统计和机器学习工具箱
分析和使用统计和机器学习模型数据
Statistics and Machine Learning Toolbox™提供用于描述、分析和建模数据的函数和应用程序。您可以使用描述性统计和图表进行探索性数据分析,将概率分布与数据相匹配,为蒙特卡罗模拟生成随机数,并执行假设检验。回归和分类算法使您能够从数据中得出推论并构建预测模型。
对于多维数据分析,统计和机器学习工具箱提供的功能选择,逐步回归,主成分分析(PCA),正规化,和其他降维方法,让您识别变量或功能会影响你的模型。
工具箱提供监督和无监督机器学习算法,包括支持向量机(SVM),升压和袋装决策树,k-最近邻,k均值,K-中心点划分,层次聚类,高斯混合模型,和隐马尔可夫模型。万博1manbetx许多统计和机器学习算法,可用于对数据集是太大而无法存储在内存中的计算。
开始:

可视化
视觉上探索使用概率图,箱形图,直方图,分位数 - 分位数图,以及先进的地块为多变量分析,例如树状图,二维图,并且图安德鲁斯数据。

使用多维散点图探索变量之间的关系。

使用分组方法和方差研究数据。
聚类分析
使用k-means、k-medoids、DBSCAN、分级聚类、高斯混合和隐马尔科夫模型对数据进行分组,从而发现模式。

将DBSCAN应用于两个同心组。
特征提取
提取物使用无监督学习技术,如疏滤波和重建ICA数据特征。您还可以使用专门的技术来提取图像,信号文本及数字数据的功能。

从移动设备提供的信号中提取特征。
特征选择
自动识别,在数据建模提供最好的预测能力要素的子集。特征选择方法包括逐步回归,连续特征选择,正则化,和集成方法。

NCA帮助选择保持模型的大部分准确性的特性。
特征变换和降维
通过将现有的(非分类的)特征转换为新的预测变量来降低维度,在这些预测变量中可以删除描述性较差的特征。特征变换方法包括主成分分析、因子分析和非负矩阵因子分解。

PCA项目很多变量在一些正交那些保留大部分的信息。
分类
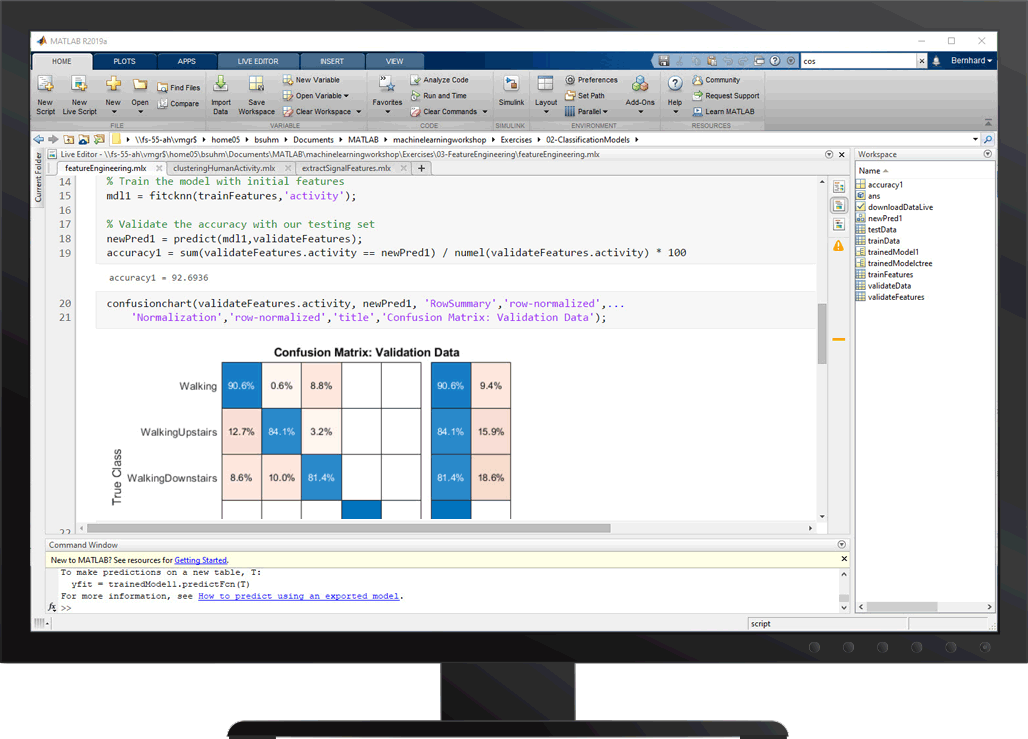
将分类响应变量建模为一个或多个预测器的函数。使用各种参数和非参数分类算法,包括逻辑回归、支持向量机、改进和袋装决策树、朴素贝叶斯、判别分析和k近邻。

与分类学习应用交互训练分类器。
自动化模型优化
通过自动调整超参数、选择特性和使用代价矩阵解决数据集不平衡问题来提高模型性能。

优化的超参数有效地利用贝叶斯优化。
线性和非线性回归
与多个预测或响应变量从许多线性和非线性回归算法选择复杂的系统模型的行为。配合多层或分层的,线性,非线性,以及广义线性混合效应模型具有嵌套和/或交叉的随机效果来执行纵向或面板的分析,重复测量和生长建模。

飞度回归模型交互与回归学习应用。
非参数回归
产生一个精确的配合,而无需指定,描述预测和应对,包括支持向量机,随机森林,高斯过程,和高斯内核之间的关系的模型。

使用分位数回归识别异常值。
方差分析(ANOVA)
将样本方差分配到不同的来源,并确定该方差是在不同的人口组内部还是在不同的人口组之间产生的。采用单因素、双因素、多因素、多因素和非参数方差分析,以及协方差分析(ANOCOVA)和重复测量方差分析(RANOVA)。

使用多路ANOVA测试组。
概率分布
适合连续和离散分布,使用统计图评估拟合优度配合,并且计算概率密度函数和累积分布函数为超过40点不同的分布。

飞度分布交互方式使用分配钳工应用。

假设检验
对单个、成对或独立样本进行t检验、分布检验(卡方检验、雅克-伯拉检验、利利福尔斯检验和柯尔莫戈罗夫-斯米尔诺夫检验)和非参数检验。测试自校正和随机性,并比较分布(双样本Kolmogorov-Smirnov)。

在单侧t检验拒绝区域。
试验设计(DOE)
定义,分析和可视化的实验,以定制的设计(DOE)。创建和测试实际计划如何串联处理数据输入生成有关他们的数据输出影响的信息。

套用箱Behnken法设计产生更高阶响应面。

监测使用控制图的制造过程。
可靠性和生存分析
通过执行Cox比例风险回归和拟合分布,可视化和分析有和没有截尾的失效时间数据。计算经验风险、幸存者、累积分布函数和核密度估计。

故障数据为“截尾”值的示例。
用大数组分析大数据
使用带有许多分类、回归和聚类算法的高数组和表,在不更改代码的情况下,在不适合内存的数据集上训练模型。


加快并行计算工具箱或MATLAB并行服务器™计算。
云计算和分布式计算
使用云实例,加快统计和机器学习计算。请在MATLAB在线整机学习工作流程™。

执行对亚马逊或Azure云计算实例。
代码生成
使用MATLAB编码器生成可移植和可读的C或c++代码,用于分类和回归算法、描述性统计和概率分布的推理TM。通过MATLAB函数块和系统块加速使用机器学习模型验证和验证您的高保真仿真。

有两种部署方法:生成C代码或编译MATLAB代码。
与应用程序和企业系统集成
将统计和机器学习模型作为独立的、MapReduce、Spark™应用程序、web应用程序和Microsoft部署®Excel®使用MATLAB编译器™的外接程序。构建C/ c++共享库、Microsoft .NET程序集、Java®类和Python®包使用MATLAB编译SDK™。

使用MATLAB编译器集成了空气质量的分类模型。

代码生成和模型更新工作流。

