欢迎参加SimBiology药物开发建模与仿真网络研讨会。我叫Sietse Braakman。我是MathWorks计算生物学的高级应用工程师。我在北美各地工作,帮助我们在学术界和制药行业使用SimBiology的所有客户。
在今天的网络研讨会上,我想给大家概述一下SimBiology是如何用于建模和药物开发的,然后我们将继续进行一个案例研究,研究SGLT2抑制是否可以成为治疗2型糖尿病的一种可行疗法。这将包括建立一个室间和机制模型,模拟“如果”场景,以调查抑制SGLT2是否会是一个好的治疗,然后也进行参数扫描。最后,我们还将估算参数,以校准我们的模型与数据。
之后,我将简要地向您展示如何使用Web Apps共享模型和模拟,比如使用SGLT2抑制模型的模型。网络应用程序基本上是MATLAB和SimBiology中的应用程序,你可以通过网络浏览器与同事分享。最后,我们将结束节目,接下来是问答环节。
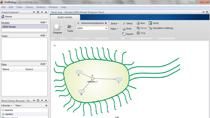
首先,我想给大家简要介绍一下SimBiology,并激发大家对如何使用SimBiology的兴趣。这里我们看一下SimBiology模型构建程序我们有一个代表数学模型的图表。这个图表由不同的部分组成。左上角是SGLT2抑制剂的药代动力学。在右上角,你可以看到葡萄糖的吸收机制。中间是血浆和葡萄糖的调节。在底部你可以看到胰岛素调节。左边是一些记账。
我们的想法是,这个特别的模型背后——SimBiology根据那个图表创建了一组微分方程。所以在这里你可以看到从那个图表推导出来的方程式以及我们提供给SimBiology的所有信息。这使得SimBiology可以创建一系列微分方程和代数方程。
现在,一旦我实现了这个模型,我还可以使用这个模型。所以我可以进行模拟,得到这样的结果。所以我刚刚在一个参考虚拟病人中模拟了这个模型,有和没有SGLT2抑制剂——一个2型糖尿病虚拟病人。你可以看到,如果没有治疗,你可以看到PK是平的。如果使用了SGLT2抑制剂,你可以看到抑制剂每天都在使用。
然后你可以看到虚线,你比较虚线,所以SGLT2抑制剂和实线,没有使用抑制剂。你可以看到通过尿液排出的葡萄糖显著增加。然而,这并没有非常非常显著的影响。它会在一定程度上降低血糖浓度,但不会低于一般可接受的正常水平。这就是快速调查的方法,在这种情况下,SGLT2抑制剂是否是治疗2型糖尿病的可行疗法。这方面还有很多内容我们会在案例研究中更详细地讲解。
所以SimBiology被用于药物开发,我认为了解不同的建模方法在药物开发中是如何被使用的以及它如何与药物开发里程碑相一致是很重要的。所以,一般来说,我们可以考虑三个主要的里程碑。发现阶段,确定药物靶点。一旦我们确定了一个靶点,我们就开始进行临床前研究,我们试图了解药物是否达到了一个靶点,我们能否找到一个适合首次人体研究的剂量。所以当我们在临床研究中评估药物的安全性和有效性并确定目标人群时。
在这些不同的里程碑上,使用了不同类型的模型。所以在早期,你可以使用一个机制系统生物类型模型来识别药物靶点。一旦进入临床前和临床研究,就会使用药代动力学,药代动力学模型和/或基于生理学的药代动力学模型。最后,还有定量系统药理学,它连接了从发现到早期临床研究之间的距离。定量系统药理学的观点是它们是包括治疗和病理生理学的机制模型。
考虑到这是在药物开发中建模和模拟的竞技场。SimBiology背后的想法基本上是允许用户将SimBiology用于所有这些里程碑和所有这些建模方法,既用于模型构建模拟,也用于其他高级工作流,如参数估计,灵敏度分析,等等。这就是《模拟生物学》背后的想法。现在,你可能会想——我的意思是,我已经简单地向你展示了模拟生物学是什么样子的,但也许我们可以更好地解释什么是模拟生物学。
所以SimBiology提供应用程序。这就是我之前展示的两个应用模型构建器和模型分析器,以及编程工具。如果你愿意,你可以编程地使用SimBiology。这样你就可以通过这个图来建立你的模型,这样你就可以像画它一样来建立它。一旦实现了模型,就可以对其进行模拟。你可以通过估计参数来进行校准。你可以做进一步的分析,像蒙特卡洛模拟或灵敏度分析。
SimBiology是建立在MATLAB之上的你可能知道MATLAB是一种编程语言。这种语言构成了MathWorks所有产品的基础,包括SimBiology。s manbetx 845所以我们要确定的是,所有的产品,包括MATLAB,包括SimBiology,都经过严格的测试,维护,每半年更新一s manbetx 845次,以确保所有东西都能协同工作。
现在,当你听说MATLAB时,你可能会想,嗯,实际上我没有任何编程经验,我需要了解MATLAB才能使用SimBiology吗?答案是否定的。在MATLAB中,您不需要任何编程经验,因为SimBiology有图形用户界面,这意味着您不必编写任何代码。所以你只有在你想的时候才需要这么做。
SimBiology位于MATLAB之上,是一个工具箱,它允许你有这些基于应用程序的和程序化的工作流程。它有这些内置的分析工具。然后,通过编译到c代码,模拟也会加速。在《模拟生物学》中,你有项目。所以SimBiology项目包含了你为某种疗法开发的模型,例如,你正在开发的。然后是用于参数估计的数据集,抱歉,是用于校准模型的参数估计的数据集还有你用这些数据集和模型所做的程序和分析。
这些项目的优点是它们是一个单独的文件,你可以在SimBiology中打开。你可以把它传给同事,他也可以在SimBiology上打开它。它促进了结果的连续性和再现性,它还有我之前展示过的图形模型表示。这种图形化的模型表示非常适合于帮助您将模型与两个合作者进行交流。
现在。SimBiology在整个工业和学术界都有应用,这里有一些用户如何使用SimBiology进行他们自己的药物开发的例子。首先,这是一个来自基因泰克的例子。研究小组希望更好地了解药物诱导的骨髓抑制,这通常会导致药物损耗和癌症治疗。因此,基因泰克的Wilson等人开发了体外造血的QSP模型。该模型使用细胞动力学和数据进行校准,没有进行治疗,并根据已发表的药物反应进行验证。然后用它来预测由这些新化合物诱导的骨髓抑制的程度。
另一个例子是艾伯维的Klausnitzer等人的模型,他们发表了阿尔茨海默病背后的分子机制的全面模型,特别关注胆固醇和鞘脂的失调。该模型捕获了文献中发表的阿尔茨海默病患者中几个生物标志物的调节和药理反应。它被用来评估靶向S1P受体5以及一种治疗阿尔茨海默病的新疗法。
最后,葛兰素史克的Sepp等人利用SimBiology的能力以编程方式构建模型,以自动化大型双孔PPK模型的组装,该模型使用扩展的组织分布时间过程数据集进行参数化。模型装配的自动化帮助他们大大减少了建立模型所减少的时间。
所以我希望这能给你们一些SimBiology是什么以及它在行业中的应用。现在,我想继续这个案例研究,我们研究抑制SGLT2作为2型糖尿病的治疗方法。
考虑一下这个假设的情况。在过去的几年里,SGLT2疗法还没有获得批准,我的制药公司正在研究2型糖尿病疗法的新靶点。SGLT2是其中一种疗法,一种可能很有前途的途径。
抑制SGLT2背后的想法是,在正常情况下,你的血浆通过肾小球过滤。滤液在肾脏中被重新吸收回到血浆中这包括葡萄糖。葡萄糖通过SGLT2途径被重新吸收回到血浆中。如果我们能抑制SGLT2,那么也许更少的葡萄糖会被重新吸收更多的葡萄糖会通过肾脏排出,通过尿液排出,这实际上会降低血浆葡萄糖浓度,因此,可能在一定程度上减轻影响和2型糖尿病的共病。
现在,这里的研究问题是SGLT2的抑制是否会导致血浆葡萄糖水平的显著降低?在这个假设的情况下,作为一个建模师,我有四周的时间来调查SGLT2目标的可行性。我没有初步的数据,我必须对这种疗法的PK概况做假设。然而,我可以建立现有的血糖-胰岛素调节模型。而且,我必须再次指出,这个模型是为了内部决策,而不是为了支持监管提交。万博1manbetx所以这只是为了调查我的公司是否应该继续研究抑制SGLT2的方法。
我将使用的模型是由Dalla Man Camilleri和Cobelli所建立的,他们开发了一个描述葡萄糖-胰岛素调节的机制模型。这里的SGLT2疗法被添加到葡萄糖-胰岛素调节中是由我们的合作伙伴Rosa和公司合并的他们是一家QSP咨询公司。我们的目标是要有一个说明性的例子。所以,正如我所说,这是一个假设的情况,当然,它只是演示如何使用SimBiology创建一个QSP模型并回答某些问题。
所以Rosa和Co.他们研究了SGLT2对尿葡萄糖排泄的影响。他们描述了模型的PK和其他参数,如IC50。当然,这些值都是假设的,因为没有具体的PK可以进行,至少在假设的情况下没有。然后他们还给我们提供了两个虚拟参考病人,一个健康的和一个2型糖尿病患者。这里的想法是,罗莎和公司根据观察到的临床数据,对这两个虚拟病人进行了鉴定,以确保这些病人确实代表了一个健康的受试者和一个2型糖尿病患者。
现在,有一些假设和限制。首先,Dalla Man等人确实充分展示了葡萄糖-胰岛素的调节,但只是短期的几天的调节,所以没有任何长期的影响你会看到HbA1c或其他东西。这并不包括在这个模型中。所以我们可以用它来研究短期效应。
让我们转到SimBiology,开始研究这个模型。为了开始学习SimBiology你可以从MATLAB开始。这里你看到MATLAB,我们有Home选项卡,然后是Apps选项卡,SimBiology,模型构建器,和一个模型分析器app可以在Apps选项卡中找到。
如果我打开SimBiology模型分析器,你会看到我之前展示的模型。但今天我要用达拉曼的论文,那里还没有SGLT2疗法。所以我要做的是我要把SGLT2疗法包括在这里然后把它和肾排泄率联系起来。这就是我接下来要做的。
现在,我们能把PK部分结合起来的最简单的方法——在这种情况下,PK部分将是一个隔室模型。最简单的方法就是使用SimBiology的PK库。所以你可以从PK库中加载一个模型,你可以看到有一个,两个,三个单元模型,具有不同的剂量和消除类型。在这种情况下,我们将使用一个单室模型我们假设治疗是口服的,所以它是一级给药,然后我们有线性消除率和体积。我选择这个,然后点击确定,这就得到了我的单隔间模型。现在我可以研究这个模型了。
举个例子,如果我点中央,那是单隔间中央,我可以看到那个隔间的值是1l。对于我们的治疗来说,必须是6升。我们要把它设为6升。我还可以看看吸收率。所以剂量以ka的速率被吸收到药物中心我也可以给它一个值。在这个例子中,它是0.03单位是1 /分钟。然后我可以用同样的方法计算消去率,所以ke是0.003,时间是1 /分钟。
现在我们已经定义了这个单室模型,我可以很快地看一下方程。所以对于中心剂量,中心剂量的变化等于负的中心吸收。药物中枢的变化是积极的,吸收,和消极的,消除。你在这里看到的蓝色部分是物种。这些代表蓝色的长方形这些是微分方程的左边。橙色的部分是反应或通量。这里你可以看到通量。这些是反应,这些代表了,微分方程右边的项。
现在我要做的就是复制这个。有一件事你需要确保,如果你去复制选项,你在复制时设置。你设置所有这些为真,这将确保它复制整个东西。我要选中所有这些部分然后点击复制。然后切换到另一个模型把它粘贴到这里。这里我可以点击粘贴现在我的模型在另一个中,我的单室模型被添加到Dalla Man模型中。你可以看到它也包含了ka和ke的参数。
所以我现在把我的药代动力学包括进来了,这很好,但是这个模型还没有和血糖调节联系起来。我必须把药物浓度和肾脏排泄率联系起来。如果我再次点击这个反应这个反应就决定了右手边的血糖。
葡萄糖是一个物种。如果我点击肾脏排泄,你可以看到反应速率。这个反应速率的定义是,如果血浆葡萄糖高于某个基础肾脏阈值,那么就会有葡萄糖排泄。葡萄糖排泄等于肾小球滤过率乘以血浆葡萄糖和基础肾脏阈值之间的浓度梯度。
我在这里加了一个药物效应术语。这个药物效应项目前只有1。所以我要做的就是定义药物的作用依赖于我的药物中心这样我就可以把药物中心和我的肾脏排泄联系起来。
在《模拟生物学》中,你的方法是使用重复分配。重复作业基本上就是代数方程。这里是重复作业的表格。我可以简单地写一份关于药物效应的重复作业。
所以我说药物效果等于1减去Imax乘以?central.drugcentral。在这种情况下,希尔系数是2。然后除以IC50平方减去中心[?点。然后你也可以看到我按Tab键,然后我可以自动完成这个。再一次,我们需要平方。然后我就做完了。
现在,我这样做了,我在这里把Imax设为红色,我有一个红色指示器。这是SimBiology告诉我,嘿,有些地方出了问题。我可以到这里的模型评估工具,验证我的模型。当我验证它时,它说我们发现了一个错误,这个错误是Imax不涉及任何物种参数或隔间,所以基本上Imax没有被定义。
这就是我要做的。我可以到这里的参数表,点击Imax。我说Imax是一个参数,它的值是0.65,单位是无量纲的。现在如果我验证我的模型,模型中没有错误或警告。
我已经把PK和PD联系起来了,但在图中还看不出来。这是我还想做的一件事。这是我的药物效果现在我要做的是,我可以到我的肾排泄反应,我可以说,显示表达线,然后你得到一个虚线的药物效果。然后我可以重复做同样的事情,画出反应线。所以现在我可以看到药物的作用将药物中心浓度和实际排泄率联系在一起。
这个案例研究的模型构建部分就讲到这里。我们现在可以看一下方程。同样,我们可以选择嵌入到通量上,但是在这里您可以很好地看到每个通量都有不同的名称。所以有研磨,排空,胰岛素分泌,等等。然后你可以看一下ode,你可以看到所有的通量,例如,血浆葡萄糖。
还有两件事我还没有在《模拟生物学》中向你们展示,它们在后面会非常有用。第一个是剂量。在《模拟生物学》中你可以定义剂量。在这种情况下,我们定义了三餐的剂量,早餐,午餐和晚餐,以及SGLT2抑制剂。
对于SGLT2抑制剂,我们的剂量是300毫克,起始时间是60,所以是1小时。然后间隔是1440,也就是一天,重复7次。所以SimBiology的剂量可以混合和匹配。你可以同时有多个应用,他们允许你快速探索不同的剂量制度。
另一件有趣的事是,我们称之为修饰剂的剂量,它会修改你的模拟结果。其他修饰语是变体。变量的概念是你的模型结构和微分方程可能是一样的,但模型可以描述不同类型的,例如,不同的表型,不同的物种,不同的药物作用,所以你可以在一个变量中捕捉到这些。因为变量是模型的不同参数化。
因此,在这种情况下,2型糖尿病患者的GFR可能与健康患者不同,因为2型糖尿病会降低肾功能。这就是这两个虚拟参考病人都保存在一个变量中,我们可以将这些模型——这些值应用到模型中来模拟和表示一个健康的病人或一个2型糖尿病病人——一个健康的人或一个2型糖尿病病人。
这些就是我们在模拟模型时要用到的变量。到目前为止,我们已经在SimBiology模型构建器中工作了,现在我要转到另一个应用,模型分析器,来做模拟。
这里我们看到了之前的模拟。我要创建我自己的模拟,模拟叫做程序。所以程序有很多种,模拟就是其中一种。
我可以重命名这个程序。我可以说这是一个单一的模拟。现在我可以一步一步地看一下我想要模拟的是什么。所以我想模拟的模型是Physiopedia平台[?]网络研讨会?][?空的。这是我们刚刚在《模型构建者》(Model Builder)中研究的,是的,《物理百科》[?]网络研讨会?][?空的。?]
然后我可以应用变量。在本例中,我将应用2型糖尿病患者和剂量。所以,在这种情况下,我将只使用食物,但不使用抑制剂,只是看看2型糖尿病患者的基线反应是怎样的。
我还可以定义模型中的状态,也就是我想记录的物种。在这种情况下,我只想把这四种物种的对数记录下来。我想在10080分钟后停止模拟,也就是7天。让我们运行这个模拟,这是我们的图。
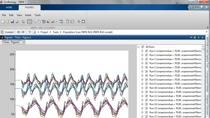
我们看到了四种反应。它们都有不同的颜色这是因为它们是按颜色切片的。这里的切片,有响应。现在,因为黄色反应的值是血浆葡萄糖浓度,AUC,太高了,我看不到其他的。我能做的就是把它们画在网格上。
如果我这样做,我可以在它自己的图中单独看到每个响应。然后我就可以看看尿葡萄糖排泄的基线是什么。所以你可以看到在基线-没有SGLT2抑制似乎有一些合理数量的AUC-通过肾脏的葡萄糖排泄。我们可以看到血糖浓度很高。任何高于180毫克的东西,我想,一般来说,每分升180毫克就被认为是高血糖水平。这个病人的血糖水平明显偏高。
在右下方你可以看到中心的药物浓度,它是平坦的。目前还没有用药。但现在我能做的是,我可以加入药物,我可以保留没有药物的模拟结果,然后我可以比较两者。我们来做一下。我们加入药物,然后再次进行模拟。
现在我们可以看到,一旦我们加入了SGLT2抑制剂,在红色的部分,你可以看到有抑制剂的糖尿病虚拟患者,在蓝色部分,你可以看到没有抑制剂的患者。你可以看到有一个显著的增加,大约是尿葡萄糖排泄的两倍,还有一个,不是很大,但在血浆葡萄糖水平有一个小的下降。当然,你也可以看到,SGLT2抑制剂正在被使用。
现在,我们在这里看到的是一个小的影响,但是,当然,有一些因素会影响抑制剂的大小-抑制的效果其中之一就是GFR。
如果我们回到这个图表,我们可以看一下药物的肾排泄如果我们看一下肾排泄,你可以看到GFR基本上限制了药物的总效果。所以如果我们增加GFR会发生什么是很有趣的。我们会看到更大的影响吗?所以我们可以回到模型分析器,我们可以实际调查GFR的值。
这是GFR。我可以为GFR创建一个滑块,看看会发生什么,例如,如果我将值更改为0.01而不是[?0.0- ?] [?或者?][?05.所以现在我可以用GFR的新值再次模拟模型。然后你会看到药物效果会比没有GFR值的情况下增加得更多。
当然,GFR不是你可以设计的。那是病人的财产。但重要的是要明白,如果病人的GFR很差,那么这种疗法可能不会很有效。
我们能影响的另一件事是IC50药物的消除率和药物的吸收。所以也许我们现在能做的就是探索这些因素。我们这样做的方法是,我们可以扫描这些参数看看对被排出的最大葡萄糖量有什么影响。
所以我可以在我的项目中添加这个程序的一个副本我们叫它Explore IC50和ke。这是相同的程序,但是这里有一个加号这个加号允许你在模拟程序中添加步骤。其中一个步骤是生成样本步骤它的作用是根据参数值或初始条件生成样本然后用这些备选值——这些抽样值来刺激模型。
我感兴趣的是IC50和ke我可以把IC50作为一个组件拖过来对ke也是一样的。所以,在这种情况下,我扫描-我生成样本的数量,但它也可以是一个剂量或变异,我想探索。假设我想用每个不同的变量来模拟我的模型,我可以这样做。
这里我将使用用户定义的值,但你也可以从分布中抽样比如从正态分布中随机抽样。我将使用10到190之间的线性空间的取值范围我将取5个样本。然后是ke,我将做类似的事情,在0.001到0.01之间进行线性抽样,同样是在5个样本中。
现在我要做的是我要做一个笛卡尔参数组合。我将模拟这个模型将这个的每一个值和那个的每一个值结合起来,我将有25个不同的样本。
这些步骤背后的想法是你可以单独运行它们,你可以显示任何图或[?我不打算显示图,但我要生成样本——一步的输出形成下一步的输入。现在我可以运行这个模拟了,因为我已经生成了样本。现在它将模拟这25个样本的模型这里我省略了这里的图。
但是我选择的是这些可观察的——可观察的是构建SimBiology,它允许你在模拟完成后计算一些东西。作为目标结果的整体衡量标准。所以,在这种情况下,我取尿液AUC的最大值这就是我想要比较的每个样本的输出值。
这是我的程序,我可以看看上次运行的结果。这些是我们生成的样本。当生成样本时,这些是我的样本。然后我还可以看标量。标量是这个,这是你们看到的最大尿液AUC,因为这是每个模拟的单一值,我可以用图矩阵将它们可视化。
我选择标量,选择图矩阵,然后得到我的结果。所以在这里你基本上可以看到这些点代表我们采集的不同样本你可以看到这25个样本的最大尿液AUC。所以,在这种情况下,很明显,如果我们有一个低的IC50和一个低的ke,我们将看到我们的治疗的最高效果,因为,在这种情况下,药物的效果是最高的以及药物的AUC是最高的,如果我们有一个低的ke。
但是,在你的情况下,你可能会考虑一种联合疗法或一种疗法,在那里可能有一个甜蜜点,执行这种扫描真的可以帮助。假设我的公司有兴趣进一步探索这种疗法,并开始开发一种化合物,我们现在有了一些数据。现在我能做的是,一年过去了,我仍然有这个模型,我们有数据,让我们看看能否根据数据校准模型。
在这个例子中,我可以从文件中加载数据,这是一个Excel表格,它实际上只有PK数据,你可以看到浓度和剂量。目前我没有警局的任何资料。当然,我也可以有PD数据。现在的思想是我们最终要定义因变量和自变量。如果我想,我可以加单位。
SimBiology可以确保你的模型和数据之间的单位是一致的这样你就不会犯任何数量级的错误。所以我们有了数据,但是,当然,我们仍然不知道这些数据是否完全代表单室模型——单室模型是否能很好地拟合这些数据。
让我们先把数据可视化。如果我点击这里的校准数据并选择一个时间图,我们就会得到这个数据的一个图。如果我们在符号学尺度上画出来,你可以看到有一个明显的线性消除和一些吸收阶段。因此,对这些数据拟合一个单室模型是合适的。
这就是我们现在要做的。我们将创建一个叫做fit data的程序来让我们的模型与数据相匹配。我先选择数据集,然后再选择模型。我将使用单隔间模型。
下一步我们需要做的是映射数据集中的列。请记住,这是我们的数据集中的四个列名,分别对应模型中的各个部分。ID列表示组。我们的数据集中有9个研究对象。你可以在这里看到。
时间是自变量浓度是因变量。这代表[?]central.drugcentral。?]中央。剂量代表目标,所以这是剂量中心因为这是口服剂量。这将允许SimBiology为你创建目标函数,然后我们需要做的唯一一件事是我们需要定义我们想估计的参数和我们想使用的估计算法。
这里,我将使用非线性回归,固定效应,但你也可以使用混合效应随机求解器混合效应。对于这两者,您将需要统计和机器学习工具箱。然后用比例误差模型进行合并拟合。
我将使用lsqnonlin,它是优化工具箱的一部分。lsqnonlin为最小二乘局部优化算法。我也可以使用全局求解器,全局优化算法,比如分散搜索或粒子群,但这个问题太直接了,没有必要这么做。我们将使用lsqnonlin。
最后,这里可以看到,我还可以加上其他步骤其中一个步骤是置信区间。我要计算这个参数估计的置信区间,也要计算这个预测的置信区间。
我要运行这个。你看这里也有一个按钮用来平行。举个例子,如果你要用Bootstrap做置信区间,那是并行性很好的东西。如果你做全局优化,你也可以并行化它。因此,只要点击一下机器上的按钮,就可以很容易地加快这些过程。
现在,这里你看到的是我们迭代优化过程中的进度图。我们做了7次迭代你可以看到对数似然的值,我们想要最大化,一阶最优性,我们想要最小化,你可以看到每个参数var的值从我们给出的初始估计值到最终估计值的变化。现在我们有了一组诊断图的参数。
我们可以看看拟合图,很明显,这是一个拉拟合,所以只有一个模拟需要通过所有的点,这似乎是一个合理的拟合。我可以观察观察到的和预测的,理想情况下,如果我们的模型是完美的,所有这些点都在这条直线上,这条直线看起来已经很好了。残差与时间的关系我们要确保残差在这个0上是均匀分布的否则,你可能。在时间早期我们可能低估了,或者,低估了真实值。
我们可以看残差,残差的分布红线代表正态分布。如果这些点在这条直线上,那么你可以假设残差近似正态分布。然后我们还可以看置信区间,这是每个不同参数的置信区间。这些是高斯置信区间,所以事后处理。这不是Bootstrap或配置文件可能性置信区间。但看起来我们对每个参数都有相当的信心。
我们可以用同样的方法来做预测。你可以看到这里的预测是——这基本上是95%的置信度。给定这个数据和这个模型,模型响应将在蓝色区域内。
就像我说的,目前我们只是我们只是估计PK参数。但是,当然,如果你的数据集中有一个PD响应,你也可以估计模型中的PD部件参数。这个案例研究到此结束。让我们回到幻灯片,把它结束。
因此,本模型支持抑制SGLT2的可行万博1manbetx性。这不是一种击倒疗法。显然,这似乎只对GFR较高的值有效。所以你可能需要考虑到你的病人群体。我们可以设计出这样的化合物让它发挥最大的作用。
现在,这里的限制是这个模型没有捕捉到完整的群体反应或长期的内稳态。因此,它实际上只是用来通知那些早期的开发决策。我希望这个例子能让你了解如何在SimBiology中实现模型,以及如何使用该模型来回答你的问题,并根据数据校准你的模型。
现在进入下一部分,比如说,您想要与您的同事共享您的模型和模拟功能。这些同事可能不是建模师,他们可能是生物学家,但他们想要摆弄你的模型。你是怎么做到的?你可以用网络应用来做这些。
向你展示什么是web app最简单的方法就是向你展示web app。这是一个web应用,你可以看到我在浏览器中,这个地址是MathWorks VPN中的一个服务器。它只存在于互联网上,MathWorks之外的任何人都无法访问。
服务器是通过VPN连接的,服务器在慕尼黑。我唯一需要的就是这个的链接,这样我就可以登录,然后我就可以摆弄这个模型了。所以我可以看到增加Imax的效果或者降低IC50的效果以及增加肾小球滤过率的效果。
这样,我就能系统地探索这个模型,我就能知道重要的参数是什么,作为一个模型,你可以决定,你想要包含什么滑块,你想要包含什么图,等等。所以这是一个与你的团队分享你的模型和发现的好方法。
简单地说,你是创建这些应用的人然后你传达给这些模型用户你分享这些应用。在MATLAB中,你使用App Designer,所以你需要对写代码很熟悉。然后你可以创建这些应用程序,把它们打包,放在服务器上,然后你得到一个链接,你可以和你的同事分享。
现在,还有更多的事情要做。我们可以更详细地讨论这个,但是,不用说,这让你可以呆在更大的环境中,很容易地与同事分享你的结果。你需要MATLAB编译器,就像你在这里看到的,来创建那些包和那些——通过网络应用来共享那些应用。
我们结束吧。现在,有几件事我还没有我还没有机会谈论。其中之一是局部和全局敏感性分析。我们可以使用敏感性分析来找到潜在的药物靶点,找到特定模型结果的重要参数,还可以确定哪些参数应该估计,哪些参数可以用来修正,因为模型对它们不敏感。
所以SimBiology既支万博1manbetx持局部敏感性分析,也支持全局敏感性分析。对于全局灵敏度分析,目前支持Sobol全局灵敏度分析和多参数全局灵敏度分析两种方法。万博1manbetx你可以在我们的网站上找到一个关于这个主题的网络研讨会,其中有很多关于这个主题的细节。
我提到的另一件事是你可以在应用程序中也可以在程序中使用SimBiology,所以我们可以简单地看一下。比方说,一个典型的模拟程序,我们可以为这个程序编写等价的代码。
所以我们可以加载我们的项目并从我们的项目中选择我们的模型,然后从这个模型中找到一种叫做“每天50纳摩尔”的剂量,然后将停止时间设置为三天,然后用这些设置和剂量来模拟我们的模型。最后,我们把模拟数据画出来我们得到一个这样的图。也就是说,你可以用编程的方式做任何事你可以在用户界面中做任何事。
最后,我们有一个活跃的SimBiology用户社区。一个例子是基因泰克的团队开发了gQSPSim,这是一个基于simbio的图形用户界面的应用程序,用于标准化的QSP模型开发应用程序。它旨在通过扩展SimBiology的功能,特别是交互式可视化和虚拟主体的统计校准,为透明、可复制和可移植的QSP建模提供手段。
如果你想了解更多,你可以看看网上的gQSPSim手稿。这个应用程序可以免费下载。当然,这取决于你是否拥有《SimBiology》。
SimBiology使用建模框架的其他例子是百时美施贵宝的QSP工具箱,它意味着标准化QSP工作流的关键方面,包括数据集成、更多校准和可变性探索,以及校准虚拟种群。
Vantage开发了VQMtools。Vantage是另一家咨询公司VQMtools专注于创建和评估虚拟人口基于参考主题和模型约束的定义。
最后,来自约翰霍普金斯大学Aleksander Popel的团队已经开发了一个基于sim生物学的平台,用于免疫肿瘤学的QSP建模,该平台允许基于手上的研究问题在IO中构建不同程度的QSP模型。
这把我们带到了我们的社区。我们有一个社区页面。如果你搜索SimBiology Community,你就会找到它。它包含了我刚才提到的那些作品的链接。它包含一个回答—问题和回答部分以及教程—一个SimBiology教程视频的链接,关于如何建立模型,如何模拟,如何进行参数估计,等等,以及非分区分析。所以这是一个有用的资源,你也可以——你可以问问题,我们会尽快回答。
总结一下,什么是SimBiology?SimBiology提供应用程序和编程工具,通过绘制模型来建立模型,模拟模型,研究“如果”场景,估计参数,根据你可能拥有的数据或多个数据集校准你的模型,还可以执行像全局敏感性分析或蒙特卡洛模拟这样的分析。就到这里,我想感谢大家的关注。