增强决策树的回归
在本例中,我们将使用UCI机器学习存储库提供的波士顿房价数据集探索一个回归问题。
文件名=“housing.txt”;urlwrite (“http://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data”文件名);inputNames = {“罪犯”,“锌”,“印度”,‘底盘’,“诺克斯”,“RM”,“年龄”,“说”,RAD的,“税收”,“PTRATIO”,“B”,“LSTAT”};outputNames = {“MEDV”};housingAttributes = [inputNames, outputNames];
文件保存后,您可以将数据导入到MATLAB作为表使用导入工具使用默认选项。或者,您可以使用以下代码,这些代码可以从导入工具自动生成:
formatSpec =' % 8 f % 7 f % 8 f % 3 f % 8 f % 8 f % 7 f % 8 f % 4 f % 7 f % 7 f % 7 f % 7 f % f % ^ \ n \ [r];文件标识= fopen(文件名,“r”);datalarray = textscan(fileID, formatSpec,“分隔符”,'',“空格”,'',“ReturnOnError”、假);文件关闭(文件标识);住房=表(dataArray {1: end-1},“VariableNames”,{“VarName1”,“VarName2”,“VarName3”,“VarName4”,“VarName5”,“VarName6”,“VarName7”,“VarName8”,“VarName9”,“VarName10”,“VarName11”,“VarName12”,“VarName13”,“VarName14”});%删除文件并清除临时变量clearvars文件名formatSpec文件标识dataArrayans;删除housing.txt
housing.Properties.VariableNames=housingAttributes;X=housing{:,inputNames};y=housing{:,outputNames};
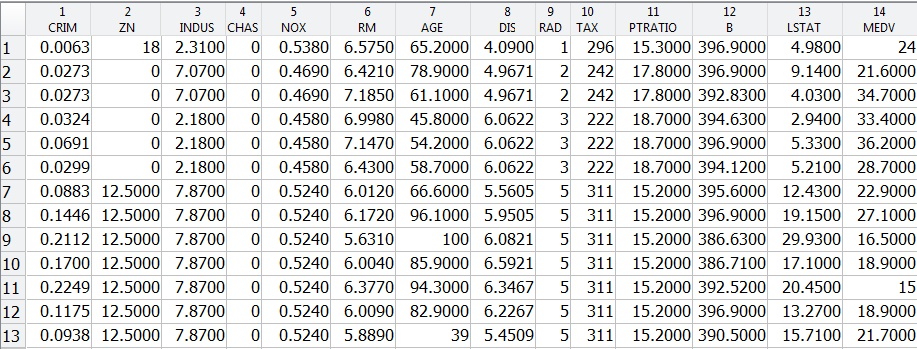
rng (5);%的再现性%留出90%的数据用于培训简历= cvpartition(高度(住房),“坚持”,0.1);t=RegressionTree.template(“MinLeaf”5);mdl = fitensemble (X (cv.training:), y (cv.training:)“LSBoost”,500,t,...“PredictorNames”inputNames,“ResponseName”, outputNames {1},“LearnRate”,0.01);L=损失(mdl,X(变异系数检验),y(变异系数检验),“模式”,“合奏”);流('均方测试误差= %f\n'L);
均方检验误差= 7.056746
图(1);%的阴谋([y (cv.training),预测(mdl X (cv.training,:))),“线宽”,2);图(y)(简历培训),“b”,“线宽”2)持有在…上图(预测(mdl X (cv.training,:)),' r . - ',“线宽”,1,“MarkerSize”15)%观察前100个点,平移以查看更多xlim([0 100])图例({“实际”,“预测”})xlabel(“训练数据点”);ylabel (“房价中值”);
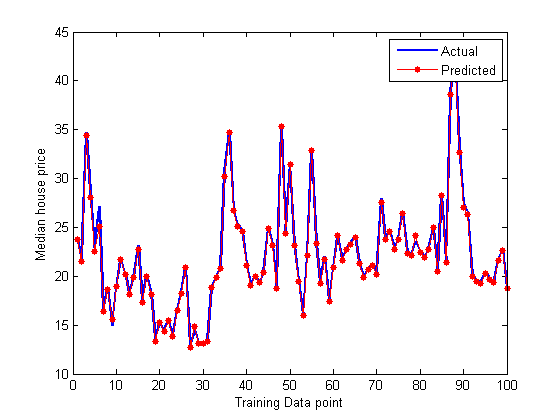
绘制按重要性排序的预测因子。
[predictorImportance, sortedIndex] = (mdl.predictorImportance)进行排序;图(2);barh (predictorImportance)组(gca,“ytickLabel”inputNames (sortedIndex))包含(“预测的重要性”)
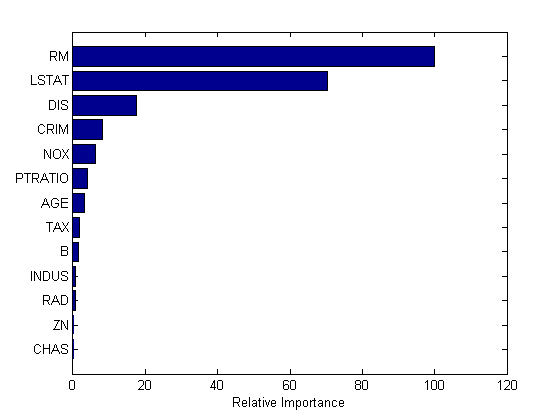
图(3);trainingLoss = resubLoss (mdl,“模式”,“累积”);testLoss =损失(mdl X (cv.test:), y (cv.test),“模式”,“累积”);情节(trainingLoss)在…上情节(testLoss“r”)({传奇“训练集的损失”,“测试集的损失”})xlabel(树木的数量);ylabel (的均方误差);集(gcf,“位置”,[249 634 1009 420])
我们可能不需要全部500棵树来获得模型的完全准确性。我们可以正则化权值并基于正则化参数进行收缩
为lasso尝试两个不同的正则化参数值mdl =调整(mdl,“λ”,[0.001 0.1]); disp(树木的数量:) disp ((mdl.Regularization求和。TrainedWeights > 0))
树数:194 128
使用λ= 0.1
mdl =收缩(mdl,“weightcolumn”2);disp (“收缩后的树木数量”) disp (mdl.NTrained)
收缩后培养的株数128株
当数据集很大时,使用较少数量的树和基于预测器重要性的较少的预测器将导致快速计算和准确的结果。
许可:BSD条款