强化学习工具箱
使用强化学习设计和培训政策
强化学习工具箱™提供了一个应用程序,功能,和一个Simulink万博1manbetx®块用于使用强化学习算法的培训策略,包括DQN、PPO、SAC和DDPG。您可以使用这些策略为复杂的应用程序(如资源分配、机器人和自治系统)实现控制器和决策算法。
该工具箱允许您使用深度神经网络或查找表来表示策略和值函数,并通过与MATLAB中建模的环境进行交互来训练它们®或仿真万博1manbetx软件。您可以评估工具箱中提供的单智能体或多智能体强化学习算法,或者开发自己的算法。您可以使用超参数设置进行实验,监控培训进度,并通过应用程序交互式或编程方式模拟培训过的代理。为了提高训练性能,模拟可以在多个cpu、gpu、计算机集群和云上并行运行(使用并行计算工具箱™和MATLAB并行服务器™)。
通过ONNX™模型格式,现有的策略可以从深度学习框架,如TensorFlow™Keras和PyTorch(与深度学习工具箱™)导入。你可以生成优化的C、c++和CUDA®编写代码,在微控制器和gpu上部署经过培训的策略。工具箱中包含了一些参考例子,可以帮助您入门。
开始:


强化学习算法
使用DQN (deep Q-network)、DDPG (deep deterministic policy gradient)、PPO (proximal policy optimization)等内置算法创建agent。使用模板开发培训策略的自定义代理。

强化学习工具箱中的训练算法可用。
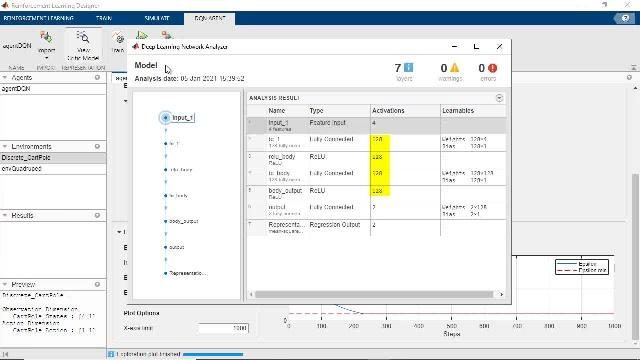

Simulink中的单agent和多agent强化学习万博1manbetx
使用RL Agent块在Simulink中创建和训练强化学习Agent。万博1manbetx使用RL Agent块的多个实例,在Simulink中同时训练多个Agent(多Agent强化学习)。万博1manbetx

Simulink的强化学习代理块。万博1manbetx
万博1manbetxSimulink和Simscape环境
使用Si万博1manbetxmulink和Simscape™创建环境的模型。指定模型中的观察、行动和奖励信号。

万博1manbetx一种两足机器人的Simulink环境模型。
MATLAB环境中
使用MATLAB函数和类来建模一个环境。在MATLAB文件中指定观察、行动和奖励变量。

三自由度火箭的MATLAB环境。
分布式计算和多核加速
通过在多核计算机、云资源或计算集群上运行并行模拟来加快训练速度并行计算工具箱和MATLAB并行服务器.

使用并行计算加速训练。
GPU加速
利用高性能NVIDIA加速深度神经网络训练和推理®gpu。使用MATLAB并行计算工具箱以及大多数支持cuda的NVIDIA gpu计算能力3.0或更高.

使用gpu加速培训。
代码生成
使用GPU编码器™从MATLAB代码生成优化的CUDA代码表示训练的策略。使用MATLAB编码器™生成C/ c++代码来部署策略。

使用GPU编码器生成CUDA代码。
MATLAB编译器支持万博1manbetx
使用MATLAB编译器™和MATLAB编译器SDK™将训练有素的策略部署为独立的应用程序,C/ c++共享库,微软®net程序集,Java®Python类,®包。

将策略打包和共享为独立的程序。
开始
了解如何为一些问题制定强化学习策略,例如反转一个简单的钟摆,在网格世界中导航,平衡一个车柱系统,以及解决一般的马尔可夫决策过程。
自动驾驶
为自动驾驶应用设计强化学习策略,如自适应巡航控制、车道保持辅助和自动停车。

水资源分配的资源分配问题。
产品资源:

强化学习系列影片
观看本系列的视频,了解更多关于强化学习的知识。

