 | 12.04
==========================================.
单精度
mtimes |反斜杠|FFT.
Gpu: 12856.65 | 1844.82 | 791.83
Cpu: 654.36 | 319.05 | 21.06
==========================================.
英特尔9900K @ stock | 64GB RAM | Nvidia Titan RTX
==========================================.
双精度
mtimes |反斜杠|FFT.
Gpu: 534.63 | 340.87 | 239.43
CPU:394.33 |200.68 |16.47
==========================================.
单精度
mtimes |反斜杠|FFT.
GPU:13570.52 |2974.16 |924.16.
CPU:734.57 |418.49 |34.77
==========================================.
AMD Ryzen Threadripper 2950X
GeForce RTX 2070
==========================================.
双精度
mtimes |反斜杠|FFT.
291 | 169 | 134
主机PC |158 |105 |11.
==========================================.
单精度
mtimes |反斜杠|FFT.
7974 |1515 |795.
主机PC | 400 | 264 | 19
==========================================.
xeon gold 6126 dual / 128 GB
Quadro GV100双重(我不确定两个GPU工作)
双精度反斜杠的结果太低。
==========================================.
双精度
mtimes |反斜杠|FFT.
6828 |350 |525.
主机PC |588 |124 |12.
==========================================.
单精度
mtimes |反斜杠|FFT.
13879 | 1683 | 1043
主机PC |1137 |267 |18.
==========================================.
Hi Mohammed,通常gpuBench会测量你的GPU和CPU,让你知道你可能达到的最佳情况下的加速。如果没有检测到GPU,你应该选择只在CPU上运行,这样你就可以看到不同的GPU与你的CPU相比,如果你安装了它们,它们会给你带来什么样的速度。这是你所看到的,还是它只在CPU上运行而没有提供选择?
虽然乍一看可能有点奇怪,但能够将你的CPU与各种GPU进行比较,对许多考虑购买GPU的人来说是很有用的。
它在CPU上运行GPU计算,不是那么奇怪吗?
嗨,刚刚在Nvidia K80上运行,得到了(顺便说一下,卡上只使用了一个GPU,如何快速更改它?)
警告:F的测量时间可能不准确,因为它运行得太快。试测
需要更长时间的东西。
>在timeit(第158行)
在gpuBench>iTimeit(第323行)
在Gpubench>运行时(第207行)
在gpuBench中(第103行)
在gpuBenchLauncher中(第11行)
在gpuBenchApp/startApp(第88行)
在GPubenchApp(第48行)
在appinstall.internal.runapp>中执行(第78行)
在AppInstall.internal.RunApp> RunApp13a(第57行)
在appinstall.internal.runapp>中runcorrectversion(第36行)
在appinstall.internal.runapp中(第18行)
我的泰坦X(Pascal)结果如下。
我认为我应该预期双重精度算术在11次TFLOP / 32 =〜343 GFLOP进行
这是基于阅读http://www.guru3d.com/articles-pages/nvidia-geforce-titan-x-pascal-review,1.html.
343 GFLOP就是你在下面的基准表中看到的,所以我认为我得到了我所支付的。
数据类型'double'的结果
(在gflops中)(在gflops中)
mtimes backslash fft mtimes反斜杠fft
TITAN X (Pascal) 357.95 308.44 187.75 7349.88 2175.31 632.93
我欣赏的反馈。我的推理正确吗?
你为什么不把结果公布出来呢?
I7 7700K CPU @ 4.2 GHz / 16GB RAM(3200MHz)
CUDA 8
==========================================.
双精度
mtimes |反斜杠|FFT.
GeForce GTX 1080Ti | 423 | 286 | 190
主机PC | 258 | 162 | 23
==========================================.
单精度
mtimes |反斜杠|FFT.
GeForce GTX 1080Ti | 11907 | 1897 | 679
主机PC | 502 | 340 | 33
==========================================.
Mac用户还是有希望的!
MBP 2016 I i7-6920HQ CPU @ 2.90GHz
16 gb的记忆
CUDA 8,
结果:
==========================================
Double Precision
MTimes | Backslash | FFT
GeForce GTX 980 Ti | 190 | 165 | 104
主机PC |157 |105 |12.
==========================================
单精度
MTimes | Backslash | FFT
GeForce GTX 980 Ti | 5998 | 1058 | 433
Host PC | 316 | 202 | 20
==========================================
https://devblogs.nvidia.com/parallelforall/cuda-8-features-revealed/
希望我们很快就能得到Pascal的支持。万博1manbetx
I7-6850K@3.60GHz,CUDA 8RC,内存16GB
结果:
==========================================.
双精度
mtimes |反斜杠|FFT.
GeForce GTX 1080 | 276 | 188 | 139
主机PC | 204 | 124 | 8
==========================================.
单精度
mtimes |反斜杠|FFT.
GeForce GTX 1080 | 5273 | 1403 | 422
主机PC |367 |245 |15.
==========================================.
仔细检查个别曲线:
——FFT(double)在ArraySize=4M之后下降
- Arraysize = 4M后,MTimes(单一)滴
- Araysize = 16M后的FFT(单)滴
马丁,
我对此也很感兴趣,但很明显,“pascal”Geforce TitanX的性能将比1080GTX高出约30%。由于CUDA 7.5的当前版本没有完全支持pascal平台,目前的单精度性能还没有达到预期的水平(GTX1080应该是>8Tflop/s,而TitanX应该是<12Tflop/s)。万博1manbetx
至于双精度,与任何GeForce卡一样,泰坦x在与K40c卡的竞争中毫无胜算,因为英伟达想要销售价格更高的特斯拉卡。
在单精度下,1080GTX已经比Yourk40C快20%,但它的硬件更快160%。
有人愿意使用最新的Titan X发布他们的基准结果吗?我目前有一个K40c,我正在使用计算(主要是FFT),我希望购买更多的计算能力(双精度)。从我理解的fft是大多数记忆界限,所以泰坦x这样的东西可能会以更便宜的价格工作和K40c。我已从下面的K40C发布了我的结果。
双| MTimes |反斜杠| FFT
特斯拉K40c | 1154.72 | 706.48 | 135.51
主机PC | 186.81 | 117.49 | 4.97
单| MTimes |反斜杠| FFT
Tesla K40C |3071.64 |1284.10 |299.57
主机PC | 468.12 | 226.27 | 8.94
谢谢,艾莉森,我刚才试过了。在整个计算机重新启动后工作。
Matlab/ GPU尝试使用简单的过滤器medfilt2(a,[9,9])时总是崩溃。小一点的社区还可以,大一点的就不行。空闲内存是NaN,除了重新启动Matlab,没有任何帮助。硬件似乎坚如磐石,用其他CUDA代码进行了几天的压力测试。这是一个描述。http://de.mathworks.com/matlabcentral/answers/299970-reset-gpudevice-does-not-work.
我不想在这里进入细节,错误的地方,但目前我们的底线是,我们计划使用Matlab加上消费者GPU(1080GTX,Titanx)扩展我们的一些模拟工作,其中8或12个TFLOPS听起来很棒(我们只需要单精度)。然而,在这一点上,我并不是说服这些联合非常强大。
也许CUDA 8会解决这个问题,然后/或者2016b。
嗨,阿诺德
停止此延迟重复使用第一个GPUARRAY或MATLAB的其他GPU命令的一种方法是GTX1080中的MATLAB中的命令是在您的系统上设置名为CUDA_CACHE_MAXIZE的环境变量。这是默认设置为32MB,当我们重新优化我们的Lascal架构的库时,这是一个足够的空间。因此,而不是一次性优化每次发生延迟。
从实验中,我们建议将其设置为500MB至1GB的大小。为了将缓存设置为1GB,使用CUDA_CACHE_MAXSIZE 1073741824.在Windows中,您可以在“属性”>“高级系统设置”>“环境变量”中执行此操作。
嗨,本,
关于延误。是的,非常令我惊讶的是,它目前需要一分钟(!)左右,每当我开始Matlab时打开第一个GPUArray,这有点击败了例如迅速分析大型图像的目的。执行此基准时发生了同样的事情,在甚至开始之前花了很长时间。这似乎落在你对CUDA 7.5的描述中。
当NVIDIA更新CUDA时,当前的MATLAB发布将在NVIDIA更新中获得更新吗?
我还拿回购买了一个新的私人执照,然后因为使用GPU是一种我计划在家中做的事情。在工作中,我们有一个订阅计划,所以没有担心......'完成后'。
谢谢你让我知道,我字面上准备购买一个家庭使用的r2016a许可证,但这将是一种浪费,然后如果我需要CUDA 8的Pascal和Matlab可能不会去提供它的r2016a ....
asa旁注:
我正在使用GPUArrays与Matlab的问题,如Medfilt2(A,[11,11])总是崩溃,而大小为7,7仍然有效。
只有重新启动matlab才能使GPU再次可用。
嗨,阿诺德,谢谢你分享这些结果。
虽然时序可能是一个较小尺寸的问题,但我认为你在GTX1080的收益的方式看来的真正原因是Matlab和并行计算工具箱(CUDA 7.5及更早者)中使用的CUDA的版本不直接支持新的“Pasca万博1manbetxl”类GPU。相反,他们回到了库的立即重新编译,这也是为什么你会在首次使用的大延迟。这意味着所得到的算法未对新的Pascal GPU架构完全优化。
CUDA 8将是第一个拥有本机Pascal GPU支持的CUDA版本,但截至目前(8月22日),除了作为“候选版本”外,它尚未上万博1manbetx市。
大家好,
在一台新机器(GTX 1080 & Intel 5960X)上进行了测试,得到了一个很好的警告消息:
====================
警告:F的测量时间可能是不准确的,因为它是
运行太快。尝试测量需要更长时间的东西。
====================
所以它很快,我猜:P,显然只需单一精度(谢谢NVIDIA)。有趣的是,它远离它的是8TFLOP / s,但理论上它在理论上是单一精度的。4.42 Tflop / s它只能比我尝试的GTX 970更快500GFlop / s。它可能是,警告消息是正确的,此测试无法真正衡量正确的性能?
结果:
==========================================.
双精度
mtimes |反斜杠|FFT.
GeForce GTX 1080 | 219.50 | 175.22 | 115.19
主机PC | 329.06 | 202.88 | 16.29
==========================================.
单精度
mtimes |反斜杠|FFT.
GeForce GTX 1080 | 4420.24 | 1570.92 | 414.50
主机PC |617.28 |407.54 |19.79
==========================================.
一个普遍的问题,我假设你们中的一些人使用GPU计算和神经网络;有没有人用GPU来解决预测问题,并获得了比使用CPU更快的计算速度?
更多信息在这里:
http://se.mathwands.com/matlabcentral/answers/291744-time-series-prediction-using-neural-networks-narnet-narxnet-it-it-at-al-possible-to-train-a-ne.
玉峰,你的泰坦x得了多少分?
马尔科姆:我对这个很感兴趣,你能随时通知我们吗?
(也评价;我在两台不同的机器上运行一台Titan X和一台T2075)
玉丰
我正在2015年年中为macbook pro 15英寸的外接GPU构建过程中。试图找出哪一个是最好的GPU运行雷霆2。
(Arnold,我指的是GTX 980而不是GTX 1070…对不起对于这个)
感谢阿诺德关于GTX 1070卡的规格。如果我可以让nexus它将有相同的测试执行与GTX 1080卡。明天早上我将添加16gb内存和专业SSD到我的装备,下一步很可能是添加GTX 1080(然而,我预计这张卡的价格很快会下降,并将等待几周后购买)。如果没有人打败我,我将添加规格的GTX 1080卡一旦获得。
的工作原理。
在这个系统上试了一下:
英特尔2500k,GeForce GTX 970 4GB
==============
双 ----------------------------- 单
MTimes |反斜杠| FFT——MTimes |反斜杠| FFT
GeForce GTX 970.
115.58 | 86.22 | 62.41 ---- 3755.02 | 444.68 | 247.94
主机
104.40 |62.44 |7.68 ---- 214.48 |152.65 |14.94
真可惜,普通卡片的精度比普通卡片差了一倍
该应用程序给出了许多警告,即Nargchk已过时,如果您可以相应地更新应用程序会很好。
为用户提供一个良好的视角,如果他/她真的想要继续并在GPU上实现他们的代码。你知道,转换你的代码的痛苦vs /s奖励更快的计算。
我只是想指出,我只能在gpuBench中更改第442行之后,在MATLAB R2014a上运行它。m从“freeMem = gpu.AvailableMemory;”到“freeMem = gpu.FreeMemory;”以防其他人有同样的问题。干杯,马丁
@Alex。我完全同意。15英寸Macbook Pro的双精度浮点性能受损。参见GPUBench score @http://www.tinyurl.com/cuda-on-mac.
@Fabio:这是在2013年底的Macbook Pro上,2.3 Ghz, 16gb。见最后两行。似乎只有FFT双精度比CPU快(大约是CPU的两倍)。\和*要慢得多。相当糟糕的表现……
苹果应该使用Quadro K1100M(与750 50m相同的物理芯片,但没有受损的双精度)。从外观上看,它真的不值得为750M的MBP上的GPU进行编码。你可以继续用中央处理器。问题是,如果你想购买没有750M但CPU相同的MBP,你最终支付相同的价格(至少这是我在5月份购买它时的情况)。
数据类型'double'的结果
(在GFLOPS中)数据类型为“single”的结果
(在GFLOPS)
mtimes backslash fft mtimes反斜杠fft
Quadro K6000 1489.50 453.38 141.32 3998.82 737.72 295.48
特斯拉K20c 1005.00 490.83 110.40 2690.21 772.21 257.51
特斯拉C2075 327.83 242.26 69.13 684.97 425.15 144.56
GeForce GTX Titan 213.35 124.43 90.89 3840.88 735.68 328.85
GeForce GTX 680 139.20 97.53 58.82 1468.69 620.54 214.67
Quadro 2000 38.60 33.01 14.18 232.90 122.57 46.32
GeForce GT 640 18.13 14.08 8.51 185.60 95.49 33.62
Quadro K600 13.24 10.69 6.17 135.40 0.01 26.57
主机PC 136.45 82.92 7.90 250.23 178.69 5.71
GeForce GT 750M 27.38 23.01 13.83 348.97 0.03 59.32
Noel, MacBook Pro retina, 2013年底,i7 2.3GHz, 16gb,带有Nvidia GT 750M离散卡:
C/GPU GFlops |MTimes|反斜杠| FFT| MTimes|反斜杠| FFT|
主机PC | 144.88 |63.95 |6.93 |235.92 |153.01 |11.81
GeForce GT 750M |27.92 |19.58 |13.04 | 296.35 | 0.03 |60.88
和一个请求......有人对NVIDIA GT 750M的GPubench结果是否在最新的MacBook Pro内存。我想知道双重精度是多么瘫痪在我买一个之前。提前致谢。
新版本发布了R2014a,但仍然没有R2014a的数据,所以GPUBench在报告生产时失败了(如果运行的是R2014a)。一个解决方案是更改R2013b的名称。R2014a垫。mat,则R2014a可以成功运行GPUBench !
嗨本,是的,我从8pins +缺陷6pins,到了8个引脚+ LP4-> 6pins,现在很棒。谢谢你的支持!万博1manbetx
最后澄清一下:您现在是否已经连接了6针和8针连接器?当然,你需要两者都得到完整的250W,这是Titan在峰值负载下可以消耗的。
班
嗨,本,谢谢你的评论。在执行大量的测试,换回等后,我发现我的PSU有一个缺陷,因为它现在正在工作(GPubench,3DMark等)后,我用双LP4出口+从PSU取代PSU的直接6引脚出口后适配器。
你好,塞德里克,你能把完整的日志发给我们吗?如果它太大了,不能在这里发布,直接使用上面的作者链接发送。
在猜测它听起来像你超过一些电源设置,同时运行计算 - GPU替补是故意计算(并因此电力)重。您是否肯定有连接的电源连接器?你的psu听起来足够大,所以它有点奇怪。
班
当我尝试在“GPU single”测试/部分运行GPUbench时,我得到了一个关机/重启(在事件日志中名为“kernel-power”的条目)。
GTX Titan Black(插槽PCIe2 16x 75W),安装在DELL Precision T7500上,双Xeon X5550, 24GB RAM, 1110W电源,最新BIOS更新,SERR/DMI禁用,显卡驱动337.88。
win7sp1 64bit, CPU E5-2687Wv2, Matlab 2014a
GTX TITAN黑色1312.05 517.26 150.15 3730.83 881.97 309.47
主机PC 140.18 101.90 6.89 327.19 209.63 9.50
谢谢米科尔
我认为随着我的双重精度有同样的问题。
但它似乎有必要为GTX泰坦启用双重精度模式
它位于NVIDIA控制面板,在“管理3D设置”,“全局设置”选项卡下。
启用后,事情看起来有很大的不同:
mtimes_d backslash_d fft_d.
GeForce GTX Titan 1285.83 128.35 146.92
特斯拉C2075 333.84 246.11 73.36
Ubuntu 12.04.3 64bit, Matlab R2014a
数据类型'双'的结果(在GFLOPS中)
数据类型'single'的结果(在GFLOPS中)
mtimesbackslashfftmtimesbackslashfft.
Tesla K20C1005.83496.82131.462690.80783.38282.48
特斯拉C2075333.84246.1173.36696.37435.56163.04
GeForce GTX Titan213.31130.6995.013826.94514.20365.85.
GeForce GTX 680139.2694.6660.661463.78604.57223.48
GeForce GTX 670117.7381.7752.221165.37519.18201.95
方形住宅区K500085.4864.1741.00955.10451.36172.25
方形住宅区K400060.5749.6428.40663.63364.36128.24
方形住宅区K200028.7920.9313.90310.71141.5856.71
GeForce GT 64028.7921.1013.71314.82141.8559.29
主机PC38.9729.152.1079.2947.974.05
Quadro K60013.2410.386.31135.5771.1227.61
拥有物业的Cudadevice:
名称:'GeForce GTX Titan'
指数:1
ComputeCapability:“3.5”
万博1manbetxSupportsDouble: 1
DriverVersion: 5.5000
ToolkitVersion: 5.5000
maxthreadsperblock:1024
MaxShmemPerBlock: 49152
MaxThreadBlockSize: [1024 1024 64]
MAXGRIDSIZE:[2.1475E + 09 65535 65535]
SIMDWIDTH:32
TotalMemory:6.4421E + 09
freememory:5.9798e + 09
MultiprocessorCount: 14
ClockRatekhz:875500.
计算:'默认'
GPUOverlapsTransfers: 1
KernelExecutionTimeout: 1
CanMapHostMemory: 1
Device万博1manbetxSupported: 1
DeviceSelected: 1
对于获得最大500次递归的错误的人,尽量不运行应用程序,但只需键入gpubench()。对我来说,它的工作。
是否有关于参考结果统计是什么系统的信息?
我们决定使用GeForce GTX TITAN,而不是C2075,因为在规格上它应该优于C2075 ECC内存,但大多数人会关闭它,以获得更快的性能。但现在,当我运行测试时,特斯拉2075在我们的系统中几乎所有方面都击败了GTX,除了MTimes和FFT (SINGLE)。
特别是Backslash双倍,82GFlops在参考系统中为C2075的246比较非常失望。
还有谁有泰坦,可以分享他/她的成果吗?如果是,请发送一个PM。
当前版本的gpuBench与R2014a不兼容
最新版本R2014a的一些问题:
已达到最大递归极限500。使用set(0,'RecursionLimit',N)更改限制。要意识到超过你的
可用的堆栈空间可以崩溃MATLAB和/或计算机。
gpuBenchApp误差
谢谢马修,你是对的 - 我会得到这个修好的。
理想的定时应该使用timeit(用于主机)或gputimeit(用于gpu)来测量,但如果我开始使用这些,那么这将在R2013a和更早的时候停止工作。我很快会发布最新消息。
嗨,本,
我想对大型应用程序说感谢,也指出某些可能导致某些情况发生不准确的结果。函数gtoc()正在使用wait()函数(这是好的),但是每次都会调用gpudevice,这实际上非常慢 - 我的机器通常需要3.6和5.6ms - 这次被添加到总数。您可以考虑在持久变量中存储GPudevice的输出,例如,GPUID,而是呼叫等待(GPUID)。
对于大型阵列尺寸,我想它并不重要,但对于较小的数组来说,额外的GPudevice时间可以使它看起来像在它真的不是的CPU的情况下比CPU慢。
嗨,罗德里戈,
gpuBench不显示任何“加速”比较,它显示每秒浮点运算(FLOPS)的绝对性能。CPU的结果是单独的CPU的绝对性能结果,而不是作为比较。其他结果也是如此。预存储的“主机”结果是用于捕获结果的机器的绝对性能。
所有的图都包含GPU和主机PC的结果,所以文本应该说“这些结果显示GPU或主机PC在计算时的性能……”。我将解决这个问题。
谢谢
班
例如,如果我点击主机PC的结果,我看到
“这些结果表明了GPU计算时的性能......”
另外,为什么我的CPU有一个加速?大概是因为它在cpu数量增加的情况下使用并行计算,是这样吗?
本,
谢谢你的回答。如果我理解正确,GPUBench报告中高亮显示的GeForce GTX 770M是我自己的GPU的加速,主主机是我的CPU对预存储数据使用的CPU ?
我仍然不清楚结果告诉我什么。也许报告中应该包括更多的解释?
谢谢。
罗德里戈。
嗨,罗德里戈,
“主机”数据根本不使用GPU,它衡量的是你的PC的主CPU。因此,你可能只是看到我们使用了一个相当高规格的PC来承载我们测试的各种GPU(为了让GPU与CPU的比较更加公平)。
班
你好,谢谢你的精彩投稿!
我发现我的电脑(主机PC)比预先存储的数据中的完全相同的卡(NVIDIA GTX 770M)慢得多。是否有可能改善此问题的建议?纽约推荐阅读?
再次感谢,
罗德里戈。
嗨,迈克,我对bug报告出现在这里没有问题,因为这意味着其他人也可以看到它们。我能够重现问题使用一个新的MATLAB安装,我有一个修复工作。
作为一项工作,您应该能够在命令行中运行GPubench(只需键入“gpubench”) - 这只是应用程序启动器。
@Ben我已经通过FileExchange向您发送了详细信息。我一开始就应该这么做。请你或者Mathworks的人删除我的评论,这样我就不会把评论和评级线程弄乱,因为这是一个bug报告。很抱歉。
嗨,迈克。我刚刚尝试在R2013b和R2013a上下载并安装了这个应用程序,没有遇到任何问题。您能准确地描述一下您执行了哪些步骤,以便我尝试诊断问题吗?
这在过去一直良好工作,但今天在Dowloading并在Matlab 2013A中运行,我收到错误
已达到最大递归极限500。使用set(0,'RecursionLimit',N)更改
限制。请注意,超过您可用的堆栈空间可以崩溃MATLAB和/或
你的电脑。
gpuBenchApp误差
Great GPU应用程序展示GPU如何与他人进行比较。
贾斯汀,我也犯过类似的错误,就像你说的。我通过复制文件到不同的文件夹(c:\gpubench)和运行安装从那里修复。
在尝试在R2013A上使用您的应用程序时,我正在收到以下错误:
错误使用evalin
未定义的功能或变量'gpubenchapp'。
appinstall.internal.runapp>execute错误(第69行)
OUT =评估('呼叫者',[脚本';');
AppInstral.Internal.RunApp> RunApp13a(第51行)中出现错误
Outobj = Execute(fullfile(appInstalldir,[wrapperfile'app.m'])));
错误:appinstall.internal.runapp>runcorrectversion(第35行)
appobj = runapp13a (appinstalldir);
appinstall.internal.runapp错误(第17行)
Out = runcorrectversion(appmetadata, appendtrypoint, appinstalldir);
嗨andrei,
是的,您可以使用工具来实现这一点,尽管它不是那么简单。稍后我会考虑添加一种更方便的方法。
1.删除要使用的发布的数据文件(所以数据/ r2013a.mat如果使用最新版本)。
2.捕获和存储你感兴趣的每台机器/GPU的结果:
>> data = gpuBench();
>> gpubench.saveresults(数据);
这将构建一个特定于您的机器和正在使用的MATLAB版本的新数据文件。让我知道如果这对你不工作,或你有建议如何使这更方便。
干杯
班
正如描述中所述,GPUBench“生成一个详细的HTML报告,显示你的GPU性能与其他GPU预存储性能结果的比较。”尽管我对GPUBench非常满意,但我发现这个应用程序只允许与预定义的其他硬件集进行比较,这很奇怪。
相当典型的情况是,你的老板(或你自己)想要比较公司已经拥有的机器(例如,决定分配哪些比较用于开发,哪些运行发布版本,或者决定哪些计算机必须使用额外的处理器单元)。如果有机会在一台计算机上运行GPUBench,将基准结构保存到一个文件中,将该文件复制到另一台计算机上,并在另一台计算机上以将其数据添加到基准结构的方式运行GPUBench,那就再好不过了。因此,用户可以比较自己的电脑。
是在当前版本的应用程序中以某种方式实现这种模式吗?如果没有,它可以包含在未来版本中吗?
哇,这款应用真是太聪明了,竟然有自己的电脑和其他gpu。
如果遇到CUDA_ERROR_LAUNCH_TIMEOUT,请查看
//www.tianjin-qmedu.com/gputimeout.
它解释了如何更改系统设置以避免此操作。
嗨,本,
谢谢你的代码。
虽然我收到了这个错误。我知道它与超时设置有关,但不知道该从这里做什么。我的Quadro 1000M似乎没有加快我的FFT等。
警告:CUDA执行期间发生意外错误。CUDA错误是:
CUDA_ERROR_LAUNCH_TIMEOUT。
>在gpuBench 75
警告:CUDA执行期间发生意外错误。CUDA错误是:
CUDA_ERROR_LAUNCH_TIMEOUT。
>在gpuBench 75
警告:CUDA执行期间发生意外错误。CUDA错误是:
CUDA_ERROR_LAUNCH_TIMEOUT。
>在gpuBench 75
CUDA执行过程中发生意外错误。CUDA错误是:
CUDA_ERROR_LAUNCH_TIMEOUT。
误差在C: \程序
Files\MATLAB\R2011b\toolbox\distcomp\gpu\+parallel\+internal\+gpu\currentDeviceFreeMem.p>currentDeviceFreeMem
(第7行)
并行错误.gpu.cudadevice / get.freeMemory(第107行)
fm = parallel.internal.gpu.currentdeviceFreemem();
在gpuBench>getTestSizes错误(第371行)
freeMem=gpu.freemory;
gpuBench>运行时间错误
尺寸= getTestsize(类型,SeafficeFactor,设备);
gpuBench错误(第76行)
gpudata = runmtie(gpudata,reps,'double','gpu',progresstitle,numtaSks);
谢谢,
戴夫
嗨特里斯坦,
GPUBench每次只测试一个GPU。因为它只使用当前的设备,你可以使用“gpuDevice(n)”在调用它之前选择第n个GPU。然而,NVIDIA的驱动程序通常会默认先使用功能最强大的卡,所以如果你只得到最慢卡的结果,那就说明问题更严重了。你能试着做一下吗?
>> gpudeviceCount()
确保找到所有四个设备?然后你可以尝试
>>对于II = 1:GPUDEVICECOUNT(),GPUDEVICE(II),结束
打印出发现所有卡的详细信息。您需要确保所有这些都将“DeviceSupported”标志设置为1。万博1manbetx
我从未见过你报告的特定错误,并在NVIDIA的论坛上看他们说它很可能是由硬件问题引起的,并且一旦您击中它,您必须重新启动到完全刷新内存:
http://forums.nvidia.com/index.php?showtopic=204333
恐怕这听起来不太好!
让我知道你是怎么办的。
班
我尝试过运行基准测试。我的机器里有3辆特斯拉和1辆quadro。我注意到只有我的第四个GPU在使用。基准指数跌至19%,出现以下错误:
CUDA执行过程中发生意外错误。CUDA错误为:CUDA_ERROR_ECC_UNCORRECTABLE。
误差在C: \程序
Files\MATLAB\R2011b\toolbox\distcomp\gpu\+parallel\+internal\+gpu\currentDeviceFreeMem.p>currentDeviceFreeMem
(第7行)
并行错误.gpu.cudadevice / get.freeMemory(第107行)
fm = parallel.internal.gpu.currentdeviceFreemem();
在gpuBench>getTestSizes错误(第371行)
freeMem=gpu.freemory;
gpuBench>运行时间错误
尺寸= getTestsize(类型,SeafficeFactor,设备);
gpuBench错误(第76行)
gpudata = runmtie(gpudata,reps,'double','gpu',progresstitle,numtaSks);
谢谢你的帮助。
对于GPU来说是一个很好的基准