大家好,欢迎来到机器学习简单化。我叫Shashank Prasanna。我是MathWorks的统计和机器学习产品的产品经理。s manbetx 845
这是今天演讲的议程。首先,我将简要概述什么是机器学习,以及你为什么要考虑它。接下来我们将看到机器学习中的一些关键挑战。
接下来,我将通过解决一个涉及真实世界数据的有趣问题来更深入地研究机器学习。为了解决这个问题,我将介绍一个通常用于解决机器学习问题的典型工作流。然后,我们将介绍另一个涉及图像数据的有趣示例。我会给你们看一个现场演示,用网络摄像头的视频来识别物体。我们将以一个总结和一些关于何时考虑机器学习的指导来结束本次会议。
因为这是一个简单的主题,没有先决条件。基本熟悉MATLAB是有帮助的,但不是必需的。机器学习无处不在。在当今世界,这些技术越来越多地被用于做出重要的商业和生活决策。今天,有了机器学习,我们能够解决汽车、金融、计算机视觉和其他几个以前认为不可能的领域的问题。
那么什么是机器学习呢?让我们花点时间快速浏览一下机器学习的高级概念。即使你熟悉这个话题,这也可以作为一个快速的提醒,提醒你什么时候进行机器学习是有用的。
我们可以将机器学习定义为一种使用数据并生成程序来执行任务的技术。让我用一个例子来解释一下。假设有一项任务需要使用手机的传感器数据来检测一个人的活动;例如,如果这个人正在走路、坐着、站着等等。解决这类任务的标准方法是,要么分析信号,并写出一套设计良好的规则的程序,要么你可能知道一套先验的方程或公式,使用输入和预测输出。
机器学习方法是直接从数据中学习这样一个程序。在这种情况下,我们给算法提供输入和输出数据,并让它学习程序来解决这个任务。这个步骤通常称为训练。输出是一个模型,现在可以用来从新的传感器数据中检测活动。
请注意,我没有明确提到特定的机器学习算法,因为有很多算法可供选择,每个算法都有自己的优缺点。我们会在详细讲解这个例子时看到。如果我想让你们从这张幻灯片中学到两点,那就是,第一,你需要数据。如果没有数据,就无法进行机器学习。这是一个强烈的要求。
第二,只有当任务很复杂,而且没有神奇的方程或公式来解决它时,才考虑机器学习。如果您有一个公式,您可以继续执行它。机器学习也可以,但在这种情况下不推荐使用这种方法。
让我们进入MATLAB看看机器学习方法是什么样的。我们正在处理的数据由6个输入组成,3个来自加速度计,3个来自手机的陀螺仪。响应或输出是执行的活动。包括行走、站立、跑步、爬楼梯和躺着。
这是分类学习者。这是一个交互式工具,可让您执行常用机器学习任务,例如交互式探索您的数据,选择功能,指定验证方案,培训模型和评估结果。在我左边,我有几种不同的机器学习模型已经在传感器数据上培训。在每个模型旁边的右侧是一个百分比,指示单独的验证集上所选分类器的准确性。我可以在这里使用右边的可视化来探索我的数据,以搜索模式和趋势。
训练一个新模型很容易。我只需导航到Classifier图库,选择一个感兴趣的分类器,然后点击Train。一旦训练完成,您就可以在History List中看到新模型以及模型的性能精度。这个数字越高,模型在新数据上的表现就越好。我将选择我表现最好的模型,并单击Export开始在MATLAB中使用我的模型,我可以看到导出的模型就在这里的工作空间中。
现在我想使用这个模型以及一些测试数据来可视化模型的预测结果。这张图显示了两秒半的加速计和陀螺仪数据流。顶部的绿条显示的是这个人的实际活动对应的是这里的传感器信号。如果模型能够成功预测出这个人的实际活动,那么底部的那条条就是绿色的,如果它不能预测出这个人的实际活动,那么它就是红色的。你可以看到,这个模型经常混淆走路和爬楼梯。
让我们快速回顾一下我们刚刚取得的成果。我们使用分类学习器来拟合几个不同的模型。然后,我们选择了一个显示出良好效果的,并对它进行了测试,以确保它发挥了应有的作用。这看起来很简单,那么为什么机器学习有如此难的名声呢?
为了回答这个问题,我想引用一位著名统计学家的话,他曾在一本教科书中写道:“所有模型都是错误的,但有些是有用的。”为什么?因为模型是近似的。不仅仅是机器学习模型——所有的模型都是基于几个假设的近似,但这并不会降低它们的用处。机器学习模型可以解释数据中的复杂模式,但要成功地应用机器学习,你需要找到有用的模型,而这可能是一项具有挑战性的任务。
实际上,机器学习工作流的每一步都有很多挑战。数据有各种各样的形状和大小。它可以是简单的数字数据,比如来自金融数据或传感器信号,也可以是来自相机的流式图像或文本数据。真实世界的数据集通常是杂乱的,而且不总是表格化的。
预处理数据需要特定领域的算法和工具。例如,需要信号或图像处理算法从信号和图像数据中提取有用的特征。特征选择和特征转换需要统计算法。我们经常需要来自多个领域的工具,当使用多个机器学习算法时,搜索最佳模型可能是一项令人生畏且耗时的任务。
关键在于,选择最佳的机器学习模型是一种平衡行为。高度灵活的模型可能是准确的,但也可能过度拟合您的数据,并且在新数据上表现不佳。在另一个极端,简单的模型可能对数据假设过多。在速度、准确性和模型的复杂性之间总是有一个权衡。
最后,机器学习的工作流从来都不是一个方便的线性工作流。我们总是要不断地反复、迭代、尝试不同的想法,然后才能找到解决方案。我今天的目标是:向大家介绍一套解决这些挑战的常用工具和策略。
以下是我们在解决机器学习任务时喜欢遵循的简单的两步工作流程。第一步是训练模型。我们首先引入数据,这些数据可能来自各种不同的来源,如数据库、流设备等。接下来,我们使用特征提取或其他统计工具对数据进行预处理。这一步对于将数据转换为机器学习算法可以处理的格式至关重要。
之后,我们就可以从数据中学习了。如果任务是预测标签或类别,我们选择分类方法。如果任务是预测连续值,那么我们选择回归方法,然后继续构建模型。当然,这是一个迭代过程,需要反复到预处理步骤,尝试不同的机器学习算法,调整不同的参数,等等。
这个工作流的第二步是实际使用模型,所以在左边,我有新的数据,在右边,我需要做出预测。从数据到预测,我们需要做些什么呢?首先,我们需要对新数据使用所有的预处理步骤,因此这里不涉及额外的工作。我们只是重复了我们在训练阶段花费的辛苦工作。
接下来,我们使用训练阶段的模型进行预测。对于一些工程问题,第二步通常部署或集成到生产环境中,例如,在服务器上使用机器学习执行自动特征。现在让我们使用这个工作流来通过MATLAB中的一个例子。
这个例子的目标是训练一个分类器,根据传感器测量自动识别人类活动。数据由六个输入组成,三个来自加速度计,三个来自陀螺仪。输出的响应是执行的活动:行走、站立、跑步、爬楼梯和铺设。
我们将采取的方法如下。首先,我们将从传感器信号中提取基本功能。然后,我们将使用分类学习者培训并比较几种不同的分类器,最后测试结果对看不见的传感器数据进行测试。
这是MATLAB。我们将从当前文件夹窗口开始。由于工作流的第一步是引入数据,我将加载一些原始传感器数据,我在这里有一个MAT文件。要导入这些数据,我所要做的就是将其拖放到工作区窗口中。工作空间窗口可以帮助您跟踪MATLAB中的所有变量,无论它们是现有的变量还是我们在移动过程中创建的新变量。
我的数据包括七个变量。前六是感觉输入变量,三个用于陀螺仪,用于加速度计x,y和z。最后一个变量,对传感器测量的每个观察活动标签包含活动标签。请注意所有变量有大约7,000个观察结果。让我们来看看个人感官输入看起来像什么。
如果我画出x轴陀螺仪数据的一行,我们看到它有大约128个点。这就是数据所代表的。传感器数据通常是用窗框收集和固定的。每一行有128个读数,对应两个半秒的传感器数据。
现在,这些数据的形式不能用于机器学习。我必须首先处理所有这些输入,为这128个点或2秒半窗口提取特征,我必须对所有6个传感器输入都这样做。但在我们开始特征提取之前,让我们先看看原始传感器数据是什么样的。
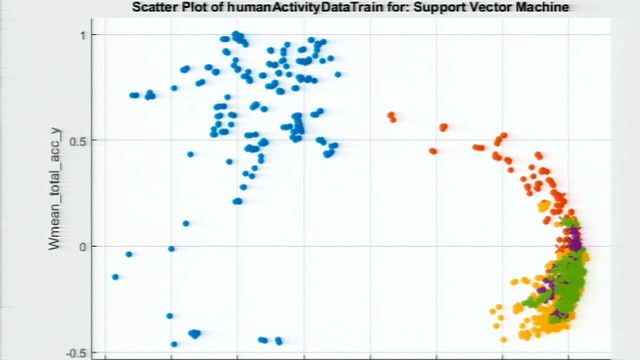
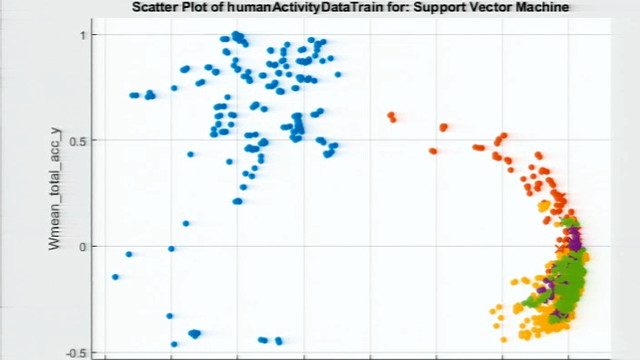
我这里有一个自定义的图显示了三个加速度计的原始传感器数据,它们有不同的颜色对应于人正在执行的活动。MATLAB中的绘图具有相当的交互性。我可以放大看是否有任何视觉模式或者是否有趋势可以帮助我们识别这个人的活动。
快速看一眼,我们可以看到每种颜色的传感器值看起来都不同。例如,此处对应于爬楼梯的橙色值与对应于站立的紫色值有很大不同。然而,同时,很难从视觉上区分步行和攀岩,因为两者都涉及大量的运动。像这样的问题很适合机器学习,因为我们并不总是能够为这些活动定义规则。
在我们从功能提取步骤开始之前,我将从这六个传感器输入中创建一个表。表是用于保持混合型数据的优秀工具,这在机器学习中很常见。在此示例中,我们具有传感器测量,这是数字的数字,并且是一种分类值的标签。
我现在在我的工作空间中有一个表变量,它包括所有六个独立的传感器变量。在机器学习中使用表格的另一个好处是,我可以用一行代码对表格中的所有变量应用一个特征提取函数。我所要做的就是调用VarFun,它代表变量函数,并传递我的特征提取函数。这里的WMean是一个函数,它计算传感器变量中每一行的平均值。在本例中,我计算的是两秒半帧传感器值的平均值。
WMean是我当前文件夹浏览器中的一个函数,正如你所看到的,它是一个相当简单的函数。但根据您的应用程序和您想要提取的特征,这可能是您所希望的最复杂的。除了均值,我还想提取另外两个特征,即每帧的标准差,以及PCA,即主成分分析,我想只保留第一个主成分。因为表可以保存混合类型的数据,所以我将把Activities标签赋值为一个名为Activity Within Table的新变量。
让我们运行这个部分,看看人类活动数据表是什么样子的。我总共有19列,前六列对应于框架的平均值。接下来的六个是帧的标准偏差,最后六个是PCA输出。我的最后一个专栏是与每次观察相对应的活动,可以是躺着、坐着、爬楼梯、站着或走路。
现在我们准备好了数据,让我们移动分类学习者训练我们的模型。分类学习者是统计和机器学习工具箱的一部分,您可以通过在MATLAB命令行上键入分类学习者来启动它。或者您可以在Mat统计和优化下的AppStat下找到它。
我们首先从MATLAB工作区导入数据。在导入对话框的第一步中,我们从MATLAB工作区中选择数据集。在第二步中,注意应用程序会自动选择一个变量是预测器还是响应。
应用程序根据数据类型来决定。但是,您也可以选择更改其角色或完全删除该变量。现在,我们就这样吧。
在第三步中,我们可以选择验证方法。验证可以防止过度拟合等问题。当数据集相对较小时,可以选择交叉验证,因为它可以有效地利用所有数据。如果有足够的数据,可以选择保持。
我选择这个选项来解决我们的问题因为我们有很多数据点。将Hold Out比例设置为20%会指示应用程序使用80%的数据进行训练,20%用于验证模型的性能。最后一个选项通常不推荐。由于所有的数据都用于训练和测试,这导致了对模型准确性的偏差估计。
分类学习者是一个相当互动的环境,有许多不同的窗口和组件,我保证,当它们变得相关时,我们将仔细研究其中的每一个窗口和组件。顶部的toolstrip显示了从导入数据到导出模型的从左到右的工作流。这里的中心是按响应变量分组的成对散点图。
这个图对于查找模式很有用。例如,这对预测器,我们注意到铺设似乎与其他活动分离得很好。坐姿似乎也很分开,但也有一些重叠。工具条上的特征选择选项允许您从模型中排除预测器。对于这个例子,因为我们没有太多的预测器,所以我们将保持这个。
在解决分类问题时,没有一刀切的办法。不同的分类器对不同类型的数据和问题最有效。分类学习器允许您从决策树、支持向量机、最近邻和集成分类器中进行选择,对于每种分类器类型,都有几个预设值,这些预设值是一系万博1manbetx列分类问题的优秀起点。如果您不确定选择哪个,弹出的工具提示将为您提供分类器的简要描述。
当使用MATLAB时,帮助总是只需点击即可。如果需要进一步的帮助,只需点击右上角的问号,就会打开应用程序的文档。你可以在这里找到关于应用程序的所有信息。现在,让我们看下一节,它提供了选择分类器的指导。
这里有一个很好的表格,根据您想要做出的权衡,可以指导您选择哪个分类器。例如,决策树的拟合速度很快,但具有中等的预测精度。另一方面,最近的邻居对较小的问题有较高的预测精度,但也有较高的内存使用。让我们使用文档中的这个技巧,首先从决策树开始。
训练一个模特很容易。只需从gallery中选择一个预设并点击train,这将在模型历史中生成一个train模型及其预测精度。让我们也训练一个中等树和一个复杂树。在验证集上表现最好的模型始终显示为绿色框。
除了预测精度百分比外,还有其他有用的诊断工具。混乱矩阵是一个很好的工具,可以告诉您分类器如何快速浏览,因此这就是您读取混淆矩阵的方式。对角线上的任何东西都是正确的分类。偏离对角线被错误分类。一个完美的分类器将在对角线上有100%,而且在其他地方0%。
让我们仔细看看一个活动:爬楼梯。89.1%的情况下,模型成功预测了活动。然而,10.9%的情况下,模型认为爬楼梯是步行,换句话说,模型误将爬楼梯定义为步行。在现代历史中,我们总是可以在不同的模型之间切换,以比较混淆矩阵。
应用程序中的另一个诊断工具是自动C曲线。自动C曲线用于描述二值分类器的灵敏度。曲线的形状显示了敏感性和特异性之间的权衡。当我们向上并向曲线的右侧移动时,我们增加了真阳性的机会,但也增加了假阳性的机会。
在我看来,使用应用程序而不是编写代码的最大优势之一是能够训练多个模型。除了决策树,我现在要训练最近邻分类器因为我知道它们训练和预测都很快。当训练多个模型时,你不必局限于这些预设。
如果您是高级用户,您总是可以打开高级弹出窗口来调整分类器参数。为了方便起见,这些更改也显示在模型历史记录中。在模型历史中,我们现在有大约8个模型,我在几秒钟内训练了所有的模型,而不需要写一行MATLAB代码。
有两种模式可以导出分析。您可以将您的模型直接导出到MATLAB,或者您可以选择生成MATLAB代码,使您无需编写任何代码就可以自动化构建该模型的所有步骤。让我选择这个选项,向您展示生成的代码是什么样子的。
我在这里的MATLAB是一个很好的评论,完全自动生成的MATLAB代码。我们还可以看到代码捕获的工作流中的不同步骤。例如提取预测器和响应、使用KNN分类器训练分类器、设置Hold Out验证等。您总是可以定制生成的代码,将其集成到您的应用程序中。
让我们回到Classification Learner并导出一个模型,我们可以看到这个模型现在在MATLAB工作空间中可用。现在,我们可以在新数据上测试模型了。首先,我们从MAT文件中加载一些新的传感器数据。然后我们使用与之前相同的特征提取步骤。然后我们使用导出的模型对新的传感器数据进行测试。
正如我们之前看到的,顶部的绿色条显示了人员正在执行的实际活动,而底部的绿色条则显示了模型成功检测到活动的情况。如果出错,它就是红色的。如果您想尝试一个新的模型,您可以简单地返回到Classification Learner,或者直接导出模型,或者生成MATLAB代码,并训练新模型使用新数据进行预测。
让我们快速浏览一下我们的工作流程,总结一下我们刚刚做了什么。我们的训练数据是从手机传感器获得的传感器信号。我们应用基本的预处理技术来提取特征,如平均标准差和主成分分析。然后,我们使用分类学习者应用程序,根据坚持验证的准确性得出我们的最佳模型。
对于使用新数据进行预测,我们对新数据应用相同的预处理步骤,然后使用经过训练的模型进行预测,然后将结果可视化。让我们看另一个例子,我们将使用图像数据训练机器学习模型。这个例子的目的是训练一个分类器,从网络摄像头视频中自动检测汽车。数据由四种不同玩具汽车的几张图片组成。输出的响应是这四辆车中每辆车的一个标签。
我们将采取的方法如下。首先,我们将使用称为文字袋的技术从这些图像中提取特征。然后,我们使用这些功能培训并使用分类学习者培训和分类几个不同的分类器。最后 - 这是一个有趣的部分 - 我们会看到我们在办公室的网络摄像头饲料实时识别汽车的实时演示。
我们切换到MATLAB。我要清理我的工作空间,重新开始。让我们来看看我们的数据。这里有一堆图像和文件夹,每个文件夹名是该文件夹中图像集的标签。让我们看看这些图像在MATLAB之外是什么样子的。
这是一组从不同角度和不同光照条件下拍摄的沙丘图像,我有四辆车的一些这样的图像。在处理图像时,循环加载所有图像并跟踪所有文件、文件夹和标签可能是很痛苦的。计算机视觉系统工具箱有方便的工具,如图像集,使这一任务很容易。我只是提供了图像集与一个文件夹,其中有我所有的图像,并指示查看所有的子文件夹。Image Set的另一个重要优点是它不会将所有的图像加载到内存中,所以当你有很多很多的图像时,它很容易使用。
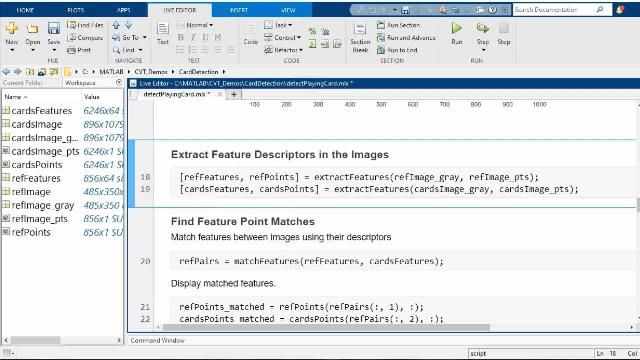
为了预处理我的数据并提取特征,我将使用一种叫做特征包的方法。这是一种相当复杂的从图像中提取特征的技术,效果非常好。如果您有兴趣了解更多关于函数的功能,计算机视觉系统工具箱文档详细说明了算法的底层功能。现在,让我们将这个函数视为一个特征提取工具,我们将使用它从图像中提取特征。
就像我们在前面的例子中所做的那样,让我们创建一个表并将标签分配给该表。让我们直接进入分类学习者,开始训练我们的模型。让我们快速看一下我们的数据。我们从图像中提取了200个新特征,最后一个变量是响应。我将再次选择holdout作为我的验证,现在我准备开始训练模型了。
我将快速训练一些模型,从最近邻和支持向量机开始。万博1manbetx现在我已经或多或少地接受了一些训练,让我们用混淆矩阵做一个快速的视觉诊断。混淆矩阵大多是对角线的,所以这是一件好事,我们将快速导出其中一个模型,看看它在真实流图像上的表现。
在运行这个函数之前,我想向您展示代码,以及实时获取流图像并对它们进行分类是多么容易。该函数有两个输入。第一个是火车模型,第二个是特征包对象,我将用它从新的图像中提取特征。
启动网络摄像头很容易。我所需要做的就是调用网络摄像头命令。在一个连续运行的循环中,首先,我从网络摄像头获取快照,然后将其转换为灰度,这意味着模型应该能够在没有颜色信息的情况下识别汽车。下一步是从新图像中提取特征,最后,使用一个预测函数和经过训练的模型,用于对新图像进行预测。让我们返回并运行此函数。
上图显示了我的网络摄像头拍摄的图像,绿色条是模型在这张图像上进行预测的结果。这是我正在使用的分类器,这个条形图显示了分类器对这辆车属于Lightning、Mater、Nigel或Sand Dune的自信程度。让我们移动相机,看看模型在不同角度和方向下的表现。
所以模型基本上得到了闪电,但当我们移动到奈杰尔,你会看到模型不是完全确定它是哪一辆车。下面的概率图显示了模型对这是哪辆车的预测有多自信。这是沙丘,最后是脱线。
让我们从Classification Learner中导出另一个模型,看看两个模型是如何并行运行的。所以我将使用线性支持向量机,并选择带有默认名称的导出。现在我的工作空间里有两个分类器,或者说两个模型。一个是资讯。另一个是支持向量机。万博1manbetx
现在让我运行这件代码,它并排比较了这两个分类器的性能。我们再次看到的是一个视频比较了两个分类器并排性能的视频。在红色左上方的左上角是我们的SVM分类器的性能,右下角是KNN分类器的性能。这里的重要信息不仅可以轻松比较和测试分类学习者的模型,而且可以很容易地将这些模型输出到Matlab并实时测试它们。
我们的演示到此结束。现在让我们回到我们的演讲。让我们再用我们熟悉的工作流图总结一下我们刚刚完成的工作。
我们的输入包括磁盘上的几个标记图像。我们使用词汇袋的方法来生成新功能。然后我们使用分类学习者应用程序来得到我们的最佳模型。对于预测步骤,我们从网络摄像头获取新的数据,对图像和新特征进行编码,并使用训练好的模型进行实时预测。
这就引出了总结和要点。为了总结到目前为止我们所看到的内容,让我回到我在本演示开始时设置的挑战。希望您今天已经看到MATLAB如何解决这些挑战。
对于数据分集的第一个挑战,我们看到Matlab如何使用不同类型的数据。MATLAB还可以访问和下载财务数据源,使用文本,地理空间数据和其他几种数据格式。MATLAB还有审查的工业标准算法和功能图书馆。MATLAB还为金融,信号处理,图像处理和其他几个提供了特定工程工作流程的额外工具。
我们还看到了如何快速构建和原型解决方案,这些解决方案与应用驱动的工作流相互作用,让你专注于机器学习,而不是万博 尤文图斯编程和调试。机器学习的最佳实践,如交叉验证和模型评估工具,被集成到应用程序和功能中。正如我们所看到的,MATLAB也有丰富的文档,其中有一些指导方针,可以帮助您选择合适的工具。最后,MATLAB本质上是一个灵活的建模环境和完整的编程语言,对您可以进行的定制分析没有任何限制。这使得MATLAB成为一个优秀的机器学习平台。
我们的演讲就到这里了,我会尽量简短一些。我想和大家分享一些关于何时应该考虑机器学习的指导方针。如果你正在处理一个手写规则和方程太复杂或无法表述的问题,可以考虑使用机器学习。或者当你的任务规则不断变化,你的程序或模型需要不断适应,因为你的任务是一个移动的目标。或者当数据的性质发生变化时,程序需要不断适应。
希望,我已经能够说服你们MATLAB是一个强大的平台对于机器学习工作流的每一步。我们一直有兴趣听取您的意见,您可以在统计和机器学习工具箱产品页面找到我的联系信息。如果您有兴趣了解更多,请查看产品文档。这里有大量的示例和概念页面,不仅可以帮助您入门,还可以指导您掌握这些工具。
如需了解更多与机器学习相关的算法、应用领域、示例和网络研讨会,请访问机器学习页面。这是我们这一届会议的结束。谢谢大家的聆听。