比较使用贯穿整个周期的违约概率和时间点模型
这个例子展示了如何使用消费信贷面板数据来创建贯穿整个周期(TTC)和时间点(坑)模型并比较各自的违约概率(PD)。
债务人的PD信贷风险分析是一个基本的风险参数。债务人的PD取决于客户的特定风险因素以及宏观经济风险因素上。因为他们把宏观经济条件不同,TTC和坑模型产生不同的PD估计。
TTC信用风险度量主要反映了信用风险客户长期的趋势。瞬态、短期信用风险的变化可能会改变随着时间的推移得到消除。TTC信用风险措施的主要特点是高稳定度在信贷周期和随时间变化的平滑。
坑信用风险度量利用所有可用的和相关的信息作为一个给定的日期估计顾客的PD在给定的时间范围内。设置的信息不仅包括对客户的信用风险趋势预期长期而且地理,宏观经济,macro-credit趋势。
以前,根据新巴塞尔规则、监管机构呼吁TTC PDs的使用,给违约损失(乐金显示器),和曝光违约(EADs)。然而,随着新的IFRS9并提出CECL会计标准,监管机构现在要求机构使用坑预测PDs,乐金显示器,欧洲宇航防务集团。由占信贷周期的当前状态,坑措施密切追踪违约和亏损率随时间的变化。
面板数据加载
在这个例子中(主数据集数据)包含以下变量:
ID -贷款标识符。ScoreGroup -贷款的信用评分开始时,离散分成三组:高的风险,中等风险,低风险。小无赖,年书。默认的,默认的指标。这是反应变量。年日历年。
数据还包括一个小的数据集(dataMacro与相应的日历年的宏观经济数据):
年日历年。国内生产总值(GDP) -国内生产总值(gdp)增长(年)。市场,市场回报率(同比)。
的变量小无赖,一年,国内生产总值,市场是观察到相应的日历年度的结束。ScoreGroup是一种离散化的原始贷款信用评分时开始。的值1为默认的意味着相应的日历年贷款违约。
这个示例使用模拟数据,但是可以将同样的方法应用到真实的数据集。
加载数据和视图的第一个10行表。面板数据是堆叠的观察相同的ID存储在连续的行,创建一个瘦而高、表。面板是不平衡的,因为不是所有的标识都有相同数量的观察。
负载RetailCreditPanelData.matdisp(头(数据,10));
ID ScoreGroup小无赖默认年__ ___________ ___ ____ ____ 1低风险1 0 1998 1997 1低风险2 0 1低风险1999 1低风险4 0 0 2001 2000 1低风险5 0 1低风险6 0 2002 1低风险7 0 2003 1低风险8 0 2004 2中等风险1 0 1997 2中等风险2 0 1998
nRows =身高(数据);UniqueIDs =独特(data.ID);nIDs =长度(UniqueIDs);流(IDs的总数:% d \ n 'nIDs)
IDs总数:96820
流(“总行数:% d \ n 'nRows)
总行数:646724
违约率在今年
使用一年作为分组变量计算每年的观察到的违约率。使用groupsummary函数计算的均值默认的变量分组的一年变量。阴谋的结果散点图显示,违约率下降随着时间的增加。
DefaultPerYear = groupsummary(数据,“年”,“的意思是”,“默认”);NumYears =身高(DefaultPerYear);disp (DefaultPerYear)
__ __________年GroupCount mean_Default _______ 1997 0.013355 35214 0.018629 1998 66716 1999 94639 0.012733 2000 0.010742 92891 0.011379 2001 91140 2002 89847 0.010295 0.0032905 0.0056417 2003 88449 2004 87828
次要情节(2,1,1)散射(DefaultPerYear。年,DefaultPerYear.mean_Default * 100,‘*’);网格在包含(“年”)ylabel (的违约率(%))标题(“每年违约率”)%得到IDs的1997、1998和1999个军团IDs1997 = data.ID (data.YOB &data.year = = = = 1997);IDs1998 = data.ID (data.YOB &data.year = = = = 1998);IDs1999 = data.ID (data.YOB &data.year = = = = 1999);%得到违约率分别为每个队列ObsDefRate1997 = groupsummary(数据(ismember (data.ID IDs1997):),…“小无赖”,“的意思是”,“默认”);ObsDefRate1998 = groupsummary(数据(ismember (data.ID IDs1998):),…“小无赖”,“的意思是”,“默认”);ObsDefRate1999 = groupsummary(数据(ismember (data.ID IDs1999):),…“小无赖”,“的意思是”,“默认”);%对历年的阴谋年=独特(data.Year);次要情节(2,1,2)情节(ObsDefRate1997.mean_Default * 100,“- *”)举行在情节(年(2:结束),ObsDefRate1998.mean_Default * 100,“- *”)情节(年(3:结束),ObsDefRate1999.mean_Default * 100,“- *”)举行从标题(违约率与历年的)包含(“年”)ylabel (的违约率(%))传说(“97”,“98”,“99”网格)在

情节表明,违约率降低。注意,在故事情节中,贷款从1997年开始,1998年和1999年三个军团。面板数据中没有贷款1999年之后开始。这是更详细地描述“买书和日历年”一节的例子压力测试的消费信贷违约概率使用面板数据。减少的趋势在这个阴谋的解释是,只有三个军团模式为每个队列的数据和减少。
TTC模型使用ScoreGroup年书
TTC模型在很大程度上是受经济状况的影响。在这个示例中只使用第一个TTC模型ScoreGroup和小无赖作为违约率的预测。
生成训练和测试数据集通过将现有的数据划分为训练和测试数据集用于模型创建和验证,分别。
NumTraining =地板(0.6 * nIDs);rng (“默认”);NumTraining TrainIDInd = randsample (nIDs);TrainDataInd = ismember (data.ID UniqueIDs (TrainIDInd));TestDataInd = ~ TrainDataInd;
使用fitLifetimePDModel函数以适应物流模型。
TTCModel = fitLifetimePDModel(数据(TrainDataInd,:),“物流”,…“ModelID”,“TTC”,“IDVar”,“ID”,“AgeVar”,“小无赖”,“LoanVars”,“ScoreGroup”,…“ResponseVar”,“默认”);disp (TTCModel.Model)
紧凑的广义线性回归模型:分对数(默认)~ 1 + ScoreGroup +小无赖=二项分布估计系数:估计SE tStat pValue说____ ___________(拦截)-3.2453 0.033768 -96.106 0 ScoreGroup_Medium风险-0.7058 0.037103 -19.023 1.1014 e - 80 ScoreGroup_Low风险-1.2893 0.045635 -28.253 1.3076 e - 175小无赖-0.22693 0.008437 -26.897 2.3578 e - 159 388018观察,388014错误自由度色散:1 x ^ 2-statistic与常数模型:1.83 e + 03,假定值= 0
预测的PD训练和测试数据集使用预测。
数据。TTCPD = 0(高度(数据),1);%样本预测的data.TTCPD (TrainDataInd) =预测(TTCModel、数据(TrainDataInd:));%的样本外预测data.TTCPD (TestDataInd) =预测(TTCModel、数据(TestDataInd:));
可视化样本内和样本外的配合使用modelCalibrationPlot。
图;次要情节(2,1,1)modelCalibrationPlot (TTCModel、数据(TrainDataInd:)“年”,“DataID”,“训练数据”次要情节(2,1,2)modelCalibrationPlot (TTCModel、数据(TestDataInd:)“年”,“DataID”,“测试数据”)

坑模型使用ScoreGroup年书,GDP和市场回报
坑模型随经济周期。在本例中使用的坑模型ScoreGroup,小无赖,国内生产总值,市场作为违约率的预测。使用fitLifetimePDModel函数以适应物流模型。
%的GDP和市场回报列添加到原始数据data =加入(数据、dataMacro);disp(头(数据,10))
ID ScoreGroup小无赖违约TTCPD GDP市场__ ___________ ___ ____ ____ ____专攻1低风险1 0 1997 0.0084797 2.72 7.61 1低风险2 0 1998 0.0067697 3.57 26.24 1低风险3 0 1999 0.0054027 2.86 18.1 1低风险4 0 2000 0.0043105 2.43 3.19 1低风险5 0 2001 0.0034384 1.26 -10.51 1低风险6 0 2003 2002 0.0027422 -0.59 -22.95 1低风险7 0 0.0021867 0.63 2.78 1低风险8 0 2004 0.0017435 1.85 9.48 2中等风险1 0 1997 0.015097 2.72 7.61 2中等风险2 0 1998 0.012069 3.57 26.24
PITModel = fitLifetimePDModel(数据(TrainDataInd,:),“物流”,…“ModelID”,“坑”,“IDVar”,“ID”,“AgeVar”,“小无赖”,“LoanVars”,“ScoreGroup”,…“MacroVars”,{“国内生产总值”“市场”},“ResponseVar”,“默认”);disp (PITModel.Model)
紧凑的广义线性回归模型:分对数(默认)~ 1 + GDP ScoreGroup +小无赖+ +市场=二项分布估计系数:估计SE tStat pValue __________ ___________和___________(拦截)-2.667 0.10146 -26.287 2.6919 e - 152 ScoreGroup_Medium风险-0.70751 0.037108 -19.066 4.8223 e - 81 ScoreGroup_Low风险-1.2895 0.045639 -28.253 1.2892 e - 175小无赖-0.32082 0.013636 -23.528 2.0867 e - 122 GDP市场-0.12295 0.039725 -3.095 0.0019681 -0.0071812 0.0028298 -2.5377 0.011159 388018年观察,388012错误自由度色散:1 x ^ 2-statistic与常数模型:1.97 e + 03,假定值= 0
预测PD训练和测试数据集预测。
数据。PITPD = 0(高度(数据),1);%样本预测的data.PITPD (TrainDataInd) =预测(PITModel、数据(TrainDataInd:));%样本外预测data.PITPD (TestDataInd) =预测(PITModel、数据(TestDataInd:));
可视化样本内和样本外的配合使用modelCalibrationPlot。
图;次要情节(2,1,1)modelCalibrationPlot (PITModel、数据(TrainDataInd:)“年”,“DataID”,“训练数据”次要情节(2,1,2)modelCalibrationPlot (PITModel、数据(TestDataInd:)“年”,“DataID”,“测试数据”)

在坑模型中,如预期,预测匹配更密切地观察到的违约率比TTC模型。虽然这个示例使用模拟数据,定性,相同类型的模型改进预计当从TTC坑模型对于真实世界的数据,虽然整体误差可能会比在这个例子。坑模型适合通常比TTC模型和预测通常观察到相匹配的利率。
计算使用坑TTC PD模型
计算TTC PDs的另一种方法是使用坑模型然后替换国内生产总值和市场返回各自的平均值。在这种方法中,您使用平均值在整个经济周期(或更长时间),因此只有基线经济条件影响模型,和其他任何违约率变化是由于风险因素。您还可以输入预测基线值对于不同的经济意味着观察最近的经济周期。例如,使用中值而不是平均减少了误差。
您还可以使用这种方法计算TTC PDs使用坑模型作为场景分析的工具,但是;这个不能做的第一个版本TTC模型。这种方法的优势是,您可以使用单个模型TTC和坑预测。这意味着您需要验证和维护只有一个模型。
%修改数据取代GDP和市场回报与相应的平均值data.GDP(,) =值(data.GDP);数据。市场= repmat(意思是(data.Market)高度(数据),1);disp(头(数据,10));
ID ScoreGroup小无赖违约TTCPD GDP市场PITPD __ ___________ ___ ____ ____上______ _____ 1低风险1 0 1997 0.0084797 1.85 3.2263 0.0093187 1低风险2 0 1998 0.0067697 1.85 3.2263 0.005349 1低风险3 0 1999 0.0054027 1.85 3.2263 0.0044938 1低风险4 0 2000 0.0043105 1.85 3.2263 0.0038285 1低风险5 0 2001 0.0034384 1.85 3.2263 0.0035402 1低风险6 0 2002 0.0027422 1.85 3.2263 0.0035259 1低风险7 0 2003 0.0021867 1.85 3.2263 0.0018336 1低风险8 0 2004 0.0017435 1.85 3.2263 0.0010921 2中等风险1 0 1997 0.015097 1.85 3.2263 0.016554 2中等风险2 0 1998 0.012069 1.85 3.2263 0.0095319
预测PD训练和测试数据集预测。
数据。TTCPD2 = 0(高度(数据),1);%样本预测的data.TTCPD2 (TrainDataInd) =预测(PITModel、数据(TrainDataInd:));%样本外预测data.TTCPD2 (TestDataInd) =预测(PITModel、数据(TestDataInd:));
可视化样本内和样本外的配合使用modelCalibrationPlot。
f =图;次要情节(2,1,1)modelCalibrationPlot (PITModel、数据(TrainDataInd:)“年”,“DataID”,“培训、宏观平均”次要情节(2,1,2)modelCalibrationPlot (PITModel、数据(TestDataInd:)“年”,“DataID”,“测试、宏观平均”)

重置的原始值国内生产总值和市场变量。使用坑的TTC PD值预测模型和中值或意味着宏观值存储在TTCPD2列,列用于下面的预测与其他模型进行比较。
数据。国内生产总值= []; data.Market = []; data = join(data,dataMacro); disp(head(data,10))
ID ScoreGroup小无赖默认年TTCPD PITPD TTCPD2 GDP市场__⒈替___ ____ ____ ____专攻1低风险1 0 1997 0.0084797 0.0093187 0.010688 2.72 7.61 1低风险2 0 1998 0.0067697 0.005349 0.0077772 3.57 26.24 1低风险3 0 1999 0.0054027 0.0044938 0.0056548 2.86 18.1 1低风险4 0 2000 0.0043105 0.0038285 0.0041093 2.43 3.19 1低风险5 0 2001 0.0034384 0.0035402 0.0029848 1.26 -10.51 1低风险6 0 2002 0.0027422 0.0035259 0.0021674 -0.59 -22.95 1低风险7 0 2003 0.0021867 0.0018336 0.0015735 0.63 2.78 1低风险8 0 2004 0.0017435 0.0010921 0.0011422 1.85 9.48 - 2中等风险1 0 1997 0.015097 0.016554 0.018966 2.72 7.61 - 2中等风险2 0 1998 0.012069 0.0095319 0.013833 3.57 26.24
比较模型
首先,比较两个版本的TTC模型。
比较该模型使用的歧视modelDiscriminationPlot。两个模型有非常类似的性能排名客户,以接受者操作特征(ROC)曲线和ROC曲线下的面积(AUROC,或者只是AUC)指标。
图;modelDiscriminationPlot (TTCModel、数据(TestDataInd:),“DataID”,“测试数据”,“ReferencePD”data.TTCPD2 (TestDataInd),“ReferenceID”,“TTC 2、宏观平均”)

然而,TTC模型更准确,预测PD值接近观察到的违约率。使用生成的情节modelCalibrationPlot表明根均方误差(RMSE)报道,在情节证实了TTC模型更准确的数据集。
modelCalibrationPlot (TTCModel、数据(TestDataInd:),“年”,“DataID”,“测试数据”,“ReferencePD”data.TTCPD2 (TestDataInd),“ReferenceID”,“TTC 2、宏观平均”)

使用modelDiscriminationPlot比较TTC模型和坑模型。
坑的AUROC只是略好模型,表明这两种模型对比关于排名的客户风险。
图;modelDiscriminationPlot (TTCModel、数据(TestDataInd:),“DataID”,“测试数据”,“ReferencePD”data.PITPD (TestDataInd),“ReferenceID”,“坑”)

使用modelCalibrationPlot可视化模型准确性,或模型校准。情节表明坑模型执行更好,用预测PD值更接近观察到的违约率。这预计,因为对宏观变量,预测是敏感而TTC模型只使用最初的得分和年龄的模型进行预测。
modelCalibrationPlot (TTCModel、数据(TestDataInd:),“年”,“DataID”,“测试数据”,“ReferencePD”data.PITPD (TestDataInd),“ReferenceID”,“坑”)
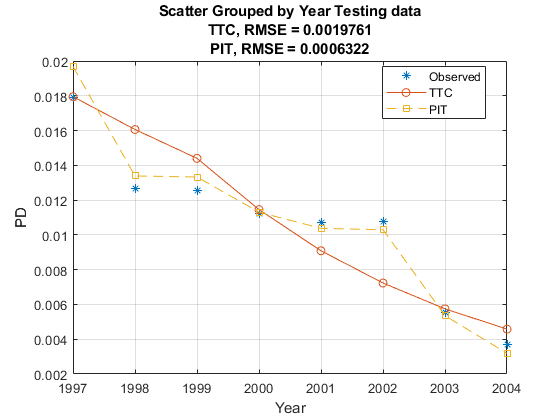
您可以使用modelDiscrimination以编程方式访问AUROC和RMSE没有创建一个阴谋。
DiscMeasure = modelDiscrimination (TTCModel、数据(TestDataInd:)“DataID”,“测试数据”,“ReferencePD”data.PITPD (TestDataInd),“ReferenceID”,“坑”);disp (DiscMeasure)
0.68662坑AUROC _________ TTC、测试数据,测试数据0.69341
CalMeasure = modelCalibration (TTCModel、数据(TestDataInd:)“年”,“DataID”,“测试数据”,“ReferencePD”data.PITPD (TestDataInd),“ReferenceID”,“坑”);disp (CalMeasure)
RMSE _____ TTC的分组,测试数据0.0019761坑,分组,0.0006322测试数据
尽管所有模型比较歧视权力,坑模型的准确性要好得多。然而,TTC和坑模型通常用于不同的目的,和TTC模型可能是首选,如果随着时间的推移,拥有更稳定的预测是很重要的。
引用
广义线性模型文档,请参阅广义线性模型。
Baesens B。,D. Rosch, and H. Scheule.信用风险分析。威利,2016年。