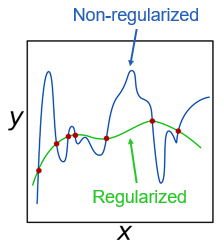
正则化技术被用来防止过度拟合统计的预测模型。正则化算法通常通过施加或者用于复杂点球如通过将模型的系数为最小化或包括粗糙惩罚工作。通过引入更多的信息到模型中,正则算法可以通过使模型更简洁,准确地处理多重和冗余的预测。
流行的正则化技术包括脊回归(也称为Tikhonov正规化),套索和弹性净算法,缩小质心的方法,以及跟踪图和交叉验证均方误差。您也可以将Akaike信息标准(AIC)应用为适合度量的公制。
每个正则化技术为某些用例提供优势。
- 套索使用L1规范,倾向于完全强制各个系数值朝向零。因此,套索工作得很好,作为特征选择算法。它很快识别少数键变量。
- Ridge回归使用L2标准为系数(您最小化平方误差的总和)。脊回归倾向于在较大数量的系数上扩散系数收缩。如果您认为您的模型应该包含大量系数,则Ridge回归可能是一种很好的技术。
- 弹性网可以弥补套索无法识别额外的预测因子。
正规化与之相关功能选择因为它迫使模型使用较少的预测。正则化方法具有一些独特的优势。
- 正则化技术能够比大多数特征选择方法更大的数据集上操作(除了单变量特征选择)。套索和岭回归可以应用到数据集包含数千个,甚至数万个,变数。
- 正则化算法通常产生更准确的预测模型比特征选择。正则化而特征选择工作在离散空间工作在连续空间。其结果是,正则往往能够微调模型,并产生更准确的估计。
但是,特征选择方法也有优势:
- 特征选择有点直观,更容易向第三方解释。当您在分享结果时必须描述您的方法时,这是有价值的。
- 马铃薯®和统计和机器学习工具箱™万博1manbetx支持所有流行的正则化技术,可用于线性回归,逻辑回归,支持向量机和线性判别分析。如果您正在使用其他模型类型,如提升决策树,则需要应用功能选择。
关键点
- 正则使用(旁边特征选择),以防止过度拟合统计的预测模型。
- 由于正则化在连续空间上运行,因此可以优于机器学习问题的离散特征选择,从而为各种线性建模提供。