预测
类:regARIMA
预测反应的回归模型与ARIMA错误
语法
[Y, YMSE] =预测(Mdl numperiods)
[Y, YMSE U] =预测(Mdl numperiods)
[Y, YMSE U] =预测(Mdl numperiods,名称,值)
描述
(预测响应(Y,YMSE)=预测(Mdl,numperiods)Y)回归模型与ARIMA时间序列错误并生成相应的均方误差(YMSE)。
(此外无条件的干扰预测的回归模型与ARIMA错误。Y,YMSE,U)=预测(Mdl,numperiods)
输入参数
输出参数
例子
预测反应的回归模型与ARIMA错误
预测反应从以下回归模型和ARMA(2, 1)错误在30-period地平线上:
在哪里 是高斯方差为0.1。
指定模型。来自两个预测模型和模拟响应系列。
Mdl0 = regARIMA (“拦截”0,基于“增大化现实”技术的{0.5 - -0.8},…“马”,-0.5,“β”(0.1 - -0.2),“方差”,0.1);rng (1);%的再现性X = randn (130 2);y =模拟(Mdl0,130,“X”,X);
符合第一100年观测模型,保留剩余的30观测评估预测性能。
Mdl = regARIMA (“ARLags”1:2);EstMdl =估计(Mdl y (1:10 0),“X”X (1:10 0,:));
回归与ARMA(2,0)误差模型(高斯分布):价值StandardError TStatistic PValue ________ _________________ __________ __________拦截AR {1} 0.36833 - 0.067103 0.004358 - 0.021314 0.20446 - 0.83799 5.4891 - 4.0408 e-08 AR {2} e-16β(1)1.4453 -0.75063 0.090865 -8.2609 0.076398 0.023008 3.3205 0.00089863 Beta (2) e-09方差2.0741 -0.1396 0.023298 -5.9919 0.079876 0.01342 5.9522 2.6453 e-09
EstMdl是一个新的regARIMA包含估计模型。估计接近他们的真实值。
使用EstMdl预测30-period地平线。视觉上比较坚持的预测数据使用一个阴谋。
(yF, yMSE) =预测(EstMdl 30“Y0”y (1:10 0),…“X0”X (1:10 0,:),“XF”X(101:最终,:));图绘制(y,“颜色”,7,7,7);持有在情节(101:130 yF,“b”,“线宽”2);情节(101:130 yF + 1.96 * sqrt (yMSE),“:”,…“线宽”2);情节(101:130、yf - 1.96 * sqrt (yMSE),“:”,“线宽”2);甘氨胆酸h =;ph =补丁([repmat(101年,1,2)repmat(130年1、2),…(h。YLim fliplr(h.YLim)],…[0 0 0 0),“b”);ph.FaceAlpha = 0.1;传奇(“观察”,“预测”,…“95%的预测区间”,“位置”,“最佳”);标题([“30-Period预测和近似95%”…预测区间的])轴紧持有从

抵抗的许多观测样本预测下降超出了95%的间隔。两个原因:
在本例中预测是随机生成的。
估计把固定的预测因子。基于估计的95%的预测区间估计不占预测的变化。切变机会,评估期间似乎比预测期波动较小。
估计使用挥发性弱估计时间数据来估计参数。因此,预测时间间隔根据估计不应该覆盖的观察,一个潜在的创新过程和更大的可变性。
预测GDP使用回归模型和ARMA错误
GDP预测固定,日志使用回归模型和ARMA(1,1)错误,包括CPI预测。
美国宏观经济数据集和预处理数据加载。
负载Data_USEconModel;logGDP =日志(DataTable.GDP);dlogGDP = diff (logGDP);%的平稳性3 = diff DataTable.CPIAUCSL);%的平稳性numObs =长度(dlogGDP);国内生产总值= dlogGDP(1:长达15);%估计样本cpi = 3(1:长达15);T =长度(gdp);%有效样本量frstHzn = T + 1: numObs;%预测地平线hoCPI = 3 (frstHzn);%抵抗样本dts =日期(2:结束);% nummbers日期
适合一个回归模型和ARMA(1,1)错误。
Mdl = regARIMA (“ARLags”,1“MALags”1);EstMdl =估计(Mdl、国内生产总值“X”cpi);
回归与ARMA(1,1)误差模型(高斯分布):价值StandardError TStatistic PValue __________ _________________ __________ __________拦截0.014793 0.0016289 9.0818 1.0684 e-19 AR{1} 0.57601 0.10009 5.7548 8.6755马e-09{1} -0.15258 0.11978 -1.2738 0.20272β(1)6.5562 9.5734 0.0028972 0.0013989 2.071 0.038355方差e-05 e-06 14.602 - 2.723 e-48
GDP增长率的预测15-quarter地平线。使用估计样本的presample预测。
[gdpF, gdpMSE] =预测(EstMdl 15“Y0”国内生产总值,…“X0”消费者价格指数,“XF”,hoCPI);
情节预测和95%的预测区间。
图h1 =情节(dts(端- 65:端),dlogGDP(端- 65:端),…“颜色”,7,7,7);datetick举行在h2 =情节(gdpF dts (frstHzn),“b”,“线宽”2);h3 =情节(dts (frstHzn) gdpF + 1.96 * sqrt (gdpMSE),“:”,…“线宽”2);情节(dts (frstHzn) gdpf - 1.96 * sqrt (gdpMSE),“:”,“线宽”2);甘氨胆酸公顷=;标题([{}\ bf预测和近似95%的…”{\ bf GDP增长率预测间隔}’]);ph =补丁([repmat (dts (frstHzn (1)), 1, 2) repmat (dts (frstHzn(结束),1,2)),…(公顷。YLim fliplr(ha.YLim)],…[0 0 0 0),“b”);ph.FaceAlpha = 0.1;传奇((h1 h2 h3) {“观察到GDP比率”,“国内生产总值预测率”,…“95%的预测区间”},“位置”,“最佳”,“自动更新”,“关闭”);轴紧持有从

使用回归模型与ARIMA预测错误和一个已知的拦截
GDP预测单位根的非平稳、日志使用回归模型与ARIMA(1, 1, 1)错误,包括CPI预测和拦截。
美国宏观经济数据集和预处理数据加载。
负载Data_USEconModel;numObs =长度(DataTable.GDP);日志(DataTable.GDP logGDP =(1:长达15));cpi = DataTable.CPIAUCSL(1:长达15);T =长度(logGDP);%有效样本量frstHzn = T + 1: numObs;%预测地平线hoCPI = DataTable.CPIAUCSL (frstHzn);%抵抗样本
指定模型估计。
Mdl = regARIMA (“ARLags”,1“MALags”,1' D '1);
拦截没有可识别的模型集成错误,所以估计之前解决它的价值。要做到这一点的方法之一是使用简单线性回归估计拦截。
Reg4Int = [(T, 1), cpi] \ logGDP;拦截= Reg4Int (1);
考虑执行使用网格敏感性分析的拦截。
设置拦截和合适的回归模型与ARIMA(1, 1, 1)错误。
Mdl。拦截=拦截;EstMdl =估计(Mdl logGDP,“X”消费者价格指数,…“显示”,“关闭”)
EstMdl = regARIMA属性:描述:“ARIMA(1, 1, 1)误差模型(高斯分布)”Distribution: Name = "Gaussian" Intercept: 5.80142 Beta: [0.00396703] P: 2 D: 1 Q: 1 AR: {0.922717} at lag [1] SAR: {} MA: {-0.387864} at lag [1] SMA: {} Variance: 0.000108944 Regression with ARIMA(1,1,1) Error Model (Gaussian Distribution)
预测GDP 15-quarter地平线。使用估计样本的presample预测。
[gdpF, gdpMSE] =预测(EstMdl 15“Y0”logGDP,…“X0”消费者价格指数,“XF”,hoCPI);
情节预测和95%的预测区间。
图h1 =情节(日期(端- 65:端),日志(DataTable.GDP(端- 65:端)),…“颜色”,7,7,7);datetick举行在h2 =情节(gdpF日期(frstHzn),“b”,“线宽”2);h3 =情节(日期(frstHzn) gdpF + 1.96 * sqrt (gdpMSE),“:”,…“线宽”2);情节(日期(frstHzn) gdpf - 1.96 * sqrt (gdpMSE),“:”,…“线宽”2);甘氨胆酸公顷=;标题([{}\ bf预测和近似95%的…的日志GDP} {\ bf预测区间的]);ph =补丁([repmat(日期(frstHzn (1)), 1, 2) repmat(日期(frstHzn(结束),1,2)),…(公顷。YLim fliplr(ha.YLim)],…[0 0 0 0),“b”);ph.FaceAlpha = 0.1;传奇((h1 h2 h3) {观察到国内生产总值的,“国内生产总值预测”,…“95%的预测区间”},“位置”,“最佳”,“自动更新”,“关闭”);轴紧持有从

无条件的干扰, 不稳定,因此预测区间的宽度随时间增长。
更多关于
时基分区预测
时基分区预测是两个不相交的,连续的时基的间隔;每个区间包含预测动态模型的时间序列数据。的预测期(预测地平线)是一个numperiods分区的最后时间基地中预测生成预测Y从动态模型Mdl。的presample时期是整个分区发生之前预测期。预测需要观察反应Y0,回归数据X0,无条件的干扰情况或创新E0presample时期来初始化预测的动态模型。模型结构确定所需的类型和数量的presample观察。
常见的做法是为适应动态模型的一部分数据集,然后通过比较验证模型的可预测性的预估,观察反应。在预测过程中,presample周期包含的数据模型是合适的,并包含抵抗的预测期样本进行验证。假设yt是一个观察响应系列;x1,t,x2,t,x3,t观察了外源性系列;和时间t= 1,…,T。考虑预测反应的动力学模型yt包含一个回归组件numperiods=K期。假设动态模型是适合的数据区间[1,T- - - - - -K)(更多细节,请参阅估计)。这图显示了分区预测时间基地。
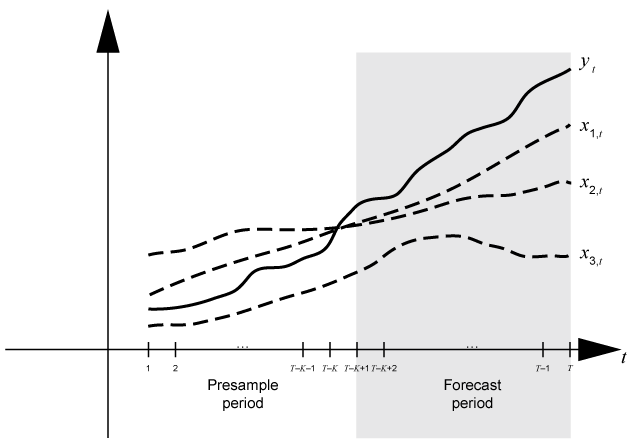
例如,要生成预测Y从一个回归模型AR(2)错误,预测需要presample无条件的干扰情况和未来的预测数据XF。
预测推断无条件干扰给予足够的现成presample反应和预测数据。初始化一个AR(2)误差模型,Y0= 和X0= 。模型,
预测需要未来的外生数据XF= 。
这个图显示了一般情况下的阵列所需的观测,与相应的输入和输出参数。

算法
引用
[1],g . e . P。,G. M. Jenkins, and G. C. Reinsel.时间序列分析:预测与控制。第三。恩格尔伍德悬崖,新泽西:普伦蒂斯霍尔,1994年。
[2]戴维森,R。,J. G. MacKinnon.计量经济学理论和方法。英国牛津:牛津大学出版社,2004年。
恩德斯[3],W。应用计量经济学时间序列。新泽西州霍博肯:约翰·威利& Sons Inc ., 1995年。
[4]汉密尔顿,j . D。时间序列分析。普林斯顿,纽约:普林斯顿大学出版社,1994年。
[5]Pankratz说道,。与动态回归模型预测。约翰•威利& Sons Inc ., 1991年。
[6]-蔡,r S。金融时间序列的分析。第二版,霍博肯,台北:约翰·威利& Sons Inc ., 2005年。
