机器学习模型通常被称为“黑盒子”,因为它们对知识的表示不是直观的,因此很难理解它们是如何工作的。可解释性是指克服大多数机器学习算法的黑箱特性的技术。
通过揭示不同的特征如何有助于(或不有助于)预测,您可以验证模型为其预测使用了正确的证据,并发现在训练期间不明显的模型偏差。一些机器学习模型,如线性回归、决策树和生成相加模型,具有内在的可解释性。然而,可解释性往往是以预测能力和准确性为代价的(图1)。

图1:模型性能和可解释性之间的权衡。
应用可解释性
实践者寻求模型可解释性主要有三个原因:
- 调试:理解预测出错的原因和原因,并运行“假设”场景,可以提高模型的稳健性并消除偏差。
- 指南:“黑盒”模型违背了许多公司技术最佳实践和个人偏好。
- 规定:为符合政府对金融、公共卫生和交通等敏感应用的规定,需要模型可解释性。
模型可解释性解决了这些问题,并在预测解释很重要或法规要求的情况下增加了对模型的信任。
可解释性可以应用于以下三个层次,如图2所示。
- 的地方:解释个人预测背后的因素,比如贷款申请被拒绝的原因
- 队列:演示模型如何在训练或测试数据集中对特定人群或组进行预测,例如为什么一组制造的产品被归类为错误产品s manbetx 845
- 全球:了解机器学习模型如何在整个训练或测试数据集上工作,比如对放射图像进行分类的模型会考虑哪些因素

图2:模型可解释性的用例。
在MATLAB中使用可解释性技术
使用MATLAB®机器学习,你可以应用技术来解释和解释最流行的、高度精确的机器学习模型,这些模型本质上是无法解释的。
本地可解释的模型不可知解释(LIME):用一个简单的可解释模型(如线性模型或决策树)在感兴趣的预测附近近似一个复杂模型,并使用它作为代理来解释原始(复杂)模型是如何工作的。下面的图3说明了应用LIME的三个主要步骤。
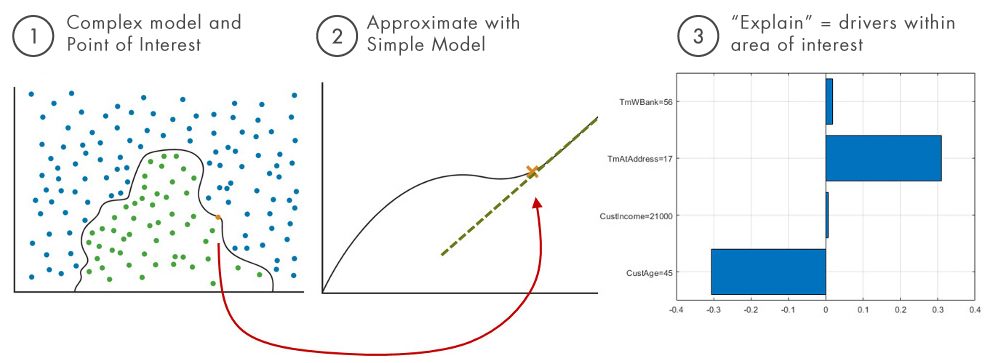
图3:通过合适的一个石灰对象,一个简单的可解释模型,可以在MATLAB中获得LIME解释。
部分依赖(PDP)和个人条件期望(ICE)图:通过在所有可能的特征值上平均模型的输出,检验一个或两个预测器对整体预测的影响。下面的图4显示了用MATLAB函数生成的部分依赖图plotPartialDependence.

图4:部分相关图,显示x1是否高于或低于3000,这对预测有很大的影响,因此,模型的可解释性。
沙普利值:通过计算兴趣预测的偏离平均值,解释每个预测器对预测的贡献。这种方法在金融行业很受欢迎,因为它源于博弈论,满足了提供完整解释的监管要求:所有特征的Shapley值之和对应于预测的总偏离平均值。的MATLAB函数沙普利计算感兴趣的查询点的Shapley值。

图5:Shapley值表明每个预测器在感兴趣点偏离平均预测的程度。
评估所有特征的组合通常需要很长时间。因此在实践中,Shapley值通常是通过应用来近似的蒙特卡罗模拟.
MATLAB还支持随机森万博1manbetx林的排列预测器重要性,其中l在测试或训练数据集上查找模型预测错误,并洗选一个预测器的值,并估计从洗选预测器的值对应于预测器的重要性的误差变化的幅度。
可解释性方法的选择
图6概述了内在可解释的机器学习、各种(与模型无关的)可解释方法,以及何时应用它们的指导。

图6:如何选择合适的解释方法。
可解释性方法有其自身的局限性。最佳实践是,当您将这些算法应用于不同的用例时,要意识到这些限制。可解释性工具帮助你理解为什么机器学习模型会做出这样的预测,这是验证和验证人工智能应用的关键部分。认证机构目前正在制定一个框架,对自动交通和医疗等敏感应用的人工智能进行认证。