在Basic Grid World中训练强化学习代理
这个例子展示了如何通过训练Q-learning和SARSA代理来使用强化学习解决网格世界环境。有关这些代理的更多信息,请参见q学习的代理而且撒尔沙代理.
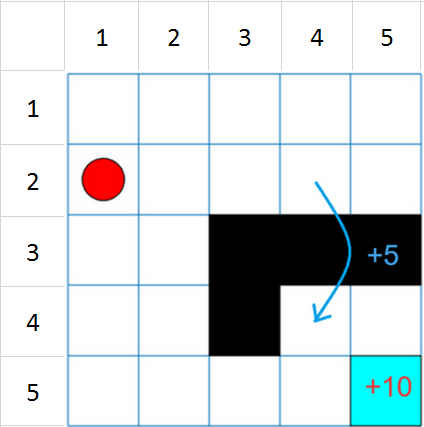
这个网格世界环境具有以下配置和规则:
这个网格世界是5乘5的,有边界,有四种可能的行动(北= 1,南= 2,东= 3,西= 4)。
代理从单元格[2,1](第二行,第一列)开始。
如果智能体到达单元格[5,5](蓝色)的终端状态,它将获得+10的奖励。
环境包含从单元格[2,4]到单元格[4,4]的特殊跳跃,奖励为+5。
药剂被障碍物阻挡(黑色单元)。
所有其他行动的奖励都是-1。
创建网格世界环境
创建基本网格世界环境。
环境= rlPredefinedEnv(“BasicGridWorld”);
要指定代理的初始状态总是[2,1],请创建一个reset函数,该函数返回初始代理状态的状态号。这个函数在每个训练集和模拟开始时被调用。状态从位置[1,1]开始编号。当您向下移动第一列,然后向下移动每个后续列时,状态号会增加。因此,创建一个匿名函数句柄,将初始状态设置为2.
env。ResetFcn = @() 2;
固定随机生成器种子的再现性。
rng (0)
创建Q-Learning Agent
要创建Q学习代理,首先使用网格世界环境中的观察和操作规范创建Q表。设置优化器的学习率为0.01.
qTable = rlTable(getObservationInfo(env),...getActionInfo (env));
要在代理中近似q值函数,请创建rlQValueFunction近似器对象,使用表和环境信息。
qFcnAppx = rlQValueFunction(qTable,...getObservationInfo (env),...getActionInfo (env));
接下来,使用q值函数创建q学习代理。
qAgent = rlQAgent(qFcnAppx);
配置代理选项,例如函数逼近器的贪心探测和学习率。
qAgent.AgentOptions.EpsilonGreedyExploration.Epsilon = .04;qAgent.AgentOptions.CriticOptimizerOptions.LearnRate = 0.01;
有关创建q学习代理的详细信息,请参见rlQAgent而且rlQAgentOptions.
培训Q-Learning Agent
要培训代理,首先指定培训选项。对于本例,使用以下选项:
最多训练200集。指定每个插曲最多持续50个时间步长。
当智能体在连续30集中获得的平均累积奖励大于10时停止训练。
有关更多信息,请参见rlTrainingOptions.
trainOpts = rlTrainingOptions;trainOpts。MaxStepsPerEpisode = 50;trainOpts。MaxEpisodes = 200;trainOpts。StopTrainingCriteria =“AverageReward”;trainOpts。StopTrainingValue = 11;trainOpts。ScoreAveragingWindowLength = 30;
训练q学习代理使用火车函数。训练可能需要几分钟才能完成。为了在运行此示例时节省时间,请通过设置加载预训练的代理doTraining来假.要亲自训练特工,请设置doTraining来真正的.
doTraining = false;如果doTraining培训代理。trainingStats = train(qAgent,env,trainOpts);其他的为示例加载预训练的代理。负载(“basicGWQAgent.mat”,“qAgent”)结束
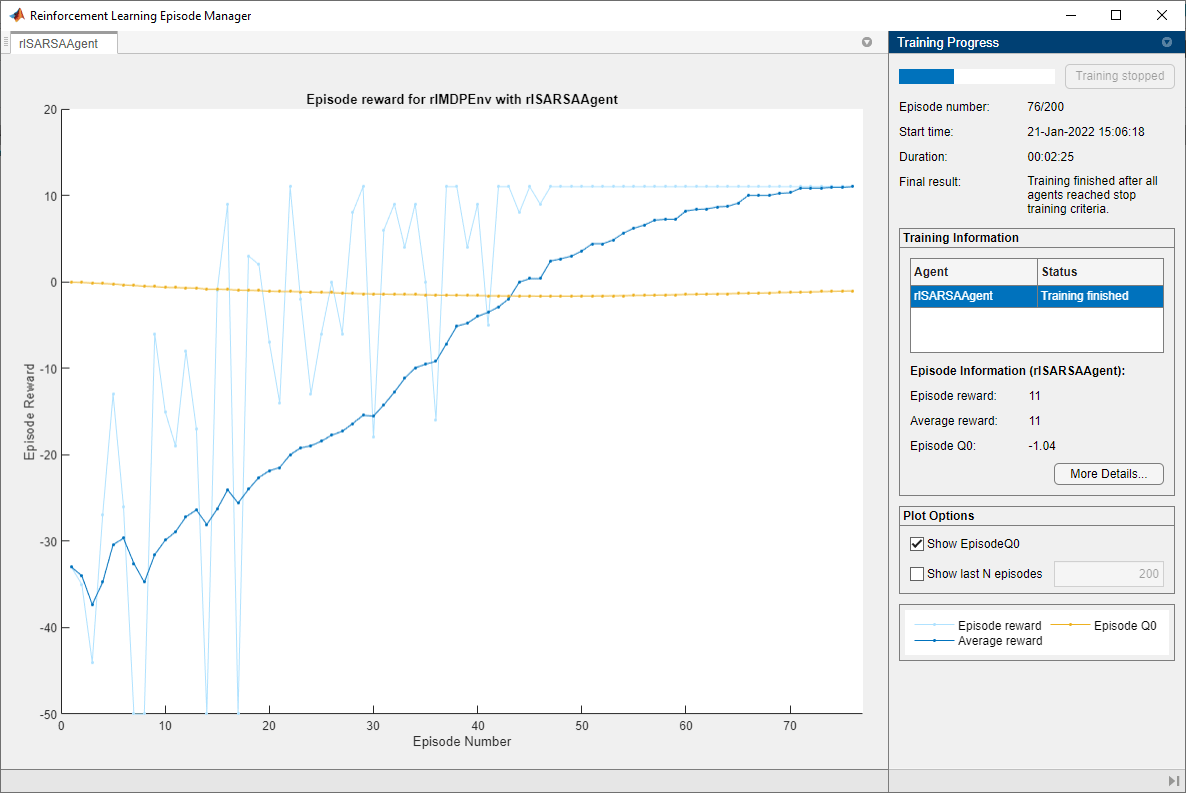
的事件管理器窗口打开并显示训练进度。

验证Q-Learning结果
为了验证训练结果,在训练环境中对智能体进行仿真。
在运行模拟之前,可视化环境并配置可视化以维护代理状态的跟踪。
plot(env) env. model . viewer . showtrace = true;env.Model.Viewer.clearTrace;
类在环境中模拟代理sim卡函数。
sim (qAgent env)
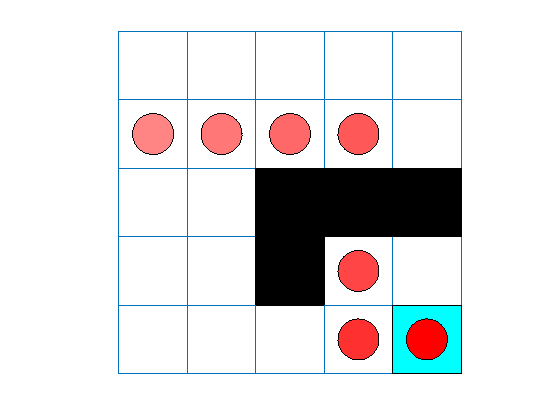
代理跟踪显示代理成功地找到了从单元格[2,4]到单元格[4,4]的跳转。
创建和训练SARSA代理
要创建SARSA代理,请使用与Q学习代理相同的Q值函数和贪心配置。有关创建SARSA代理的详细信息,请参见rlSARSAAgent而且rlSARSAAgentOptions.
sarsaAgent = rlSARSAAgent(qFcnAppx);sarsaAgent.AgentOptions.EpsilonGreedyExploration.Epsilon = .04;sarsaAgent.AgentOptions.CriticOptimizerOptions.LearnRate = 0.01;
训练SARSA代理使用火车函数。训练可能需要几分钟才能完成。为了在运行此示例时节省时间,请通过设置加载预训练的代理doTraining来假.要亲自训练特工,请设置doTraining来真正的.
doTraining = false;如果doTraining培训代理。trainingStats = train(sarsaAgent,env,trainOpts);其他的为示例加载预训练的代理。负载(“basicGWSarsaAgent.mat”,“sarsaAgent”)结束
验证SARSA培训
为了验证训练结果,在训练环境中对智能体进行仿真。
plot(env) env. model . viewer . showtrace = true;env.Model.Viewer.clearTrace;
在环境中模拟代理。
sim (sarsaAgent env)
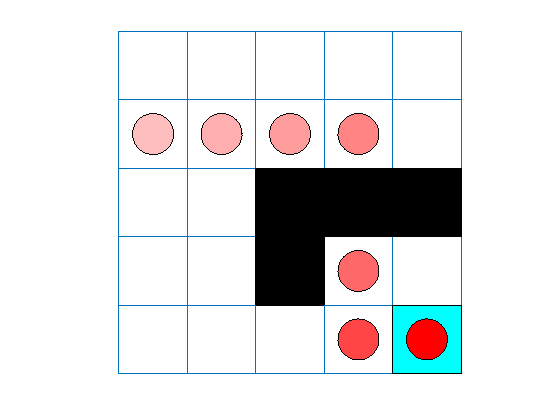
SARSA代理找到与q学习代理相同的网格世界解决方案。
另请参阅
相关的话题
您也可以从以下列表中选择一个网站: