清理表中杂乱和丢失的数据
当表很乱并且缺少数据值时,可以用几种方法清理表。首先,可以使用Import Tool或总结和ismissing功能。标识缺少的值之后,可以使用standardizeMissing,fillmissing,或rmmissing功能。然后,您可以通过重新组织来进一步清理您的表。可以使用函数sortrows或movevars函数以适合您的顺序重新排列表行和变量。
检查文件中的数据
检查示例逗号分隔值(CSV)文件中的数据,messy.csv.检查数据的一种方法是使用Import Tool。它可以预览数据,并允许您指定如何导入数据。导入工具显示了这一点messy.csv有五列。有些列有文本,而其他列有数值。
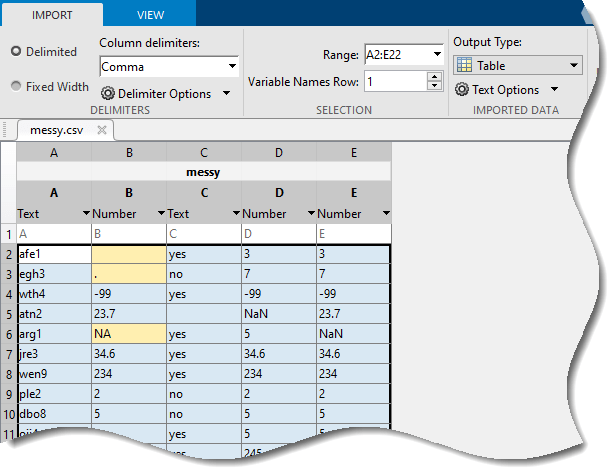
该文件包含许多不同的缺失数据指示器:
空的文本
句点(.)
NA南-99年
导入工具自动识别一些缺失的数据指示器,例如南在数字列和文本列中的空文本中。
该工具还突出显示其他指标,如空白文本、句点和NA在列中出现B.这些值不是标准的缺失值。但是作为数值列中的非数值值,它们很可能表示缺失的值。当您导入数据时,您可以指定这些值也应该像它们一样被处理南年代。
的价值-99年也可以认为是表示缺失值。当数值数据由正数值组成时,有些人有时会指定一个负数作为缺失数据的标志。若有数字如-99年表示表中缺失数据,则在清理表时必须指定它为缺失值。
以表格形式导入数据
您可以将数据从导入工具导入到MATLAB®工作区。但是你也可以用readtable函数从文件中读取数据并将其作为表导入。
将数据导入messy.csv使用readtable函数。若要将文本数据读入字符串数组的表变量,请使用“TextType”名称-值参数。若要将数值列中的指定非数值值视为缺失值,请使用“TreatAsMissing”名称-值参数。在表变量中B,D,E,readtable导入空文本,.,NA作为南值。然而,这些值-99年保持不变,因为它们是数字的。
同时,readtable对待一个和C为文本。因此,它将这些列中的空文本转换为缺失的字符串,显示为< >失踪.
messyTable =可读表(“messy.csv”,“TextType”,“字符串”,“TreatAsMissing”,[“。”,“NA”])
messyTable =21日×5表A B C D E ______ ____ _________ ____ ____ " afe1“NaN”是的“3 3”egh3“NaN”没有“7 7”wth4“-99”是的“-99 -99”atn2“23.7 <失踪>南23.7”__arg1“NaN”是的“5南”jre3“34.6”是的“34.6 - 34.6”wen9“234”是的“234 234”ple2“2”没有“2 2”dbo8“5”没有“5 5”oii4“5”是的“5 5”wnk3“245”是的“245 245”abk6“563”没有“563 563”pnj5“463”没有“463 463”wnn3“6”没有“6 6”oks9“23”是的“23日23”wba3“14”是的”14日14⋮
查看表摘要
要查看表的摘要,请使用总结函数。对于每个表变量,它显示了数据类型和其他描述性统计信息。例如,总结的每个数值变量中缺少值的数目messyTable.
总结(messyTable)
变量:A: 21x1 string B: 21x1 double值:Min -99 Median 22.5 Max 563 NumMissing 3 C: 21x1 string D: 21x1 double值:Min -99 Median 14 Max 563 NumMissing 2 E: 21x1 double值:Min -99 Median 21.5 Max 563 NumMissing 1
查找缺少值的行
求的行数messyTable的值,则使用ismissing函数。如果数据中有非标准的缺失值,例如-99年,您可以指定它以及标准缺失值。
的输出ismissing的元素是否为逻辑数组messyTable有缺失值的。
missingElements = ismissing(messyTable,{string(missing),NaN,-99})
missingElements =21x5逻辑阵列0 1 0 0 0 0 0 0 0 0 1 0 1 1 0 0 1 1 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0⋮
若要创建标识缺少值的行的逻辑向量,请使用任何函数。
rowsWithMissingValues = any(missingElements,2)
rowsWithMissingValues =21x1逻辑阵列1 1 1 1 1 0 0 0 0 0
若要在表中建立索引并只返回缺少值的行,请使用逻辑向量rowsWithMissingValues.
missingValuesTable = messyTable(rowsWithMissingValues,:)
missingValuesTable =6×5表A B C D E ______ ____ _________ ___ ____ " afe1“NaN”是的“3 3”egh3“NaN”没有“7 7”wth4“-99”是的“-99 -99”atn2“23.7 <失踪>南23.7”__arg1“NaN”是的“5南”gry5“21”是的“南21
填补缺失值
清除表中缺失值的一种策略是用更有意义的值替换它们。可以通过插入标准缺失值来替换非标准缺失值。你可以用调整后的值来填充缺失的值。例如,您可以用它们最近的邻居或表变量的平均值来填充缺失的值。
在这个例子中,-99年用于指示缺少值的非标准值。的实例替换-99年对于标准缺失值,使用standardizeMissing函数。南是单精度和双精度浮点数字数组的标准缺失值。
messyTable =标准化(messyTable,-99)
messyTable =21日×5表A B C D E ______ ____ _________ ____ ____ " afe1“NaN”是的“3 3”egh3“NaN”没有“7 7”wth4“NaN”是的“南南”atn2“23.7 <失踪>南23.7”__arg1“NaN”是的“5南”jre3“34.6”是的“34.6 - 34.6”wen9“234”是的“234 234”ple2“2”没有“2 2”dbo8“5”没有“5 5”oii4“5”是的“5 5”wnk3“245”是的“245 245”abk6“563”没有“563 563”pnj5“463”没有“463 463”wnn3“6”没有“6 6”oks9“23”是的“23日23”wba3“14”是的”14日14⋮
若要填充缺失的值,请使用fillmissing函数。它提供了许多方法来填充缺失的值。例如,返回一个新表,filledTable,其中您用它们最近的邻居来填充缺失值。
filledTable = fillmissing(messyTable,“最近的”)
filledTable =21日×5表A B C D E ______ ____ _____ ____ ____ " afe1“23.7”是的“3 3”egh3“23.7”没有“7 7”wth4“23.7”是的“7 23.7”atn2“23.7”是的“5 23.7”__arg1“34.6”是的“5 34.6”jre3“34.6”是的“34.6 - 34.6”wen9“234”是的“234 234”ple2“2”没有“2 2”dbo8“5”没有“5 5”oii4“5”是的“5 5”wnk3“245”是的“245 245”abk6“563”没有“563 563”pnj5“463”没有“463 463”wnn3“6”没有“6 6”oks9“23”是的“23日23”wba3“14”是的”14日14⋮
删除缺少值的行
清除表中缺失值的另一种策略是删除包含这些值的行。
要删除缺少值的行,请使用rmmissing函数。
remainingTable = rmmissing(messyTable)
remainingTable =15×5表A B C D E ______ ____ _____ ____ ____ " jre3“34.6”是的“34.6 - 34.6”wen9“234”是的“234 234”ple2“2”没有“2 2”dbo8“5”没有“5 5”oii4“5”是的“5 5”wnk3“245”是的“245 245”abk6“563”没有“563 563”pnj5“463”没有“463 463”wnn3“6”没有“6 6”oks9“23”是的“23日23”wba3“14”是的“14 14”pkn4“2”没有“2 2”adw3“22”没有“22 22”poj2“34.6”是的“34.6 - 34.6”bas8“23”不”23日23
对表行进行排序
一旦你清理了一张桌子,你可以用其他方式整理它。例如,您可以根据一个或多个变量中的值对表的行进行排序。
根据第一个变量的值对行进行排序,一个.
sortedTable = sortrows(remainingTable)
sortedTable =15×5表A B C D E ______ ____ _____ ____ ____ " abk6“563”没有“563 563”adw3“22”没有“22 22”bas8“23”没有“23日23”dbo8“5”没有“5 5”jre3“34.6”是的“34.6 - 34.6”oii4“5”是的“5 5”oks9“23”是的“23日23”pkn4“2”没有“2 2”ple2“2”没有“2 2”pnj5“463”没有“463 463”poj2“34.6”是的“34.6 - 34.6”wba3“14”是的“14 14”wen9“234”是的“234 234”wnk3“245”是的“245 245”wnn3“6”没有“6 6
按降序对行排序C,然后按升序排序一个.
sortedBy2Vars = sortrows(remainingTable,[“C”,“一个”]、[“下”,“提升”])
sortedBy2Vars =15×5表A B C D E ______ ____ _____ ____ ____ " jre3“34.6”是的“34.6 - 34.6”oii4“5”是的“5 5”oks9“23”是的“23日23”poj2“34.6”是的“34.6 - 34.6”wba3“14”是的“14 14”wen9“234”是的“234 234”wnk3“245”是的“245 245”abk6“563”没有“563 563”adw3“22”没有“22 22”bas8“23”没有“23日23”dbo8“5”没有“5 5”pkn4“2”没有“2 2”ple2“2”没有“2 2”pnj5“463”没有“463 463”wnn3“6”没有“6 6
排序的C时,行先按“是的”,然后是“不”.然后按一个,行按字母顺序排列。
重新排序表,以便一个和C是相邻的,用的是什么movevars函数。
sortedRowsAndMovedVars = movevars(sortedBy2Vars,“C”,“后”,“一个”)
sortedRowsAndMovedVars =15×5表一个C B D E ______ _____ ____ ____ ____ " jre3”“是的”34.6 34.6 34.6“oii4”“是的”5 5 5“oks9”“是的”23日23日23“poj2”“是的“34.6 34.6 34.6”wba3”“是的”14十四14“wen9”“是的“234 234 234”wnk3”“是的“245 245 245”abk6”“不“563 563 563”adw3”“不”22 22 22“bas8”“不”23日23日23“dbo8”“不“5 5 5”pkn4”“不“2 2 2”ple2”“不“2 2 2”pnj5”“不“463 463 463”wnn3 6 6 6”“不”
另请参阅
表格|ismissing|standardizeMissing|fillmissing|rmmissing|sortrows|movevars|导入工具|readtable|总结
相关的话题
您也可以从以下列表中选择一个网站: